
{kind=link}
Welcome to our tutorial on operating Qwen2:7b with Ollama. On this information, we’ll use one in all our favourite GPUs, A5000, provided by Paperspace.
A5000, powered by NVIDIA and constructed on ampere structure, is a strong GPU recognized to reinforce the efficiency of rendering, graphics, AI, and computing workloads. A5000 presents 8192 CUDA cores and 24 GB of GDDR6 reminiscence, offering distinctive computational energy and reminiscence bandwidth.
The A5000 helps superior options like real-time ray tracing, AI-enhanced workflows, and NVIDIA’s CUDA and Tensor cores for accelerated efficiency. With its sturdy capabilities, the A5000 is right for dealing with advanced simulations, large-scale knowledge evaluation, and rendering high-resolution graphics.
What’s Qwen2-7b?
Qwen2 is the most recent collection of giant language fashions, providing base fashions and instruction-tuned variations starting from 0.5 to 72 billion parameters, together with a Combination-of-Consultants mannequin. One of the best factor concerning the mannequin is that it’s open-sourced on Hugging Face.
In comparison with different open-source fashions like Qwen1.5, Qwen2 typically outperforms them throughout numerous benchmarks, together with language understanding, era, multilingual functionality, coding, arithmetic, and reasoning. The Qwen2 collection relies on the Transformer structure with enhancements like SwiGLU activation, consideration QKV bias, group question consideration, and an improved tokenizer adaptable to a number of languages and codes.
Additional, Qwen2-72B is claimed to outperform Meta’s Llama3-70B in all examined benchmarks by a large margin.
Additionally, within the picture under, we will see that Qwen2-72B has outperformed Llama3-70B, the most recent mannequin within the Llama collection, on numerous benchmarks.
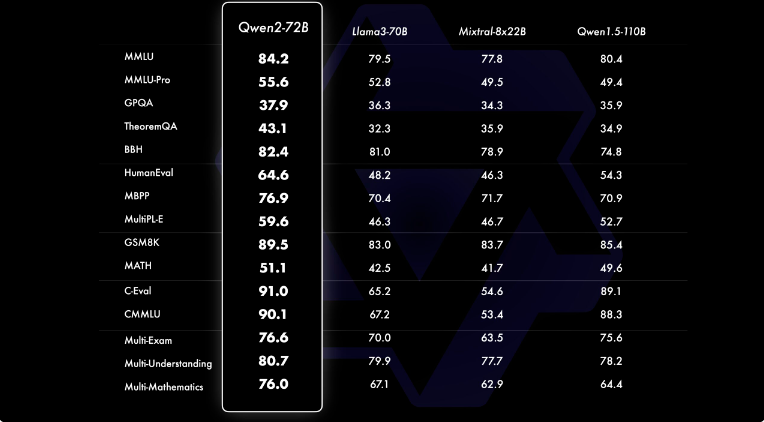
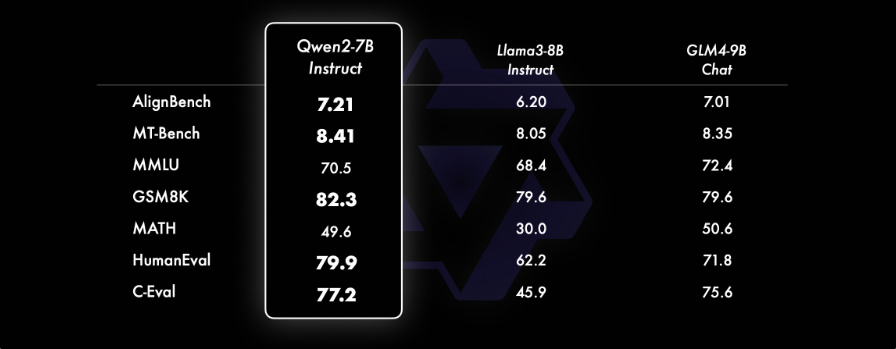
A complete analysis of Qwen2-72B-Instruct throughout 16 benchmarks on numerous domains is proven within the under picture. This mannequin achieves a steadiness between enhanced capabilities and alignment with human values. Additionally, the mannequin considerably outperforms Qwen1.5-72B-Chat on all benchmarks and demonstrates aggressive efficiency in comparison with Llama-3-70B-Instruct. Even smaller Qwen2 fashions surpass state-of-the-art fashions of comparable or bigger sizes. Qwen2-7B-Instruct maintains benefits throughout benchmarks, significantly excelling in coding and Chinese language-related metrics.
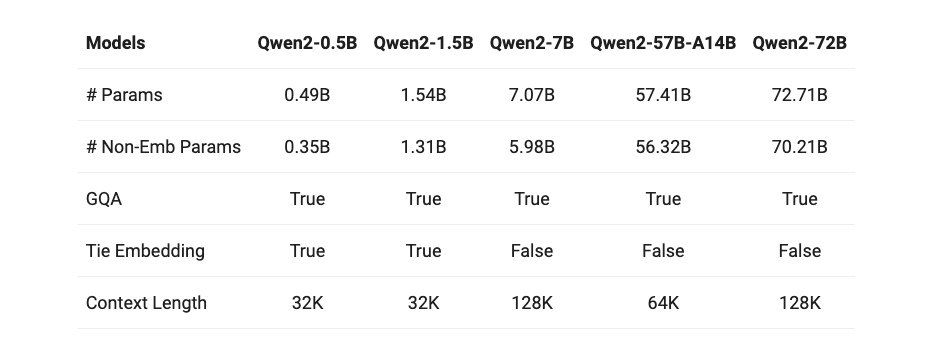
Out there Mannequin
Qwen2 is educated on a dataset comprising 29 languages, together with English and Chinese language. It has 5 parameter sizes: 0.5B, 1.5B, 7B, 57B and 72B. The context size of the 7B and 72B fashions has been expanded to 128k tokens.
Temporary Introduction to Ollama
This text will present you the simplest methodology to run the Qwen2 utilizing Ollama. Ollama is an open-source venture providing a user-friendly platform for executing giant language fashions (LLMs) in your private laptop or utilizing a platform like Paperspace.
Ollama offers entry to a various library of pre-trained fashions, presents easy set up and setup throughout totally different working methods, and exposes a neighborhood API for seamless integration into functions and workflows. Customers can customise and fine-tune LLMs, optimize efficiency with {hardware} acceleration, and profit from interactive consumer interfaces for intuitive interactions.
Run Qwen2-7b on Paperspace with Ollama
Convey this venture to life
Earlier than we begin, allow us to first examine the GPU specification.
nvidia-smi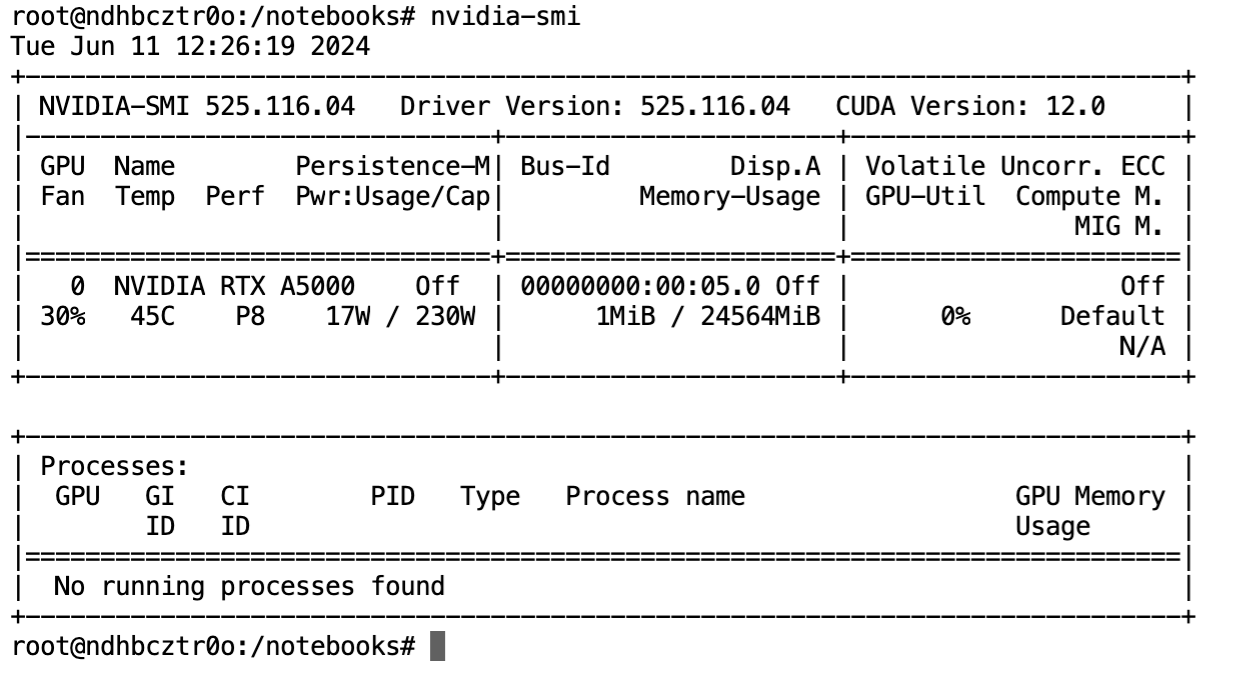
Subsequent, open up a terminal, and we are going to begin downloading Ollama. To obtain Ollama, paste the code under into the terminal and press enter.
curl -fsSL https://ollama.com/set up.sh | sh
This one line of code will begin downloading Ollama.
As soon as that is executed, clear the display, sort the under command, and press enter to run the mannequin.
ollama run qwen2:7b💡
In case of Error: couldn’t hook up with ollama app, is it operating? Strive operating the under code, it will assist begin ollama service
ollama serve
and open up one other terminal and check out the command once more.
or strive enabling the systemctl service manually by operating the under command.
sudo systemctl allow ollama
sudo systemctl begin ollamaNow, we will run the mannequin for inferencing.
ollama run qwen2:7bIt will obtain the layers of the mannequin, additionally please be aware this can be a quantized mannequin. Therefore the downloading course of won’t take a lot time.
Subsequent, we are going to begin utilizing our mannequin to reply few query and examine how the mannequin works.
- Write a python code for a fibonacci
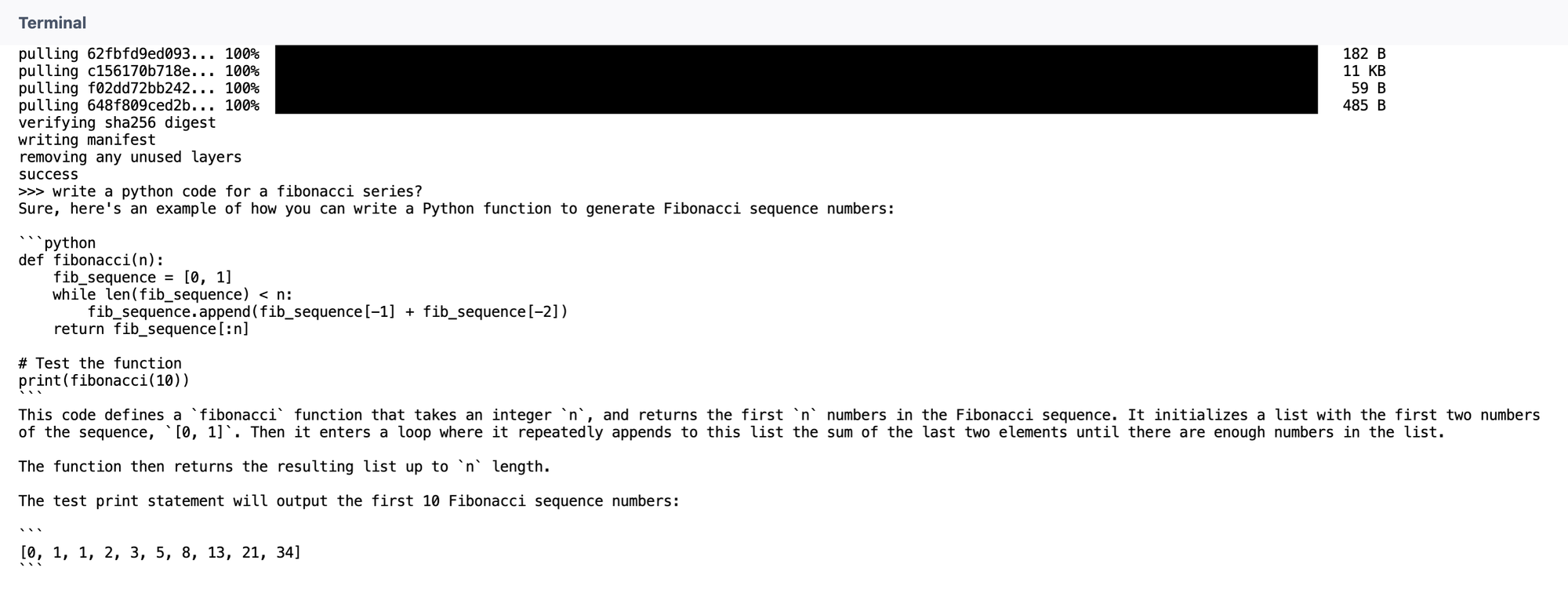
- What’s aware consuming?
- Clarify quantum Physics
Response generated by Qwen2:7b
Please be happy to check out different mannequin variations nevertheless 7b is the most recent model and is out there with Ollama.
The mannequin demonstrates spectacular efficiency in numerous facets, matching the general efficiency of GPT compared to an earlier mannequin.
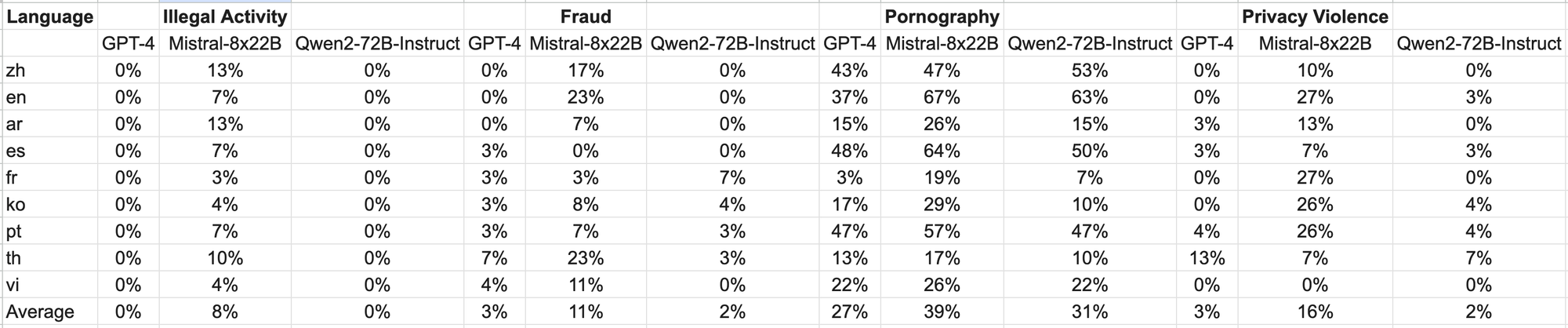
Take a look at knowledge, sourced from Jailbreak and translated into a number of languages, was used for analysis. Notably, Llama-3 struggled with multilingual prompts and was thus excluded from comparability. The findings reveals that the Qwen2-72B-Instruct mannequin achieves security ranges corresponding to GPT-4 and considerably outperforms the Mistral-8x22B mannequin in keeping with significance testing (P-value).
Conclusion
In conclusion, we will say that the Qwen2-72B-Instruct mannequin, demonstrates its exceptional efficiency throughout numerous benchmarks. Notably, Qwen2-72B-Instruct surpasses earlier iterations resembling Qwen1.5-72B-Chat and even competes favorably with state-of-the-art fashions like GPT-4, as evidenced by significance testing outcomes. Furthermore, it considerably outperforms fashions like Mistral-8x22B, underscoring its effectiveness in guaranteeing security throughout multilingual contexts.
Wanting forward, the speedy enhance in using giant language fashions like Qwen2 hints at a future the place AI-driven functions and options turning into increasingly more subtle. These fashions have the potential to revolutionize numerous domains, together with pure language understanding, era, multilingual communication, coding, arithmetic, and reasoning. With continued developments and refinements in these fashions, we will anticipate even larger strides in AI expertise, resulting in the event of extra clever and human-like methods that higher serve society’s wants whereas adhering to moral and security requirements.
We hope you loved studying this text!