
{kind=link}
Giant language fashions have proven promise in quite a lot of totally different software areas, together with basic drawback fixing, code era, and instruction comprehension. Versus the sooner fashions’ reliance on direct reply methods, the present physique of labor favors linear reasoning approaches by decomposing issues into sub-tasks or utilizing exterior processes to change token era. The Algorithm of Ideas (AoT) is a brand new prompting method that, with few queries, can go alongside reasoning paths in massive language fashions. The researchers introduce AoT’s structure, discover its advantages over typical prompting approaches, and emphasize its capability to inject its personal “instinct” to create efficient search outcomes.
With this in thoughts, our purpose is to dramatically cut back the question counts employed by up to date multi-query reasoning strategies whereas sustaining efficiency for duties necessitating adept use of world information, thereby steering a extra accountable and proficient use of AI sources.
Some associated works
Commonplace prompting: Widespread in massive language fashions (LLMs), normal prompting (also referred to as input-output prompting) entails offering the mannequin with a small variety of input-output examples of the duty earlier than getting a response for a take a look at pattern. This method is common and doesn’t want any explicit prompting method. Nonetheless, when in comparison with extra superior prompting approaches, the efficiency of extraordinary prompting is mostly subpar.
Chain of although prompting: In Chain of Thought, massive language fashions get proven examples the place a question x will get answered by means of a collection of intermediate reasoning steps c1, c2, c3 and so forth till it reaches the ultimate reply y. It seems like x -> c1 -> c2 -> c3 ->. . and -> cn -> y. By mimicking these examples the mannequin can break down the answer into less complicated linear steps to get higher at fixing reasoning issues.
Self-consistency (Wang et al. 2022) is a extensively used decoding technique geared toward producing a wide range of reasoning paths by selecting the ultimate reply by means of a majority vote, although this necessitates further generations.
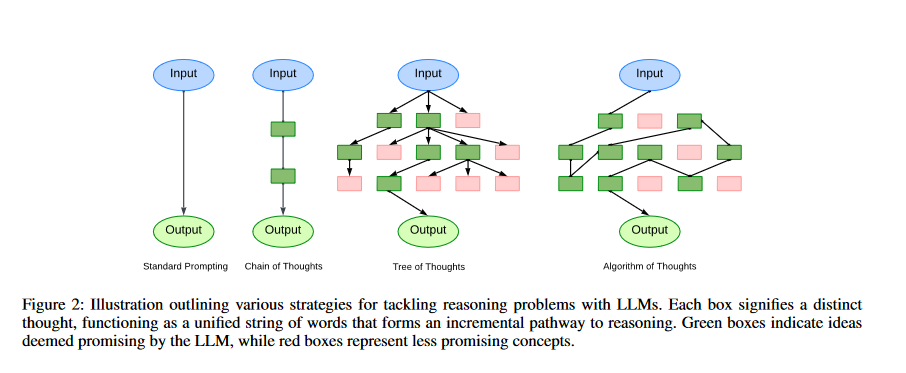
In contrast to Chain of Thought’s direct step-by-step development, the thought of our researchers seems extra at how inventive and exploratory these fashions will be. They see the c1, c2, c3 steps not as simply steps to the reply however as a mutable path like an algorithm looking round, with room to discover, alter, and transfer in nonlinear methods.
Least-to-Most prompting: By utilizing the sphere of instructional psychology (Libby et al., 2008), L2M prompting guides the LLM to interrupt down the duty at hand into extra manageable sub issues. A sequential method is used to fixing the issues, with every answer being added to the earlier one earlier than shifting on (Zhou et al. 2022; Drozdov et al. This technique of organized delineation is greatest suited to conditions with a clear-cut construction, however it has the additional benefit of aiding in additional generalization. Nonetheless, its rigidity turns into apparent when duties are intertwined with their decomposition complexities (reminiscent of in video games of 24). In distinction, AoT not solely emphasizes the present subproblem (as seen in Fig. 1). It additionally enables you to take a extra considerate method, entertaining totally different choices for every sub-problem, whereas nonetheless sustaining effectivity even with minimal prompts.

Tree of Ideas (ToT): The protection of the thought area is constrained by linear reasoning pathways from CoT or L2M in instances the place every subproblem has a number of believable prospects to discover. The choice tree will be explored utilizing exterior tree search algorithms (e.g., BFS, DFS) (Yao et al. 2023), bearing in mind potential choices for every subproblem. The analysis options of LLMs will also be used to information the search by eliminating ineffective nodes. One of many shortcomings of ToT is that it typically requires lots of of LLM searches to resolve a single drawback. The answer to this drawback is to generate the complete thought course of inside a single context.
Algorithm of Ideas
The Algorithm of Thought (AoT) is an progressive prompting method that makes use of algorithmic reasoning paths to reinforce the reasoning talents of Giant Language Fashions (LLMs). This method incorporates the methodical and ordered nature of algorithmic approaches in an effort to simulate the layered exploration of concepts seen in human considering.
As a primary step within the AoT course of, the LLM is proven algorithmic examples that characterize the complete spectrum of investigation, from brainstorming to verified outcomes. The LLM may use these examples as a roadmap for tackling complicated issues by breaking them down into smaller subproblems. The LLM makes use of algorithmic reasoning to systematically take a look at hypotheses and get the optimum answer.
The important thing power of the AoT course of lies in its capability to develop the scope of the investigation with few queries. In distinction to the a number of queries required by typical question methods, AoT requires just one or a small variety of queries to provide comparable outcomes. Because of this, computing energy and storage necessities are decreased, making this technique extra sensible and economical.
The AoT technique makes use of LLMs’ recursive nature. Because the LLM generates solutions, it refers again to earlier intermediate steps to remove implausible options and fine-tune its reasoning course of. Due to its repeated era cycle, the LLM can study from its previous errors and enhance upon its personal methods, ultimately outperforming the algorithm itself. LLMs can enhance their reasoning in lots of contexts by adopting the AoT course of. AoT is an organized and methodical technique that may assist with duties that want mathematical reasoning and logical drawback fixing. Listed below are the important thing element of the Algorithm of Ideas (AoT) method:
Decomposition into Subproblems
The Algorithm of Thought (AoT) depends closely on decomposition into smaller, extra manageable chunks. The method entails breaking down a big drawback into smaller chunks that may be tackled independently. This decomposition is vital for big language fashions (LLMs) to allow environment friendly reasoning and answer discovering.
There are a number of concerns that should be made whereas breaking down an issue. Step one is to think about the dependencies amongst particular person steps. Efficient decomposition requires an appreciation for the interdependencies between the subproblems and the contributions of their options to the entire.
Second, it is essential to consider how easy will probably be to resolve every subproblem individually. Among the subproblems could also be easy and simple to reply, whereas others might have extra nuanced reasoning or extra knowledge. The purpose of the decomposition ought to be to ensure that every of the subproblems is manageable in scope and complexity.
Proposing Options to Subproblems
Within the Algorithm of Thought (AoT) course of, the era of answer proposals for particular subproblems happens seamlessly. This steady course of presents a number of benefits. First, it reduces computational load and mannequin queries by eliminating the necessity to consider every answer individually. Moreover, it promotes environment friendly answer era. Secondly, as an alternative of repeatedly pausing and restarting the token sampling course of, the massive language mannequin (LLM) can generate full sequences of options. The possibilities of particular person tokens or token teams could not all the time precisely replicate the LLM’s capability to genetare cohesive and significant sequences, which our technique takes under consideration.
A easy illustration is present in Fig. 4. When evaluated independently, the second-most possible token for our inaugural quantity is ‘1’—not qualifying as prime. However, when era stays unbroken, the derived sequence is right.

Gauging the Promise of a Subproblem
Within the Algorithm of Thought (AoT), evaluating the potential of a subproblem is essential. It entails assessing the viability and potential of every subproblem inside the context of the general challenge area. The massive language mannequin (LLM) could effectively allocate sources by prioritizing the analysis of promising subproblems.
When figuring out a subproblem’s potential, it is essential to take note of quite a lot of components. The LLM should first decide whether or not or not the aspect challenge is essential to the principle challenge. Is the subproblem important to fixing the principle challenge ? The LLM can higher allocate its investigation time and sources by understanding the relative relevance of every subproblem.
Second, the LLM ought to decide how complicated the subproblem is. Is it a easy drawback that may be quickly addressed, or does it name for complicated evaluation and computation? The LLM can choose the perfect technique for tackling the subproblem and distribute sources accordingly after evaluating its complexity.
The LLM also needs to take into consideration the implications of resolving the subproblem. When this explicit can be resolved, will the bigger problem-solving course of will advance considerably? . The LLM can higher allocate sources and concentrate on probably the most urgent issues if it has a transparent image of the probably impact.
Backtracking to a Preferable Juncture
The Algorithm of Thought (AoT) technique permits for backtracking for use when researching potential options to subproblems. The massive language mannequin (LLM) can retrace its steps to a previous subproblem to attempt a distinct method if the present one doesn’t present fascinating outcomes. The iterative technique of going backwards and forwards between potential options can enhance the LLM’s reasoning and answer high quality.
The choice of which node to discover subsequent (together with retracing to a previous node) inherently is determined by the chosen tree-search algorithm. Some research (like Yao aet al. 2023) baked in particular guidelines to information the search, however that limits how helpful their strategies are – you gotta customise every part. Of their work, the researchers follow depth-first search with some pruning thrown in and the purpose is to have youngster nodes hold shut collectively, so the AI mannequin focuses on native options as an alternative of getting distracted by distant nodes.
Methodology and Experimental Outcomes
Varied problem-solving duties, together with the sport of 24 and mini crosswords puzzles, are used within the experiments that type the spine of the examine’s method. The authors consider AoT’s effectivity by evaluating it to these of established strategies like CoT and ToT. Based mostly on the info, it is clear that AoT is superior than conventional prompting and CoT, whereas additionally performing equally to ToT in sure instances. Along with showcasing AoT’s capabilities, the analysis reveals areas for enchancment and suggests methods wherein handbook decision will be essential to get a passable end result.
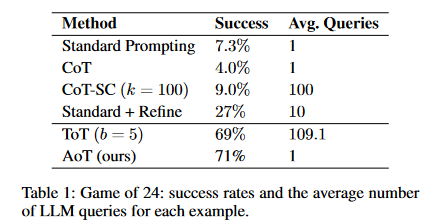
- From Desk 1, it’s evident that normal prompting mixed with CoT/-SC considerably lags behind tree search strategies when used with LLMs.
- The “Commonplace + Refine” outcome, exhibiting a 27% success charge, is referenced from (Yao et al. 2023). This technique entails iteratively asking the LLM (as much as 10 iterations) to refine its reply if the preliminary one is wrong. In the meantime, ToT is proscribed to a most of 100 node visits, translating to a number of hundred LLM queries for every instance.
- Remarkably, AoT achieves its outcomes with only a single question. Regardless of decreasing the variety of requests by greater than an element of 100, AoT nonetheless outperforms ToT on this job
Implications and Significance
There are main repercussions for enterprise and AI analysis stemming from the findings of the analysis paper. The AoT technique reveals promise as a method to enhance LLMs’ problem-solving expertise, permitting them to tackle difficult duties that require reasoning and exploration. By enhancing LLMs’ capability for generalization, AoT boosts their effectivity in duties as numerous as pure language processing, knowledge evaluation, and artistic writing. The analysis additionally emphasizes the potential of AoT in slicing down on computing bills and growing the effectiveness of LLM-based programs.
Limitations
Nonetheless, there are particular limitations to keep in mind. Whereas the publication does embrace experimental knowledge evaluating AoT with established strategies, extra analysis into a bigger pattern measurement and a wider vary of drawback domains would strengthen the case for AoT’s effectivity. The paper additionally notes that, there can be instances when AoT would require human intervention, suggesting that it could not be capable to resolve all issues by itself. Strategies to enhance AoT autonomy and cut back the necessity for human intervention could be investigated in future research.
As well as, the computational prices of implementing AoT are briefly talked about, whereas the analysis focuses largely on AoT’s efficiency in problem-solving duties. Analysis on the computational effectivity of AoT and potential enhancements to decrease useful resource necessities could be performed in mild of the rising demand for efficient AI programs.
Conclusion
The Algorithm of Ideas (AoT) technique has essential implications within the area of NLP and AI. This analysis paper present a singular method to enhance concept exploration in LLMs by combining recursive exploration with algorithmic examples. The experimental findings present that AoT is profitable in coaching LLMs to generalize throughout totally different problem-solving duties.
Reference
Algorithm of Ideas: Enhancing Exploration of Concepts in Giant Language Fashions https://arxiv.org/abs/2308.10379