
{kind=link}
Carry this mission to life
In our more and more interconnected world, the widespread presence of the web, cell gadgets, social media, and communication platforms has offered folks with unprecedented entry to multilingual content material. On this context, the flexibility to speak and comprehend data in any language on-demand is turning into more and more essential. Though this functionality has at all times been a dream in science fiction, synthetic intelligence is on its approach of reworking this imaginative and prescient right into a technical actuality.
On this article we introduce SeamlessM4T: a groundbreaking multilingual and multitask mannequin for seamless translation and transcription throughout speech and textual content. It helps computerized speech recognition, speech-to-text translation, speech-to-speech translation, text-to-text translation, and text-to-speech translation for practically 100 languages, with 35 extra languages supported for output, together with English.
SeamlessM4T marks a serious development within the realm of speech-to-speech and speech-to-text applied sciences by overcoming the constraints related to restricted language protection and the reliance on distinct techniques.
Method utilized by Seamless M4T
To be able to construct a light-weight and environment friendly sequence modeling toolkit Meta redesigned fairseq, one of many first and hottest sequence modeling toolkits. Fairseq2 has confirmed to be extra environment friendly and has helped to energy the modeling behind SeamlessM4T.
A Multitask UnitY mannequin structure, it’s able to producing each translated textual content and speech immediately. This superior framework helps numerous capabilities, together with computerized speech recognition, text-to-text, text-to-speech, speech-to-text, and speech-to-speech translations, seamlessly built-in from the vanilla UnitY mannequin. The multitask UnitY mannequin includes three key parts: textual content and speech encoders acknowledge speech enter throughout practically 100 languages, the textual content decoder interprets which means into practically 100 languages for textual content, and a text-to-unit mannequin decodes it into discrete acoustic models for 36 speech languages. To boost mannequin high quality and stability, the self-supervised encoder, speech-to-text, text-to-text translation parts, and text-to-unit mannequin bear pre-training. The ultimate step entails changing the decoded discrete models into speech utilizing a multilingual HiFi-GAN unit vocoder.
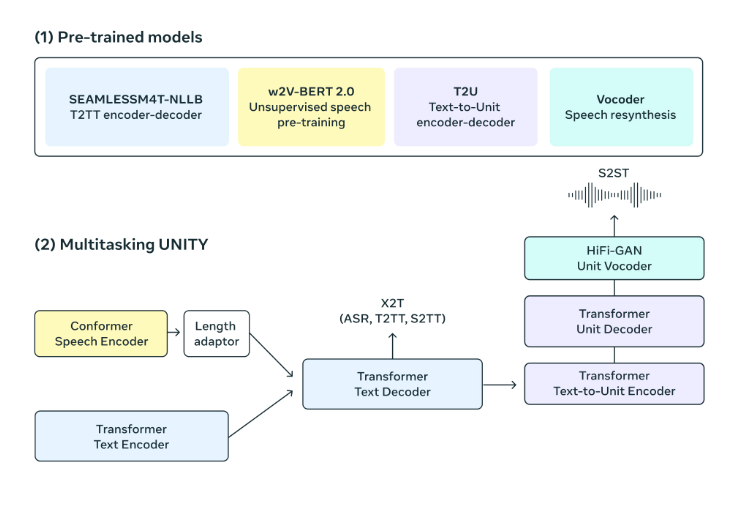
- Encoder Processes Speech:
The self-supervised speech encoder, w2v-BERT 2.0, is an upgraded model of w2v-BERT. That is designed in such a method to improve the coaching stability and illustration high quality. It’s even able to studying and understanding the construction and which means in speech by analyzing huge quantities of multilingual speech information over tens of millions of hours. This encoder processes audio indicators, breaks them into smaller parts, and constructs an inner illustration of the spoken content material. To align with precise phrases, provided that spoken phrases consist of assorted sounds and characters, a size adapter is used for extra correct mapping.
- Encoder Processes Textual content:
The textual content encoder based mostly on the NLLB (NLLB Workforce et al., 2022) mannequin, and is educated to grasp 100 languages which is then used for translation.
- Producing textual content:
The textual content decoder is adept at dealing with encoded speech or textual content representations, making it versatile for duties throughout the similar language, together with computerized speech recognition and multilingual translation. By multitask coaching, a sturdy text-to-text translation mannequin (NLLB) is utilized to successfully information the speech-to-text translation mannequin, using token-level data distillation for enhanced efficiency.
- Producing speech:
Within the UnitY mannequin, the usage of acoustic models symbolize speech. The text-to-unit (T2U) part creates these speech models from the textual content output. Earlier than fine-tuning UnitY, T2U is pre-trained on ASR information. Lastly, a multilingual HiFi-GAN unit vocoder transforms these models into audio waveforms.
- Knowledge Scaling:
SeamlessM4T mannequin required a considerable amount of information to coach, ideally prime quality information too. Earlier efforts in text-to-text mining are additional prolonged on this analysis with a similarity measure in a joint embedding house and likewise growth of the preliminary work in speech mining are included. These contributions assist create extra sources for coaching the SeamlessM4T mannequin.
SONAR (Sentence-level mOdality- and laNguage-Agnostic Representations), a extremely efficient multilingual and multimodal textual content embedding house for 200 languages, surpassing present strategies like LASER3 and LaBSE in multilingual similarity search has been established right here. To work with these SONAR representations, a teacher-student method is used to incorporate speech modality. The information mining duties concerned huge quantities of information from net repositories (tens of billions of sentences) and speech (4 million hours).
- Outcomes Achieved:
The Knowledge Scaling as mentioned ends in SeamlessAlign, a major corpus with over 443,000 hours of aligned speech with texts and round 29,000 hours of speech-to-speech alignments. SeamlessAlign stands as the most important open parallel corpus for speech/speech and speech/textual content by way of each quantity and language protection to this point.
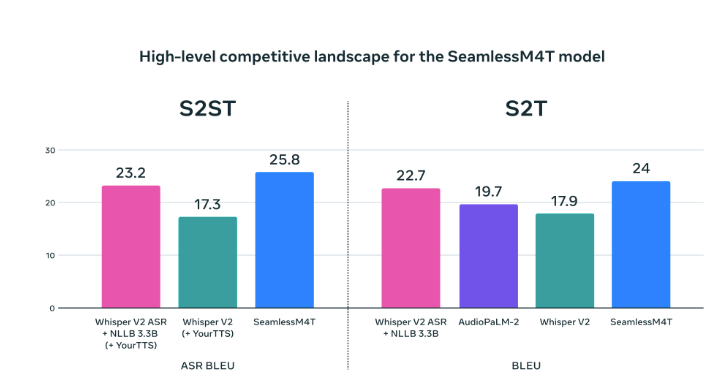
SeamlessM4T has confirmed to attain state-of-the-art outcomes for ASR, speech-to-text, speech-to-speech, text-to-speech, and text-to-text translation—all in a single mannequin. BLASER 2.0 is now used for metric analysis.
Meta claims SeamlessM4T, outperforms earlier SOTA rivals.
Paperspace Demo
Carry this mission to life
To start with provoke a Paperspace Pocket book along with your most well-liked GPU or with the free GPU. Clone the repository to make use of the Pocket book, both utilizing the offered hyperlink above or positioned firstly of this text. Clicking the hyperlink will open the mission on a Paperspace Free GPU, if one is out there. Subsequent, open the mission on Paperspace platform. Begin the machine and click on to open the .ipynb file.
Setup
With that accomplished, navigate to open the pocket book seamlessM4T.ipynb. This pocket book has all the required code to run the mannequin and acquire the outcomes.
- Set up the ‘transformer’, ‘sentencepiece’ utilizing ‘pip set up’
!pip set up git+https://github.com/huggingface/transformers.git sentencepiece
This command installs the ‘transformers’ package deal from the desired GitHub repository and likewise installs the ‘sentencepiece’ package deal. The ‘transformers’ library, developed by Hugging Face, is often used for pure language processing duties, and ‘sentencepiece’ is a library for tokenizing textual content.
2. As soon as the set up is full, transfer to the following cell. It will import the required libraries required to work with the SeamlessM4T mannequin.
#import the required libraries
from transformers import AutoProcessor, SeamlessM4Tv2Model
import torchaudio3. Subsequent, load the pre-trained mannequin utilizing the Hugging Face Transformers library and processor from the “SeamlessM4T” household by Fb.
#load the pre-trained mannequin and processor
processor = AutoProcessor.from_pretrained("fb/seamless-m4t-v2-large")
mannequin = SeamlessM4Tv2Model.from_pretrained("fb/seamless-m4t-v2-large")These two traces of code load a pre-trained SeamlessM4T mannequin and its related processor, making it prepared to be used within the NLP duties. The processor is answerable for tokenizing and preprocessing enter textual content, whereas the mannequin is answerable for performing the precise duties.
4. The under piece of code will assist us to make use of the beforehand loaded SeamlessM4T mannequin and processor to generate speech from a given enter textual content or audio.
# from textual content
text_inputs = processor(textual content = "Howdy, my canine is cute", src_lang="eng", return_tensors="pt")
audio_array_from_text = mannequin.generate(**text_inputs, tgt_lang="ben")[0].cpu().numpy().squeeze()# from audio
audio, orig_freq = torchaudio.load("https://www2.cs.uic.edu/~i101/SoundFiles/preamble10.wav")
audio = torchaudio.useful.resample(audio, orig_freq=orig_freq, new_freq=16_000) # should be a 16 kHz waveform array
audio_inputs = processor(audios=audio, return_tensors="pt")
audio_array_from_audio = mannequin.generate(**audio_inputs, tgt_lang="ben")[0].cpu().numpy().squeeze()5. The ultimate step to show and play the audio generated by the mannequin. The under code snippet is used to make the most of the ‘Audio’ class to show and play audio in an IPython surroundings. The audio information is offered within the type of NumPy arrays (audio_array_from_text and audio_array_from_audio), and the sampling charge is specified to make sure correct playback.
#import the Audio class from the IPython.show module.
from IPython.show import Audio
#retrieve the sampling charge of the audio generated by the SeamlessM4T mannequin
sample_rate = mannequin.config.sampling_rate
#create an Audio object utilizing the generated audio array and specify pattern charge
Audio(audio_array_from_text, charge=sample_rate)
# Audio(audio_array_from_audio, charge=sample_rate)The ultimate step will enable the consumer to play the generated within the pocket book itself additionally we will save the audio file if required to. We extremely suggest our readers to click on the hyperlink offered and navigate to the .ipynb file and discover the mannequin and Paperspace platform.
What makes SeamlessM4T completely different
Making a common translator has been troublesome because of the presence of an unlimited variety of world’s languages. Moreover, a variety of translation duties like speech-to-text, speech-to-speech, and text-to-text are required to depend on numerous AI fashions.
A lot of these duties typically require an enormous quantity of coaching information. SeamlessM4T, serving as a unified multilingual mannequin throughout all modalities, addresses the above talked about challenges. The mannequin additionally seamlessly permits on-demand translations, considerably facilitating communication between audio system of various languages. So as to add extra, the mannequin has additionally considerably improved the interpretation efficiency of low- and mid-resource languages.
On Fleurs, SeamlessM4T raises the bar for translations into a number of goal languages, outperforming the prior state-of-the-art in direct speech-to-text translation by a powerful 20% BLEU enchancment. In comparison with strong cascaded fashions, SeamlessM4T enhances the standard of into-English translation by 1.3 BLEU factors in speech-to-text and by 2.6 ASR-BLEU factors in speech-to-speech.
The mannequin can also be delicate to bias and toxicity. To deal with toxicity, Meta expanded their multilingual toxicity classifier to research speech, figuring out and filtering poisonous phrases in each inputs and outputs. Additional steps had been taken to mitigate unbalanced toxicity within the coaching information by eradicating pairs the place the enter or output exhibited various ranges of toxicity.
It’s value mentioning: with a purpose to make the mannequin as ethically sound as potential, the AI researchers at Meta, adopted a accountable framework which is once more guided by the 5 pillars of Accountable AI.
Closing ideas
Though text-based fashions have made large developments to cowl over 200 languages for machine translation, however unified speech-to-speech translation fashions nonetheless lag behind. Conventional speech-to-speech techniques use cascaded approaches with a number of subsystems, this method hampers the event of scalable and high-performing unified speech translation techniques. To bridge these gaps, SeamlessM4T is launched, which serves as a complete mannequin supporting translation throughout numerous modalities. This single mannequin accommodates speech-to-speech, speech-to-text, text-to-speech, text-to-text, and computerized speech recognition duties for as much as 100 languages.
Being stated that there’s nonetheless a scope to additional enhance the mannequin for ASR duties as said within the authentic analysis paper. Moreover, the mannequin’s proficiency in translating slangs or correct nouns would possibly range between excessive and low-resource languages.
You will need to word right here that translating speech has an additional problem as a result of it occurs immediately, and audio system haven’t got a lot time to examine or repair errors throughout a stay dialog. Not like with written language, the place the phrases are deliberate and revised, spoken phrases cannot be simply edited. So, speech-to-speech translation may need extra dangers by way of misunderstandings or offensive language, as there’s much less likelihood to appropriate errors on the spot.
The functions developed utilizing SeamlessM4T needs to be thought-about as an assistant and never a software that replaces human translators or the necessity to be taught new languages.
Speech shouldn’t be only a few phrases however is an expression of feelings!
With this we come to the top of the article and we hope that you simply loved the article and the Paperspace platform.
We strongly hope that SeamlessM4T opens up new prospects for industrial functions and in analysis areas as effectively.
Thanks for studying!