
{kind=link}
Introduction
In right this moment’s enterprise world, buyer care service performs an necessary position in guaranteeing loyalty and buyer satisfaction. Understanding and analyzing the feelings expressed throughout interactions might help improve the standard of buyer care. Sentiment evaluation on buyer care audio knowledge acts as a strong device for reaching this purpose. On this complete information, we’ll discover the complexities of conducting sentiment evaluation on buyer care audio recordings, offering an in depth roadmap for implementation.

Studying Targets
- Be taught to construct a Flask internet utility that makes use of AWS.
- Be taught the process of conducting sentiment evaluation.
- Be taught the calculations concerned in sentiment evaluation.
- Perceive the best way to extract the required knowledge and acquire insights from this evaluation.
This text was revealed as part of the Knowledge Science Blogathon.
Process of Performing Sentiment Evaluation
Stage 1: Making ready the Knowledge
Understanding the Activity: To carry out sentiment evaluation on the shopper care audios out there and supply insights from the outcomes.
Making a Flask Utility: Constructing a Flask internet utility that makes use of Amazon Internet Companies (AWS) comprehend to do evaluation. This utility is the muse for our undertaking.
Importing Audio Recordings: The decision recording needs to be saved in a database like an AWS S3 bucket to begin the evaluation.
Creating Consumer Interface: Making a user-friendly interface may be very essential. That is achieved utilizing CSS, HTML, and JavaScript. This interface helps customers to pick names, dates, and occasions.
Getting the Inputs: Consumer inputs like Names, Starting Date and Time, and Finish Date and Time are captured to customise the evaluation course of.
Fetching Recordings: Steering to fetch recordings from the S3 bucket inside the chosen time interval is given.
Audio Transcription: The center of sentiment evaluation lies within the transcribed textual content. This part explores how AWS Transcribe converts spoken phrases from the out there recordings into textual content for
evaluation.
Stage 2: Analyzing the Knowledge
Performing Sentiment Evaluation: Analyzing the transcribed textual content is necessary for this information. Step one of this part is to divide giant volumes of textual content into manageable chunks. The subsequent step is to carry out sentiment evaluation on every chunk.
Calculating Sentiment Metrics: The subsequent is to derive significant insights. We’ll calculate the common of all sentiment scores and calculate the Web Promoter Rating (NPS). NPS is a essential metric that quantifies buyer or worker loyalty. The components for NPS is as follows:
NPS = ((Whole Positives / Whole
Data) – (Whole Negatives / Whole Data)) * 100
Creating Pattern Charts: This helps to Perceive traits over time. We’ll information you to create visible pattern charts that illustrate the progress of sentiment scores. These charts will cowl optimistic, unfavourable,
combined, and impartial values and NPS.
End result Web page: On the closing step of our evaluation, we’ll create a consequence web page that showcases the results of our evaluation. This web page will current a report on sentiment metrics, pattern charts, and actionable insights
drawn from buyer care interactions.
Now let’s start our sentiment evaluation, following the above process.
Importing Obligatory Libraries
On this part, we import important Python libraries which are basic to constructing our Flask utility, interacting with AWS companies, and performing varied different duties.
from flask import Flask, render_template, request
import boto3
import json
import time
import urllib.request
import requests
import os
import pymysql
import re
import sys
import uuid
from datetime import datetime
import json
import csv
from io import StringIO
import urllibImporting Audio Recordings
Earlier than beginning our name recording evaluation, the recordings have to be simply accessible. Storing the recordings in areas resembling an AWS S3 bucket helps in simple retrieval. On this examine, we now have uploaded the
worker and buyer recordings as separate recordings in a single folder.
Creating Consumer Interface
Utilizing CSS, HTML, and JavaScript, a visually interesting consumer interface is created for this utility. This helps the consumer to pick inputs resembling Names and dates from the offered widgets.
Getting the Inputs
We use our Flask utility to get data from the consumer. To do that, we use the POST methodology to collect particulars like worker names and date ranges. We will then analyze the feelings of each the worker and the shopper. In our demonstration, we’re utilizing the worker’s name recordings for evaluation. We will additionally use the decision recordings of the shoppers who work together with the worker as an alternative of the worker’s calls.
We will use the next code for this.
@app.route('/fetch_data', strategies=['POST'])
def fetch_data():
title = request.type.get('title')
begin_date = request.type.get('begin_date')
begin_time = request.type.get('begin_time')
begin_datetime_str = f"{begin_date}T{begin_time}.000Z"
print('Start time:',begin_datetime_str)
end_date = request.type.get('end_date')
end_time = request.type.get('end_time')
end_datetime_str = f"{end_date}T{end_time}.000Z"Fetching Recordings
To start our evaluation, we have to get the audio recordings from their saved location. Whether or not they’re in an AWS S3 bucket or another database, we now have to observe sure steps to get these recordings, particularly for a selected time interval. We should always be sure we offer the proper folders containing the recordings of workers or clients.
This instance reveals the best way to get recordings from an S3 bucket.
# Initialize the S3 consumer
s3 = boto3.consumer('s3')
# Specify the S3 bucket title and the prefix (listing) the place your recordings are saved
bucket_name="your-s3-bucket-name"
prefix = 'recordings/'
strive:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
# Iterate by means of the objects and fetch them
for obj in response.get('Contents', []):
# Get the important thing (object path)
key = obj['Key']
# Obtain the item to a neighborhood file
local_filename = key.cut up('/')[-1]
s3.download_file(bucket_name, key, local_filename)
print(f"Downloaded {key} to {local_filename}")
besides Exception as e:
print(f"An error occurred: {e}")Audio Transcription
Turning spoken phrases from audio into textual content is difficult. We use a helpful device referred to as Amazon Internet Companies (AWS) Transcribe to do that job mechanically. However earlier than that, we clear the audio knowledge by eradicating components the place nobody is speaking and altering conversations in different languages to English. Additionally, if there are a number of folks speaking in a recording, we have to separate their voices and solely concentrate on the one we wish to analyze.
Nevertheless, for the interpretation half to work, we’d like our audio recordings in a format that may be accessed by means of an internet hyperlink. The code and rationalization beneath will present
you ways this all works.
Implementation Code:
transcribe = boto3.consumer('transcribe', region_name=AWS_REGION_NAME)
def transcribe_audio(audio_uri):
job_name_suffix = str(uuid.uuid4())
# Generate a novel job title utilizing timestamp
timestamp = str(int(time.time()))
transcription_job_name = f'Transcription_{timestamp}_{job_name_suffix}'
settings = {
'ShowSpeakerLabels': True,
'MaxSpeakerLabels': 2
}
response = transcribe.start_transcription_job(
TranscriptionJobName=transcription_job_name,
LanguageCode="en-US",
Media={'MediaFileUri': audio_uri},
Settings=settings
)
transcription_job_name = response['TranscriptionJob']['TranscriptionJobName']
# Anticipate the transcription job to finish
whereas True:
response = transcribe.get_transcription_job(
TranscriptionJobName=transcription_job_name)
standing = response['TranscriptionJob']['TranscriptionJobStatus']
if standing in ['COMPLETED', 'FAILED']:
break
print("Transcription in progress...")
time.sleep(5)
transcript_text = None
if standing == 'COMPLETED':
transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri']
with urllib.request.urlopen(transcript_uri) as url:
transcript_json = json.masses(url.learn().decode())
transcript_text = transcript_json['results']['transcripts'][0]['transcript']
print("Transcription accomplished efficiently!")
print('Transribed Textual content is:', transcript_text)
else:
print("Transcription job failed.")
# Examine if there are any transcripts (if empty, skip sentiment evaluation)
if not transcript_text:
print("Transcript is empty. Skipping sentiment evaluation.")
return None
return transcript_text
Rationalization:
Job Initialization: Specify a novel title and language code (on this case, ‘en-US’ for English) to provoke an AWS Transcribe job.
Transcription Settings: We outline settings for the transcription job, together with choices to indicate speaker labels and specify the utmost variety of speaker labels (helpful for multi-speaker audio).
Begin Transcription: The job will get began utilizing the start_transcription_job methodology. It asynchronously transcribes the offered audio.
Monitor Job Progress: We periodically test the standing of the transcription job. It could possibly be in progress, accomplished, or failed. We pause and await completion earlier than continuing.
Entry Transcription Textual content: As soon as the job is accomplished efficiently, we entry the transcribed textual content from the offered transcript URI. This textual content is then out there for sentiment evaluation.
Performing Sentiment Evaluation
Sentiment evaluation is a giant deal in our evaluation work. It’s all about understanding the emotions and context within the written textual content that comes from turning audio into phrases. To deal with a lot of textual content, we break it into smaller components. Then, we use a device referred to as AWS Comprehend, which is nice at determining if the textual content sounds optimistic, unfavourable, impartial, or if it’s a mixture of these emotions.
Implementation Code:
def split_text(textual content, max_length):
# Cut up the textual content into chunks of most size
chunks = []
begin = 0
whereas begin < len(textual content):
finish = begin + max_length
chunks.append(textual content[start:end])
begin = finish
return chunks
def perform_sentiment_analysis(transcript):
transcript = str(transcript)
# Outline the utmost size for every chunk
max_chunk_length = 5000
# Cut up the lengthy textual content into smaller chunks
text_chunks = split_text(transcript, max_chunk_length)
# Carry out sentiment evaluation utilizing AWS Comprehend
comprehend = boto3.consumer('comprehend', region_name=AWS_REGION_NAME)
sentiment_results = []
confidence_scores = []
# Carry out sentiment evaluation on every chunk
for chunk in text_chunks:
response = comprehend.detect_sentiment(Textual content=chunk, LanguageCode="en")
sentiment_results.append(response['Sentiment'])
confidence_scores.append(response['SentimentScore'])
sentiment_counts = {
'POSITIVE': 0,
'NEGATIVE': 0,
'NEUTRAL': 0,
'MIXED': 0
}
# Iterate over sentiment outcomes for every chunk
for sentiment in sentiment_results:
sentiment_counts[sentiment] += 1
# Decide the bulk sentiment
aws_sentiment = max(sentiment_counts, key=sentiment_counts.get)
# Calculate common confidence scores
average_neutral_confidence = spherical(
sum(rating['Neutral'] for rating in confidence_scores) / len(confidence_scores), 4)
average_mixed_confidence = spherical(
sum(rating['Mixed'] for rating in confidence_scores) / len(confidence_scores), 4)
average_positive_confidence = spherical(
sum(rating['Positive'] for rating in confidence_scores) / len(confidence_scores), 4)
average_negative_confidence = spherical(
sum(rating['Negative'] for rating in confidence_scores) / len(confidence_scores), 4)
return {
'aws_sentiment': aws_sentiment,
'average_positive_confidence': average_positive_confidence,
'average_negative_confidence': average_negative_confidence,
'average_neutral_confidence': average_neutral_confidence,
'average_mixed_confidence': average_mixed_confidence
}Rationalization:
Breaking Down the Textual content: To deal with lots of textual content extra simply, we cut up the transcript into smaller components that we are able to handle higher. We’ll then look into these smaller components one after the other.
Understanding Feelings: We use AWS Comprehend to determine the feelings (like optimistic, unfavourable, impartial, combined) in every of those smaller components. It additionally tells us how positive it’s about these feelings.
Preserving Depend of Feelings: We observe down what number of occasions every emotion comes up in all these smaller components. This helps us know what most individuals are feeling general.
Discovering Confidence: We calculate a mean rating for the way positive AWS Comprehend is concerning the feelings it finds. This helps us see how assured the system is in its outcomes.
Calculating Sentiment Metrics
After performing sentiment evaluation on particular person chunks of textual content, we proceed to calculate significant sentiment metrics. These metrics present insights into the general sentiment and buyer or worker notion.
Implementation Code:
consequence = perform_sentiment_analysis(transcript)
def sentiment_metrics(consequence):
# Initialize variables to retailer cumulative scores
total_sentiment_value=""
total_positive_score = 0
total_negative_score = 0
total_neutral_score = 0
total_mixed_score = 0
# Counters for every sentiment class
count_positive = 0
count_negative = 0
count_neutral = 0
count_mixed = 0
# Course of the fetched knowledge and calculate metrics
for document in consequence:
sentiment_value = aws_sentiment
positive_score = average_positive_confidence
negative_score = average_negative_confidence
neutral_score = average_neutral_confidence
mixed_score = average_mixed_confidence
# Depend occurrences of every sentiment class
if sentiment_value == 'POSITIVE':
count_positive += 1
elif sentiment_value == 'NEGATIVE':
count_negative += 1
elif sentiment_value == 'NEUTRAL':
count_neutral += 1
elif sentiment_value == 'MIXED':
count_mixed += 1
# Calculate cumulative scores
total_sentiment_value = max(sentiment_value)
total_positive_score += positive_score
total_negative_score += negative_score
total_neutral_score += neutral_score
total_mixed_score += mixed_score
# Calculate averages
total_records = len(consequence)
overall_sentiment = total_sentiment_value
average_positive = total_positive_score / total_records if total_records > 0 else 0
average_negative = total_negative_score / total_records if total_records > 0 else 0
average_neutral = total_neutral_score / total_records if total_records > 0 else 0
average_mixed = total_mixed_score / total_records if total_records > 0 else 0
# Calculate NPS provided that there are data
if total_records > 0:
NPS = ((count_positive/total_records) - (count_negative/total_records)) * 100
NPS_formatted = "{:.2f}%".format(NPS)
else:
NPS_formatted = "N/A"
# Create a dictionary to retailer the calculated metrics
metrics = {
"total_records": total_records,
"overall_sentiment": overall_sentiment,
"average_positive": average_positive,
"average_negative": average_negative,
"average_neutral": average_neutral,
"average_mixed": average_mixed,
"count_positive": count_positive,
"count_negative": count_negative,
"count_neutral": count_neutral,
"count_mixed": count_mixed,
"NPS": NPS_formatted
}
return metrics
Rationalization:
Cumulative Scores: We begin by organising some variables to maintain observe of the overall scores for optimistic, unfavourable, impartial, and combined emotions. These scores will add up as we undergo all of the analyzed components.
Counting Sentiments: We maintain counting what number of occasions every sort of emotion reveals up, similar to we did after we had been determining the emotions earlier.
Discovering Averages: We work out the common scores for feelings and the general temper based mostly on what most individuals appear to be feeling. We additionally calculate one thing referred to as the Web Promoter Rating (NPS) utilizing a particular components we talked about earlier.
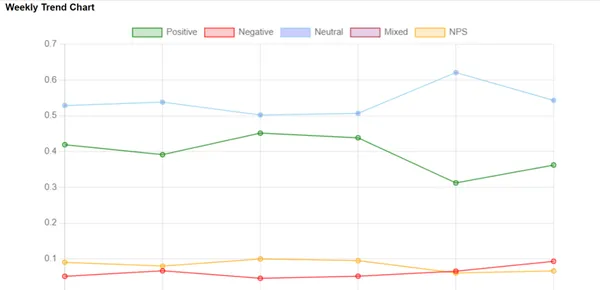
Creating Pattern Charts
To see how feelings change over time, we create pattern charts. These are like photos that visually signify whether or not feelings are rising or reducing. They assist corporations determine any patterns and use this data to make good choices based mostly on knowledge.
Process:
Knowledge Aggregation: We calculate the common sentiment scores and NPS values for every week. These values are saved in dictionary format and will likely be used to create pattern charts.
Calculating Week Quantity: For every audio recording, we decide the week by which it occurred. That is necessary for organizing knowledge into weekly traits.
Calculating Averages: We calculate the common sentiment scores and NPS values for every week. These values will likely be used to create pattern charts.
Results of the Sentiment Evaluation
After the evaluation, we are able to create the consequence web page, as proven beneath. This web page offers the general report, like the overall variety of recordings, complete name length, and so forth. Additionally, it shows charts representing the common scores and traits. We will additionally seize unfavourable scores and their particulars individually.
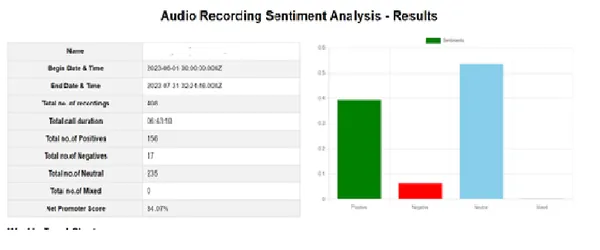
Conclusion
In right this moment’s fast-paced enterprise world, understanding what clients really feel is essential. It’s like having a secret device to make clients happier. Sentiment evaluation of audio name recordings helps to realize insights into buyer interactions. This text defined the steps of conducting sentiment evaluation, from turning audio into textual content to creating pattern charts.
First, we used instruments like AWS Transcribe to assist us convert spoken phrases from these audio transcriptions into readable textual content. The sentiment evaluation then assessed the feelings and context and categorized them as optimistic, unfavourable, impartial, or combined sentiments.
The sentiment metrics concerned aggregating scores and calculating the Web Promoter Rating (NPS), which might then be plotted on charts and graphs to determine points, monitor progress, and enhance loyalty.
Key Takeaways
- Sentiment evaluation is a strong device for companies to grasp suggestions, make enhancements, and ship buyer experiences.
- Sentiment adjustments over time might be visualized by pattern charts, serving to organizations make data-driven choices.
Steadily Requested Questions
Ans. Sentiment evaluation determines the emotional tone and context of textual content knowledge utilizing the NLP method. In buyer care, the sort of evaluation helps organizations perceive how clients really feel about their services or products. It’s essential as a result of it offers actionable insights into buyer satisfaction and permits companies to enhance their companies based mostly on buyer suggestions. It helps to see how workers are interacting with clients.
Ans. Audio transcription is the method of changing spoken phrases in audio into written textual content. In sentiment evaluation, it’s the very first thing we do. We use instruments like AWS Transcribe to vary what folks say in a name into phrases a pc can perceive. After that, we are able to take a look at the phrases to see how folks really feel.
Ans. Sentiments are often categorized into 4 most important classes: Constructive, Unfavorable, Impartial, and Blended. “Constructive” signifies a optimistic sentiment or satisfaction. “Unfavorable” displays dissatisfaction or a unfavourable sentiment. “Impartial” says lack of optimistic and unfavourable sentiment, and “Blended” means mixing up optimistic and unfavourable feelings within the textual content.
Ans. NPS is a quantity that tells us how a lot folks like an organization or service. We discover it by taking the proportion of people that prefer it (optimistic) and subtracting the proportion of people that don’t prefer it (unfavourable). The components seems like this: NPS = ((Constructive Folks / Whole Folks) – (Unfavorable Folks / Whole Folks)) * 100. The next NPS means extra blissful clients.
Ans. Pattern charts are like photos that present how folks’s emotions change over time. They assist corporations see if clients are getting happier or sadder. Firms can use pattern charts to search out patterns and see whether or not their enhancements work. Pattern charts assist corporations make good selections and might test their adjustments to make clients blissful.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.