
{kind=link}
LangChain is a versatile Python library that empowers builders and researchers to create, experiment with, and analyze language fashions and brokers. It gives a wealthy set of options for pure language processing (NLP) fanatics, from constructing customized fashions to manipulating textual content knowledge effectively. On this complete information, we’ll dive deep into the important elements of LangChain and reveal how one can harness its energy in Python.
Getting Set Up
To observe together with this text, create a brand new folder and set up LangChain and OpenAI utilizing pip:
pip3 set up langchain openai
Brokers
In LangChain, an Agent is an entity that may perceive and generate textual content. These brokers will be configured with particular behaviors and knowledge sources and educated to carry out varied language-related duties, making them versatile instruments for a variety of functions.
Making a LangChain agent
Brokers will be configured to make use of “instruments” to assemble the info they want and formulate a great response. Check out the instance under. It makes use of Serp API (an web search API) to look the Web for data related to the query or enter, and makes use of that to make a response. It additionally makes use of the llm-math device to carry out mathematical operations — for instance, to transform items or discover the share change between two values:
from langchain.brokers import load_tools
from langchain.brokers import initialize_agent
from langchain.brokers import AgentType
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
os.environ["SERPAPI_API_KEY"] = "YOUR_SERP_API_KEY"
OpenAI.api_key = "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"
llm = OpenAI(mannequin="gpt-3.5-turbo", temperature=0)
instruments = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(instruments, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("How a lot power did wind generators produce worldwide in 2022?")
As you may see, after doing all the fundamental importing and initializing our LLM (llm = OpenAI(mannequin="gpt-3.5-turbo", temperature=0)), the code masses the instruments needed for our agent to work utilizing instruments = load_tools(["serpapi", "llm-math"], llm=llm). It then creates the agent utilizing the initialize_agent operate, giving it the desired instruments, and it provides it the ZERO_SHOT_REACT_DESCRIPTION description, which implies that it’ll don’t have any reminiscence of earlier questions.
Agent take a look at instance 1
Let’s take a look at this agent with the next enter:
"How a lot power did wind generators produce worldwide in 2022?"
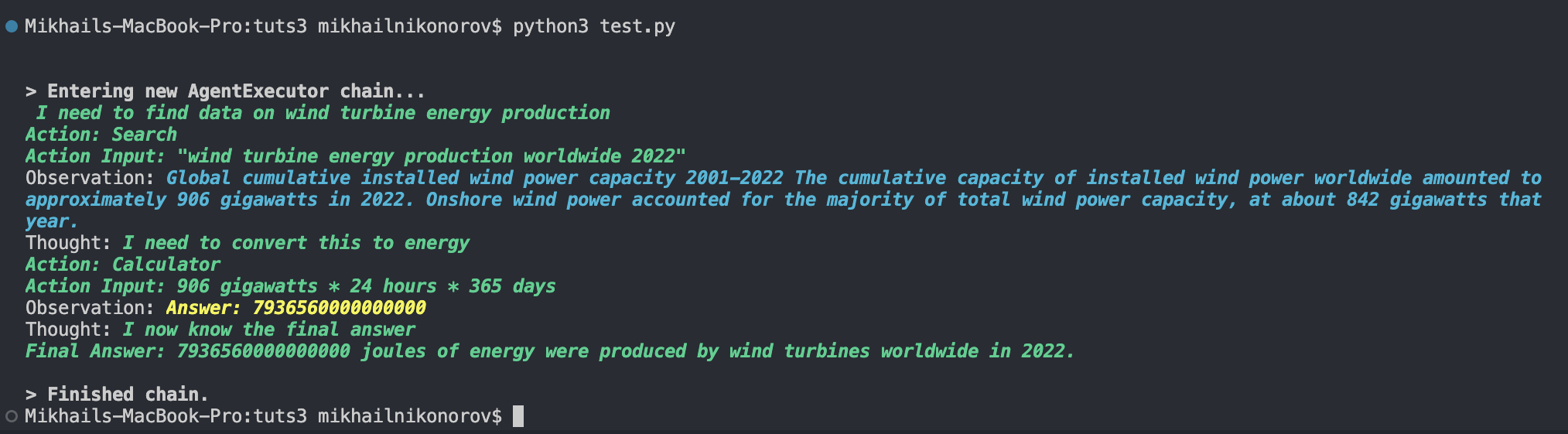
As you may see, it makes use of the next logic:
- seek for “wind turbine power manufacturing worldwide 2022” utilizing the Serp web search API
- analyze the most effective consequence
- get any related numbers
- convert 906 gigawatts to joules utilizing the
llm-mathdevice, since we requested for power, not energy
Agent take a look at instance 2
LangChain brokers aren’t restricted to looking out the Web. We will join virtually any knowledge supply (together with our personal) to a LangChain agent and ask it questions in regards to the knowledge. Let’s strive making an agent educated on a CSV dataset.
Obtain this Netflix films and TV reveals dataset from SHIVAM BANSAL on Kaggle and transfer it into your listing. Now add this code into a brand new Python file:
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.brokers.agent_types import AgentType
from langchain.brokers import create_csv_agent
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
agent = create_csv_agent(
OpenAI(temperature=0),
"netflix_titles.csv",
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
agent.run("In what number of films was Christian Bale casted")
This code calls the create_csv_agent operate and makes use of the netflix_titles.csv dataset. The picture under reveals our take a look at.
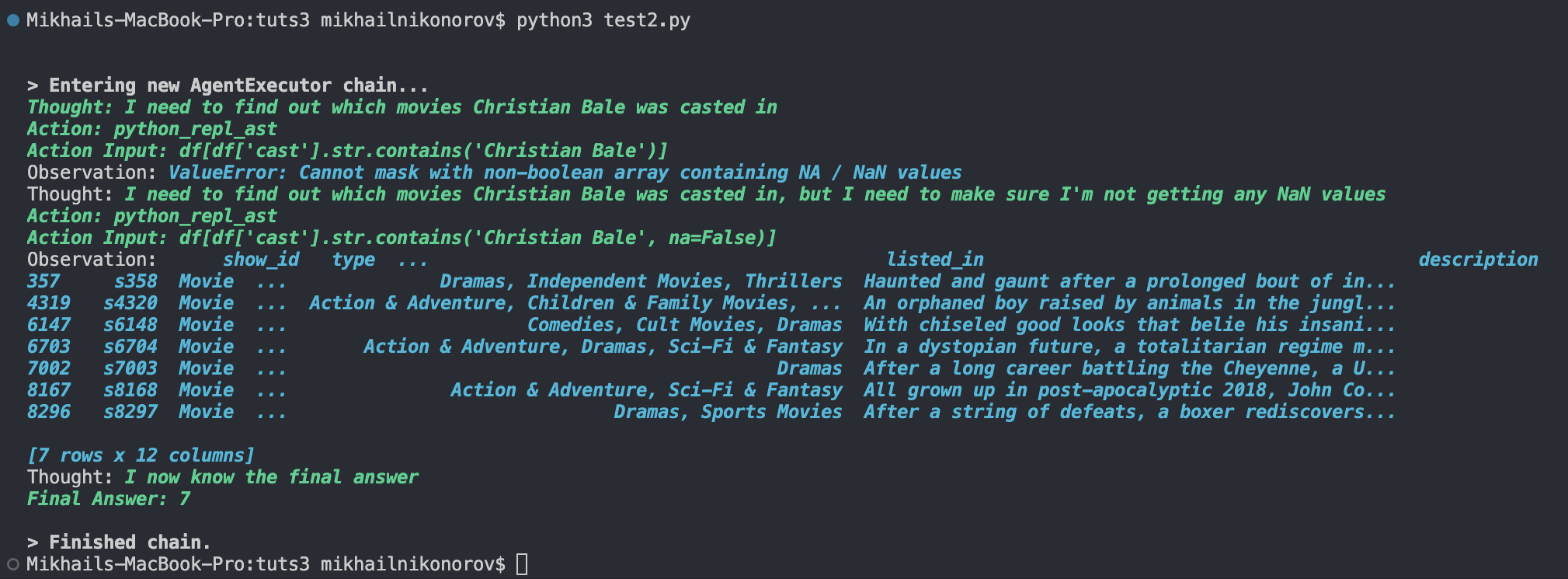
As proven above, its logic is to look within the solid column for all occurrences of “Christian Bale”.
We will additionally make a Pandas Dataframe agent like this:
from langchain.brokers import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.brokers.agent_types import AgentType
from langchain.llms import OpenAI
import pandas as pd
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
df = pd.read_csv("netflix_titles.csv")
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
agent.run("In what 12 months have been essentially the most comedy films launched?")
If we run it, we’ll see one thing just like the outcomes proven under.


These are just some examples. We will use virtually any API or dataset with LangChain.
Fashions
There are three varieties of fashions in LangChain: LLMs, chat fashions, and textual content embedding fashions. Let’s discover each sort of mannequin with some examples.
Language mannequin
LangChain offers a method to make use of language fashions in Python to provide textual content output based mostly on textual content enter. It’s not as advanced as a chat mannequin, and is used finest with easy enter–output language duties. Right here’s an instance utilizing OpenAI:
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
llm = OpenAI(mannequin="gpt-3.5-turbo", temperature=0.9)
print(llm("Provide you with a rap identify for Matt Nikonorov"))
As seen above, it makes use of the gpt-3.5-turbo mannequin to generate an output for the offered enter (“Provide you with a rap identify for Matt Nikonorov”). On this instance, I’ve set the temperature to 0.9 to make the LLM actually inventive. It got here up with “MC MegaMatt”. I’d give that one a strong 9/10.
Chat mannequin
Making LLM fashions give you rap names is enjoyable, but when we would like extra refined solutions and conversations, we have to step up our sport through the use of a chat mannequin. How are chat fashions technically totally different from language fashions? Effectively, within the phrases of the LangChain documentation:
Chat fashions are a variation on language fashions. Whereas chat fashions use language fashions underneath the hood, the interface they use is a bit totally different. Relatively than utilizing a “textual content in, textual content out” API, they use an interface the place “chat messages” are the inputs and outputs.
Right here’s a easy Python chat mannequin script:
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a friendly, informal assistant"),
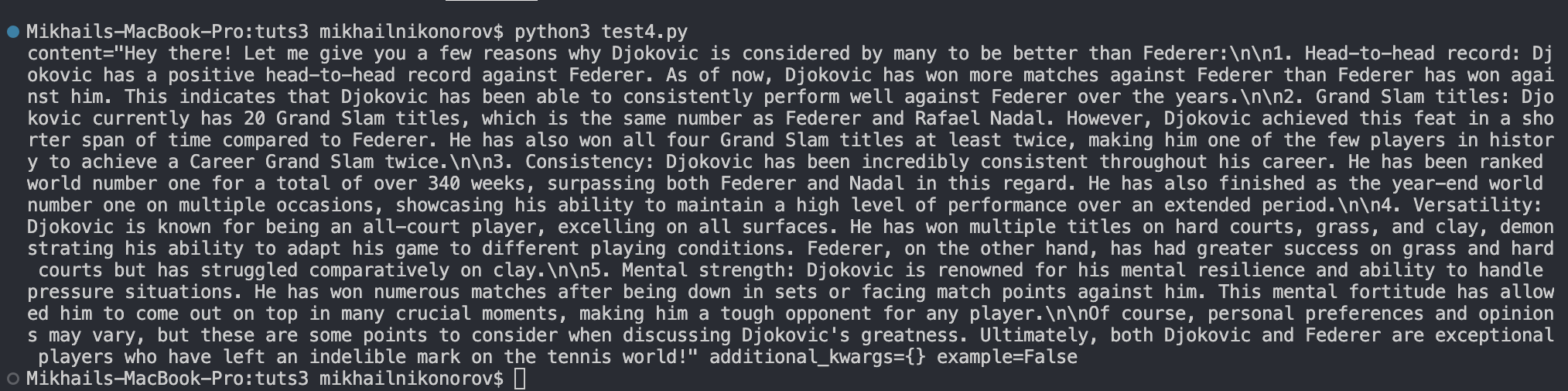
HumanMessage(content="Convince me that Djokovic is better than Federer")
]
print(chat(messages))
As proven above, the code first sends a SystemMessage and tells the chatbot to be pleasant and casual, and afterwards it sends a HumanMessage telling the chatbot to persuade us that Djokovich is best than Federer.
Should you run this chatbot mannequin, you’ll see one thing just like the consequence proven under.
Embeddings
Embeddings present a approach to flip phrases and numbers in a block of textual content into vectors that may then be related to different phrases or numbers. This will sound summary, so let’s have a look at an instance:
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embedded_query = embeddings_model.embed_query("Who created the world large net?")
embedded_query[:5]
This can return a listing of floats: [0.022762885317206383, -0.01276398915797472, 0.004815981723368168, -0.009435392916202545, 0.010824492201209068]. That is what an embedding seems to be like.
A use case of embedding fashions
If we need to prepare a chatbot or LLM to reply questions associated to our knowledge or to a particular textual content pattern, we have to use embeddings. Let’s make a easy CSV file (embs.csv) that has a “textual content” column containing three items of data:
textual content
"Robert Wadlow was the tallest human ever"
"The Burj Khalifa is the tallest skyscraper"
"Roses are crimson"
Now right here’s a script that may take the query “Who was the tallest human ever?” and discover the precise reply within the CSV file through the use of embeddings:
from langchain.embeddings import OpenAIEmbeddings
from openai.embeddings_utils import cosine_similarity
import os
import pandas
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
embeddings_model = OpenAIEmbeddings()
df = pandas.read_csv("embs.csv")
emb1 = embeddings_model.embed_query(df["text"][0])
emb2 = embeddings_model.embed_query(df["text"][1])
emb3 = embeddings_model.embed_query(df["text"][2])
emb_list = [emb1, emb2, emb3]
df["embedding"] = emb_list
embedded_question = embeddings_model.embed_query("Who was the tallest human ever?")
df["similarity"] = df.embedding.apply(lambda x: cosine_similarity(x, embedded_question))
df.to_csv("embs.csv")
df2 = df.sort_values("similarity", ascending=False)
print(df2["text"][0])
If we run this code, we’ll see that it outputs “Robert Wadlow was the tallest human ever”. The code finds the precise reply by getting the embedding of every piece of data and discovering the one most associated to the embedding of the query “Who was the tallest human ever?” The facility of embeddings!
Chunks
LangChain fashions can’t deal with giant texts on the similar time and use them to make responses. That is the place chunks and textual content splitting are available. Le’s have a look at two easy methods to separate our textual content knowledge into chunks earlier than feeding it into LangChain.
Splitting chunks by character
To keep away from abrupt breaks in chunks, we are able to break up our texts by paragraphs by splitting them at each incidence of a newline or double-newline:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(separators=["nn", "n"], chunk_size=2000, chunk_overlap=250)
texts = text_splitter.split_text(your_text)
Recursively splitting chunks
If we need to strictly break up our textual content by a sure size of characters, we are able to accomplish that utilizing RecursiveCharacterTextSplitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=250,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents([your_text])
Chunk dimension and overlap
Whereas trying on the examples above, you could have puzzled precisely what the chunk dimension and overlap parameters imply, and what implications they’ve on efficiency. That may be defined with two factors:
- Chunk dimension decides the quantity of characters that shall be in every chunk. The larger the chunk dimension, the extra knowledge is within the chunk, and the extra time it is going to take LangChain to course of it and to provide an output, and vice versa.
- Chunk overlap is what shares data between chunks in order that they share some context. The upper the chunk overlap, the extra redundant our chunks shall be, the decrease the chunk overlap, and the much less context shall be shared between the chunks. Usually, a great chunk overlap is between 10% and 20% of the chunk dimension, though the best chunk overlap varies throughout totally different textual content sorts and use instances.
Chains
Chains are principally a number of LLM functionalities linked collectively to carry out extra advanced duties that couldn’t in any other case be accomplished with easy LLM enter --> output trend. Let’s have a look at a cool instance:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
os.environ["OPENAI_API_KEY"] = "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"
llm = OpenAI(temperature=0.9)
immediate = PromptTemplate(
input_variables=["media", "topic"],
template="What is an efficient title for a {media} about {matter}",
)
chain = LLMChain(llm=llm, immediate=immediate)
print(chain.run({
'media': "horror film",
'matter': "math"
}))
This code takes two variables into its immediate and formulates a inventive reply (temperature=0.9). On this instance, we’ve requested it to give you a great title for a horror film about math. The output after operating this code was “The Calculating Curse”, however this doesn’t actually present the complete energy of chains.
Let’s check out a extra sensible instance:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from typing import Non-compulsory
from langchain.chains.openai_functions import (
create_openai_fn_chain,
create_structured_output_chain,
)
import os
os.environ["OPENAI_API_KEY"] = "YOUR_KEY"
llm = ChatOpenAI(mannequin="gpt-3.5-turbo", temperature=0.1)
template = """Use the given format to extract data from the next enter: {enter}. Make certain to reply within the appropriate format"""
immediate = PromptTemplate(template=template, input_variables=["input"])
json_schema = {
"sort": "object",
"properties": {
"identify": {"title": "Title", "description": "The artist's identify", "sort": "string"},
"style": {"title": "Style", "description": "The artist's music style", "sort": "string"},
"debut": {"title": "Debut", "description": "The artist's debut album", "sort": "string"},
"debut_year": {"title": "Debut_year", "description": "Yr of artist's debut album", "sort": "integer"}
},
"required": ["name", "genre", "debut", "debut_year"],
}
chain = create_structured_output_chain(json_schema, llm, immediate, verbose=False)
f = open("Nas.txt", "r")
artist_info = str(f.learn())
print(chain.run(artist_info))
This code could look complicated, so let’s stroll via it.
This code reads a brief biography of Nas (Hip-Hop Artist) and extracts the next values from the textual content and codecs them right into a JSON object:
- the artist’s identify
- the artist’s music style
- the artist’s debut album
- the 12 months of artist’s debut album
Within the immediate we additionally specify “Make certain to reply within the appropriate format”, in order that we all the time get the output in JSON format. Right here’s the output of this code:
{'identify': 'Nas', 'style': 'Hip Hop', 'debut': 'Illmatic', 'debut_year': 1994}
By offering a JSON schema to the create_structured_output_chain operate, we’ve made the chain put its output into JSON format.
Going Past OpenAI
Regardless that I hold utilizing OpenAI fashions as examples of the totally different functionalities of LangChain, it isn’t restricted to OpenAI fashions. We will use LangChain with a large number of different LLMs and AI companies. (Right here’s a full record of LangChain integratable LLMs.)
For instance, we are able to use Cohere with LangChain. Right here’s the documentation for the LangChain Cohere integration, however simply to provide a sensible instance, after putting in Cohere utilizing pip3 set up cohere we are able to make a easy query --> reply code utilizing LangChain and Cohere like this:
from langchain.llms import Cohere
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template = """Query: {query}
Reply: Let's assume step-by-step."""
immediate = PromptTemplate(template=template, input_variables=["question"])
llm = Cohere(cohere_api_key="YOUR_COHERE_KEY")
llm_chain = LLMChain(immediate=immediate, llm=llm)
query = "When was Novak Djokovic born?"
print(llm_chain.run(query))
The code above produces the next output:
The reply is Novak Djokovic was born on Might 22, 1987.
Novak Djokovic is a Serbian tennis participant.
Conclusion
On this information, you’ve seen the totally different elements and functionalities of LangChain. Armed with this information, you’re now outfitted to leverage LangChain’s capabilities in your NLP endeavors, whether or not you’re a researcher, developer, or hobbyist.
You could find a repo with all the pictures and the Nas.txt file from this text on GitHub.
Completely satisfied coding and experimenting with LangChain in Python!