
{kind=link}
Diffusion-based text-to-image fashions have made nice strides at synthesizing photorealistic content material from textual content prompts, with implications for a lot of totally different areas of research, together with however not restricted to: content material creation; picture modifying and in-painting; super-resolution; video synthesis; and 3D belongings manufacturing. Nevertheless, these fashions want a variety of computing energy, therefore high-end GPU-equipped inference platforms on the cloud are normally required. The transmission of private images, movies, and prompts to a third-party supplier, not solely incurs appreciable prices, but additionally poses critical privateness issues.
The inference of text-to-image diffusion fashions has been optimized for velocity on cell units utilizing methods together with quantization and GPU-aware optimization. Sadly, these methods haven’t but lowered latency to a degree that facilitates a wonderful person expertise. As well as, no earlier analysis has quantitatively explored the era high quality of on-device fashions.
On this paper, the authors present the primary text-to-image diffusion mannequin that may generate a picture in lower than 2 seconds on cell units. The sluggish inference velocity of the UNet is being addressed, as is the necessity for thus many denoising processes.
Latent diffusion mannequin/ Steady diffusion mannequin
Diffusion fashions are complicated and computationally intensive, which has sparked analysis into methods to optimize their effectivity, akin to enhancing the sampling course of and looking out into on-device options.
The Latent Diffusion Mannequin (LDM) is a diffusion mannequin that can be utilized to transform textual content to a picture. Excessive-quality photos are generated in response to textual prompts, making this a potent content material creation device.
The Steady Diffusion mannequin, particularly model 1. 5, is used as the start line on this research. It is a fashionable mannequin for producing photos from textual content prompts. The rationale it is so fashionable is as a result of it may make some actually spectacular, high-quality photos. However there is a catch – you want some critical computing energy to run it easily. That’s due to how the mannequin works. It goes by means of plenty of repetitive steps to refine the picture which takes up a ton of processing energy. The mannequin consists of a Textual content Encoder, UNet, and VAE Decoder. It additionally has a loopy quantity of parameters, so it is tremendous computationally intensive to run. This implies you realistically want an costly GPU to make use of it. Making an attempt to run it on one thing like a cellphone could be too sluggish to be usable.
Structure Optimizations
The authors introduce a brand new method for optimizing the structure of the UNet mannequin, which is a serious limitation of the conditional diffusion mannequin. They determine redundant components of the unique mannequin and cut back the picture decoder’s computation by means of knowledge distillation.
They suggest a extra environment friendly UNet by breaking down the networks at a granular degree, offering the premise for redesigning and optimizing the structure. Evaluating latency between Steady Diffusion v1. 5 and their proposed environment friendly diffusion fashions (UNet and Picture Decoder) on an iPhone 14 Professional reveals that, Steady Diffusion v1. 5 has greater latency and extra parameters versus their fashions.
The authors additionally current an structure optimization algorithm. This algorithm ensures that the optimized UNet mannequin converges and meets the latency goal. The algorithm performs sturdy coaching and evaluates every block within the mannequin. If structure evolution is required in some unspecified time in the future, it assesses the change in CLIP rating for every block to information the method.
In addition they introduce a coaching augmentation to make the community sturdy to structure permutations, enabling an correct evaluation of every block and a steady architectural evolution.
Algorithm for Optimizing UNet Structure: Some explanations
The algorithm requires UNet structure, a validation set (Dval), and a desk for lookup latency(T) with Cross-Consideration and ResNet timings. The objective is getting the UNet to converge whereas assembly the latency goal S.

- It makes use of sturdy coaching to optimize the structure. If this iteration contains structure evolution, the blocks get evaluated. For every block[i j], it calculates the change in rating (∆CLIP) and latency (∆Latency) utilizing the present structure (ˆεθ), A-block[i,j] Dval or T.
- It kinds the actions by ∆CLIP and ∆Latency after which, it evolves the structure to attempt to get the suitable latency T. If T shouldn’t be glad, it finds the minimal values of ∆CLIP and ∆Latency and evolves the structure to get { ˆA-}.
- If T is glad, it takes the utmost of ∆CLIP and ∆Latency and copies it to get { ˆA+}. Lastly, it evolves the structure utilizing { ˆA} to replace ˆεθ.
Step distillation
Step distillation appears like a elaborate method utilized by the authors to enhance the educational goal throughout the coaching of the text-to-image diffusion mannequin. It includes distilling data from a instructor mannequin to a scholar mannequin in a step-wise method.
The authors examine a few totally different flavors of step distillation: progressive distillation and direct distillation. Progressive distillation has the instructor mannequin spoon-feeding data to the scholar mannequin in a number of steps, whereas direct distillation simply does it in a single step. Seems direct distillation whips progressive distillation’s behind when it comes to each the FID (Fréchet Inception Distance) doodad and the CLIP rating.
Overview of distillation pipeline
The time period “Distillation Pipeline” refers to a strategy of compressing and optimizing a big and complicated machine studying mannequin right into a smaller and easier one.
- Step Distillation on SD-v1.5: Step one is to carry out step distillation on SD-v1.5, which is a mannequin used as a instructor mannequin. This step goals to acquire a UNet mannequin with 16 steps that matches the efficiency of the 50-step mannequin.
- Step Distillation on Environment friendly UNet: As soon as we have that 16-step UNet, we use it as the brand new instructor to coach up an environment friendly 8-step UNet. So, we go from the 50-step mannequin to a medium 16-step one and at last distill it right down to a easy 8-step mannequin. The hot button is utilizing these intermediate fashions as academics – their data will get distilled down into the smaller variations.
- CFG Guided Distillation: The paper additionally introduces a CFG (Context-Free Grammar)-aware step distillation method, which additional improves the efficiency of the scholar mannequin. This method throws in some extra regularization together with losses from v-prediction and classifier-free steerage. The CFG-aware step distillation constantly boosts the CLIP rating of the scholar mannequin with totally different configurations.
Ablation Evaluation
The Determine beneath reveals the outcomes of ablation research in step distillation, which is a course of of coaching a smaller neural community (scholar mannequin) to imitate the conduct of a bigger neural community (instructor mannequin).
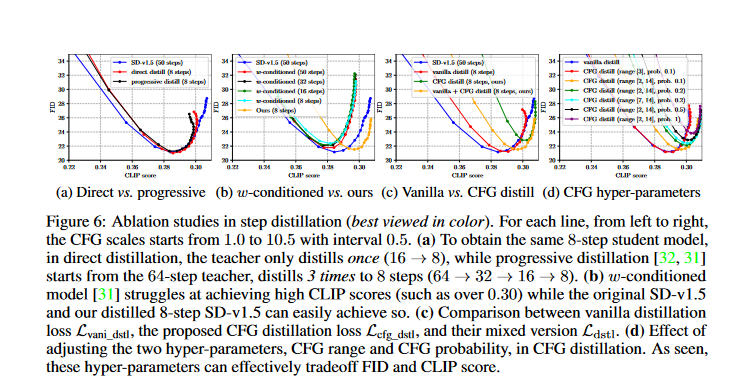
- Every line within the determine reveals a special approach of establishing the distillation course of. The settings for the hyper-parameters begin at 1. 0 and go as much as 10. 5, rising by 0. 5 every time.
- Half (a) compares two strategies for attending to 8-step scholar mannequin: direct distillation versus progressive distillation. The outcomes present that progressive distillation works higher.
- Half (b) appears at how properly a w-conditioned mannequin does, in comparison with the unique SD-v1. 5 and the distilled 8-step SD-v1. 5 fashions at getting excessive CLIP scores. The w-conditioned mannequin struggles to realize excessive CLIP scores, whereas the opposite two fashions can simply obtain them.
- Half(c) compares the efficiency of vanilla distillation loss (Lvani_dstl) versus the proposed CFG distillation loss (Lcfg_dstl) and their combine model(Ldstl). The outcomes present that the blended model achieves a greater tradeoff between FID and CLIP rating.
- Half (d) reveals easy methods to optimize the 2 settings for CFG distillation – CFG vary and CFG chance . It appears like greater CFG chance and larger CFG vary will increase the CFG loss’s affect, that result in higher CLIP rating however makes the FID worse. So these settings give a great way to steadiness FID and CLIP rating throughout coaching.
Purposes within the trade
Actual-time picture era:Actual-time picture era is an enormous deal lately. That new SnapFusion diffusion mannequin can whip up fairly photos from just some phrases of textual content in two seconds flat. It is all optimized to work that quick on cell units. May very well be a recreation altering for social media, chatbots, digital assistants – something that wants fast customized photos on the fly.
On-device answers: The analysis explores on-device picture era, which is especially helpful in situations the place web connectivity is proscribed or privateness issues limit cloud-based picture era. This makes the proposed text-to-image diffusion mannequin relevant in industries that require offline or privacy-preserving picture synthesis.
Cellular purposes and improved person expertise: Past social media and all that, there is a ton of industries and purposes that may profit from quick on-device picture era: promoting, e-commerce, leisure, augmented actuality, digital actuality – the chances are limitless. Any app that recommends personalised content material or tells interactive tales may very well be leveled up with this tech.
Some potential limitations
- The paper talks a couple of new solution to run text-to-image diffusion fashions on cell units, so that they take lower than 2 seconds. That is cool, however, we’re not positive how properly it will carry out on totally different several types of cell units, particularly older or much less highly effective ones.
- It appears that evidently the authors solely carried out experiments on the MS-COCO dataset. Subsequently, the robustness and generalizability of the mannequin to different datasets or real-world situations are unknown.
- The authors state that the mannequin will get higher FID and CLIP scores than Steady Diffusion 1. 5 with fewer denoising steps. However how does it stack up in opposition to different fashions on the market? It might be good to match it to others fashions in numerous conditions.
- One factor they do not point out is privateness when working this on mobiles units. They state that, it avoids privateness points with cloud computing, however do not clarify how they managed or protected person knowledge of their proposed mannequin. That is an essential factor to deal with.
Some steps to use the paper
To use the SnapFusion text-to-image diffusion mannequin, you’ll be able to comply with these steps:
- Set up the required dependencies and libraries for text-to-image synthesis, akin to PyTorch and torchvision.
- To organize your textual content prompts or captions for additional evaluation, it’s essential to carry out preprocessing steps. These steps embody tokenizing the textual content, which suggests breaking it down into particular person phrases or subwords, after which translating them into numerical representations. This can be achieved by methods like phrase embeddings, which map phrases to dense vectors in a steady area, or one-hot encodings, which characterize phrases as binary vectors.
- Load the pre-trained SnapFusion mannequin weights and structure, which could be obtained from the authors.
- Use the textual content prompts to feed into the SnapFusion mannequin’s enter layer and begin producing photos by means of the text-to-image diffusion course of. The mannequin will generate photos that correspond to the offered textual content prompts in mere seconds.
- Apply any crucial post-processing duties on the generated photos, like resizing or making use of additional picture refinement strategies if wanted.
- Show or save the generated photos for additional evaluation or use in your utility.
Conclusion
The authors did an incredible job displaying a brand new solution to run text-to-image diffusion fashions on moble units in beneath two seconds. That is loopy quick, contemplating how a lot quantity crunching these fashions normally want and the way sluggish they usually are. They got here up with an environment friendly UNet structure by figuring out redundancies within the authentic mannequin and simplifying the computation of the picture decoder utilizing knowledge distillation. In addition they improved the step distillation course of by attempting new coaching methods and including regularization from classifier-free steerage.
The authors examined the crap out of their mannequin on the MS-COCO dataset. The mannequin with solely 8 denoising steps carried out higher on FID and CLIP scores in comparison with the Steady Diffusion v1. 5 mannequin with 50 steps. Lastly, they argue that, their work makes creating content material extra accessible to customers by making highly effective text-to-image diffusion fashions work on regular cell units with out requiring costly GPUs or cloud providers. This additionally reduces privateness points related to sending person knowledge to outdoors firms.
Reference
SnapFusion: Textual content-to-Picture Diffusion Mannequin on Cellular Gadgets inside Two Seconds
Textual content-to-image diffusion fashions can create gorgeous photos from pure language descriptions that rival the work {of professional} artists and photographers. Nevertheless, these fashions are giant, with complicated community architectures and tens of denoising iterations, making them computationally costly and…
