
{kind=link}
Convey this challenge to life
Producing photographs with Deep Studying is arguably one of many best and most versatile purposes of this era of generative, weak AI. From producing fast advertising and marketing content material to augmenting artist workflows to making a enjoyable studying software for AI, we will simply see this ubiquity in motion with the widespread recognition of the Steady Diffusion household of fashions. That is largely to the Stability AI and Runway ML groups efforts to maintain the mannequin releases open sourced, and likewise owes an enormous due to the lively neighborhood of builders creating instruments with these fashions. Collectively, these traits have made the mannequin extremely accessible and simple to run – even for folks with no coding expertise!
Since their launch, these Latent Diffusion Mannequin primarily based text-to-image fashions have confirmed extremely succesful. Up till now, the one actual competitors from the open supply neighborhood was with different Steady Diffusion releases. Notably, there may be now an infinite library of fine-tuned mannequin checkpoints out there on websites like HuggingFace and CivitAI.
On this article, we’re going to cowl our favourite open supply, text-to-image generative mannequin to be launched since Steady Diffusion: PixArt Alpha. This superior new mannequin boasts an exceptionally low coaching price, a progressive coaching technique that abstracts important components from a usually blended methodology, extremely informative coaching information, and implement a novel T2I Environment friendly transformer. On this article, we’re going to talk about these traits in additional element as a way to present what makes this mannequin so promising, earlier than diving into our a modified model of the unique Gradio demo working on a Paperspace Pocket book.
Click on the Run on Paperspace on the high of this pocket book or under the “Demo” part to run the app on a Free GPU powered Pocket book.
PixArt Alpha: Undertaking Breakdown
On this part, we are going to take a deeper have a look at the mannequin’s structure, coaching methodology, and the outcomes of the challenge compared to different T2I fashions by way of coaching price and efficacy. Let’s start with a breakdown of the novel mannequin structure.
Mannequin structure
The mannequin structure is acquainted to different T2I fashions, as it’s primarily based on the Diffusion Transformer mannequin, however has some vital tweaks that provide noticeable enhancements. As recorded within the appendix of the paper, “We undertake the DiT-XL mannequin, which has 28 Transformer blocks in whole for higher efficiency, and the patch dimension of the PatchEmbed layer in ViT (Dosovitskiy et al., 2020b) is 2×” (Supply). With that in thoughts, we will construct a tough thought of the construction of the mannequin, however that does not expose all of the notable adjustments they made.
Let’s stroll by means of the method every text-image pair makes by means of a Transformer block throughout coaching, so we will have a greater thought of what different adjustments they made to DiT-XL to garner such substantial reductions in price.
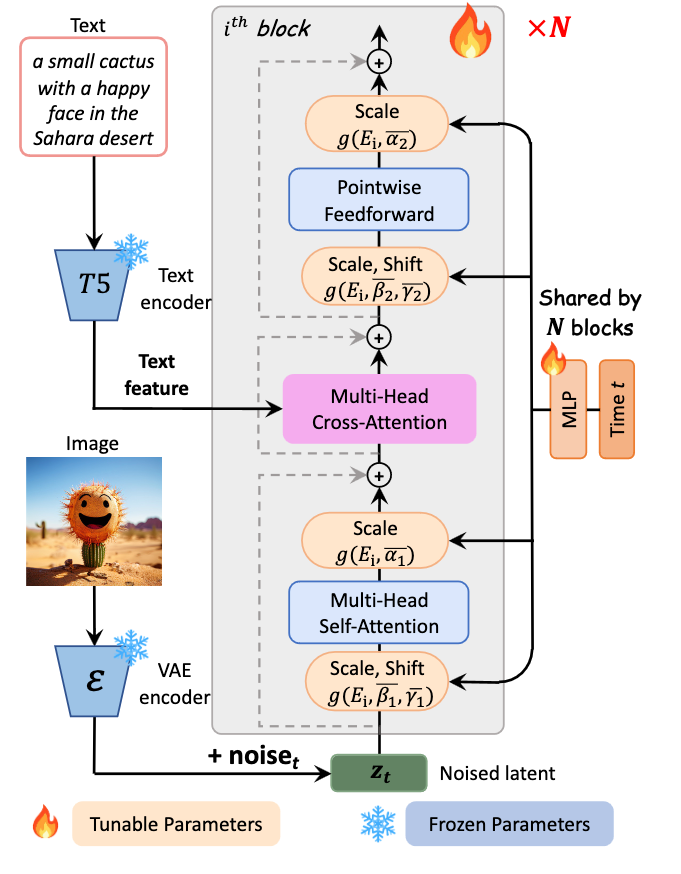
First, we begin with our textual content and our picture being entered right into a T5 textual content encoder and Variational AutoEncoder (VAE) encoder modal, respectively. These encoders have frozen parameters, this prevents sure elements of the mannequin from being adjusted throughout coaching. We do that to protect the unique traits of those encoders all through the coaching course of. Right here our course of splits.
The picture information is subtle with noise to create a noised latent illustration. There it’s scaled and shifted utilizing AdaLN-single layers, that are related to and might regulate parameters throughout N completely different Transformer blocks. This scale and shift worth is set by a block-specific Multi Layer Perceptron (MLP), proven on the fitting of the determine. It then passes by means of a self-attention layer and a further AdaLN-single scaling layer. There it’s handed to the Multi-Head Cross Consideration layer.
Within the different path, the textual content characteristic is entered on to the Multi-Head Cross Consideration layer, which is positioned between the self-attention layer and feed ahead layer of every Transformer block. Successfully, this enables the mannequin to work together with the textual content embedding in a versatile method. The output challenge layer is initialized at zero to behave as an id mapping and protect the enter for the next layers. In observe, this enables every block to inject textual circumstances. (Supply)
The Multi-Head Cross Consideration Layer has the flexibility to combine two completely different embedding sequences, as long as they share the identical dimension. (Supply). From there, the now unified embedding are handed to a further Scale + Shift layer with the MLP. Subsequent, the Pointwise Feedforward layer helps the mannequin seize complicated relationships within the information by making use of a non-linear transformation independently to every place. It introduces flexibility to mannequin complicated patterns and dependencies inside the sequence. Lastly, the embedding is handed to a ultimate Scale layer, and on to the block output.
This intricate course of permits these layers to regulate to the inputted options of the text-image pairs over the time of coaching, and, very similar to with different diffusion fashions, the method may be functionally reversed for the aim of inference.
Now that we now have regarded on the course of a datum takes in coaching, let’s check out the coaching course of itself in larger element.
Coaching PixArt Alpha
The coaching paradigm for the challenge has immense significance due to the affect it has on the associated fee to coach and ultimate efficiency of the mannequin. The authors particularly recognized their novel technique as being important for the general success of the mannequin. They describe this technique as involving decomposing the duty of coaching the mannequin into three distinct subtasks.
First, they skilled the mannequin to deal with studying the pixel distribution of pure photographs. They skilled a class-conditional picture generational mannequin for pure photographs with an appropriate initialization. This creates a boosted ImageNet mannequin pre-trained on related picture information, and PixArt Alpha is designed to be suitable with these weights
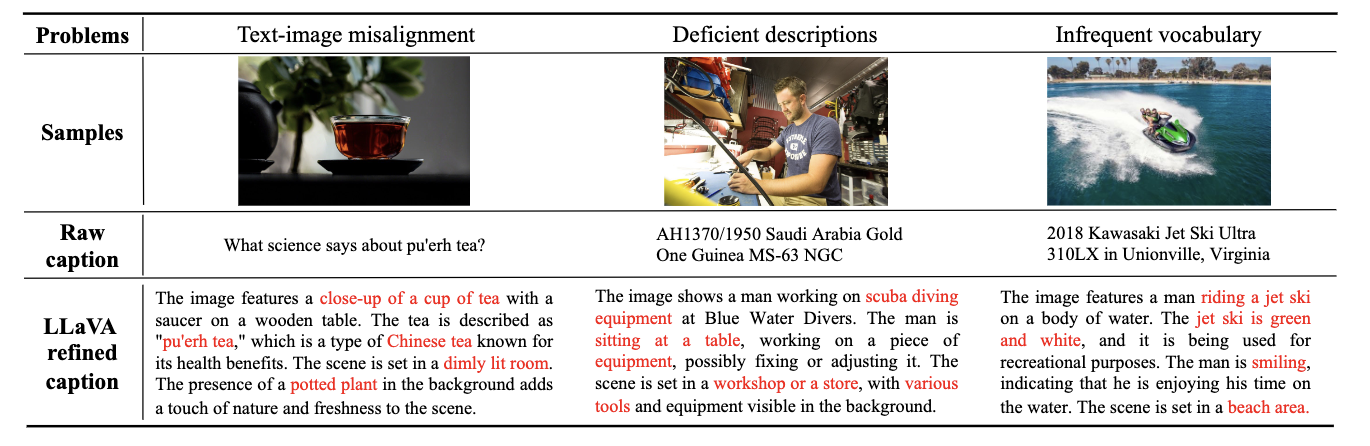
Within the second stage, the mannequin is tasked with studying to align the text-image object pairs. To be able to obtain an correct alignment between textual content ideas and pictures, they constructed a dataset consisting of text-image pairs utilizing LLaVA to caption samples from the SAM dataset. LLaVA-labeled captions had been considerably extra strong relating to having adequate legitimate nouns and idea density for finetuning when in comparison with LLaVA (for extra particulars, please go to the Dataset building part of the paper)

Lastly, they used the third stage to lift aesthetic high quality. Within the third coaching stage, they used augmented “Inner” information from JourneyDB with excessive “aesthetic” high quality. By fine-tuning the mannequin on these, they can improve the ultimate output for aesthetic high quality and element. This inner information they created is reported to be of even increased high quality than that created by SAM-LLaVA, by way of Legitimate Nouns over Complete Distinct Nouns.
Mixed, this decoupled pipeline is extraordinarily efficient at decreasing the coaching price and time for the mannequin. Coaching for the mixed high quality of those three traits has confirmed troublesome, however by decomposing these processes and utilizing completely different information sources for every stage, the challenge authors are in a position to obtain a excessive diploma of coaching high quality at a fraction of the associated fee.
Value and efficacy advantages of PixArt Alpha towards competitors

Now that we now have regarded a bit deeper on the mannequin structure and coaching methodology & reasoning, let’s talk about the ultimate outcomes of the PixArt Alpha challenge. It is crucial when discussing this mannequin to debate its extremely low, comparative price of coaching to different T2I fashions.
The authors of the challenge have offered these three helpful figures for our comparability. Let’s establish just a few key metrics from these graphics:
- PixArt Alpha trains in 10.8% of the time as Steady Diffusion v1.5 at the next decision (512 vs 1024).
- Trains in lower than 2% of coaching time of RAPHAEL, one of many newest closed supply releases for the mannequin
- Makes use of .2% of knowledge used to coach Imagen, presently #3 on Paperswithcode.com’s recording of high text-to-image fashions examined on COCO
All collectively, these metrics point out that PixArt was extremely reasonably priced to coach in comparison with competitors, however how does it carry out compared?
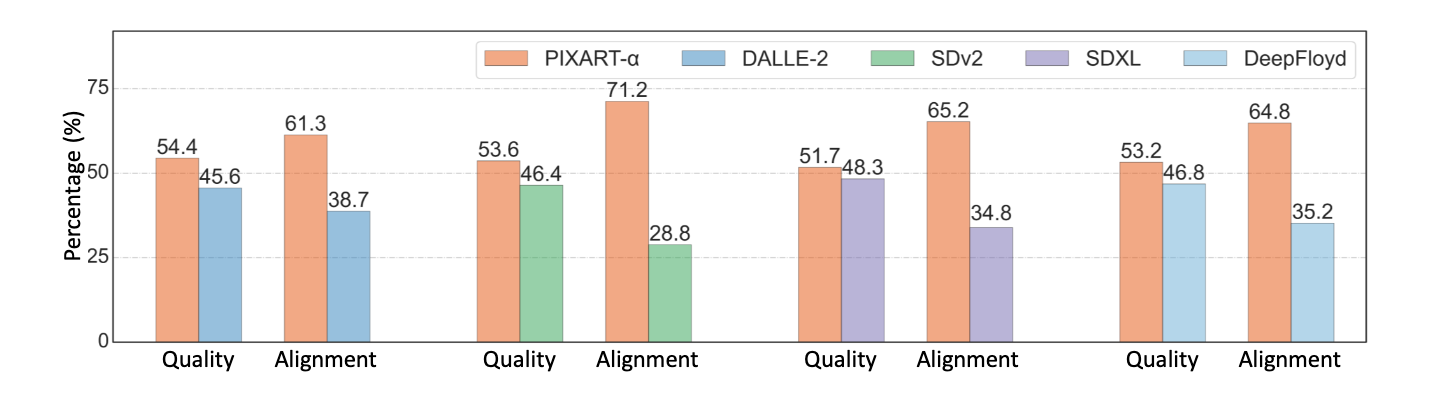
As we will see from the determine above, PixArt Alpha repeatedly outperforms aggressive open supply fashions by way of each picture constancy and text-image alignment. Whereas can not examine it to closed supply fashions like Imagen or RAPHAEL, it stands to cause that their efficiency could be comparable, albeit barely inferior, given what we learn about these fashions.
Convey this challenge to life
Now that we now have gotten the mannequin breakdown out of the best way, we’re prepared to leap proper into the code demo. For this demonstration, we now have offered a pattern Pocket book in Paperspace that may make it straightforward to launch the PixArt Alpha challenge on any Paperspace machine. We suggest extra highly effective machines just like the A100 or A6000 to get quicker outcomes, however the P4000 will generate photographs of equal high quality.
To get began, click on the Run on Paperspace hyperlink above or on the high of the article.
Setup
To setup the applying surroundings as soon as our Pocket book is spun up, all we have to do is run the primary code cell within the demo Pocket book.
!pip set up -r necessities.txt
!pip set up -U transformers speed upIt will set up the entire wanted packages for us, after which replace the transformers and speed up packages. It will guarantee the applying runs easily once we proceed to the subsequent cell and run our software.
Working the modified app
To run the applying from right here, merely scroll the second code cell and execute it.
!python app.pyIt will launch our Gradio software, which has been modified barely from the demo for PixArt Alpha readers might have seen on their Github or HuggingFace web page. Let’s check out what it will probably do, talk about the enhancements we now have added, after which check out some generated samples!
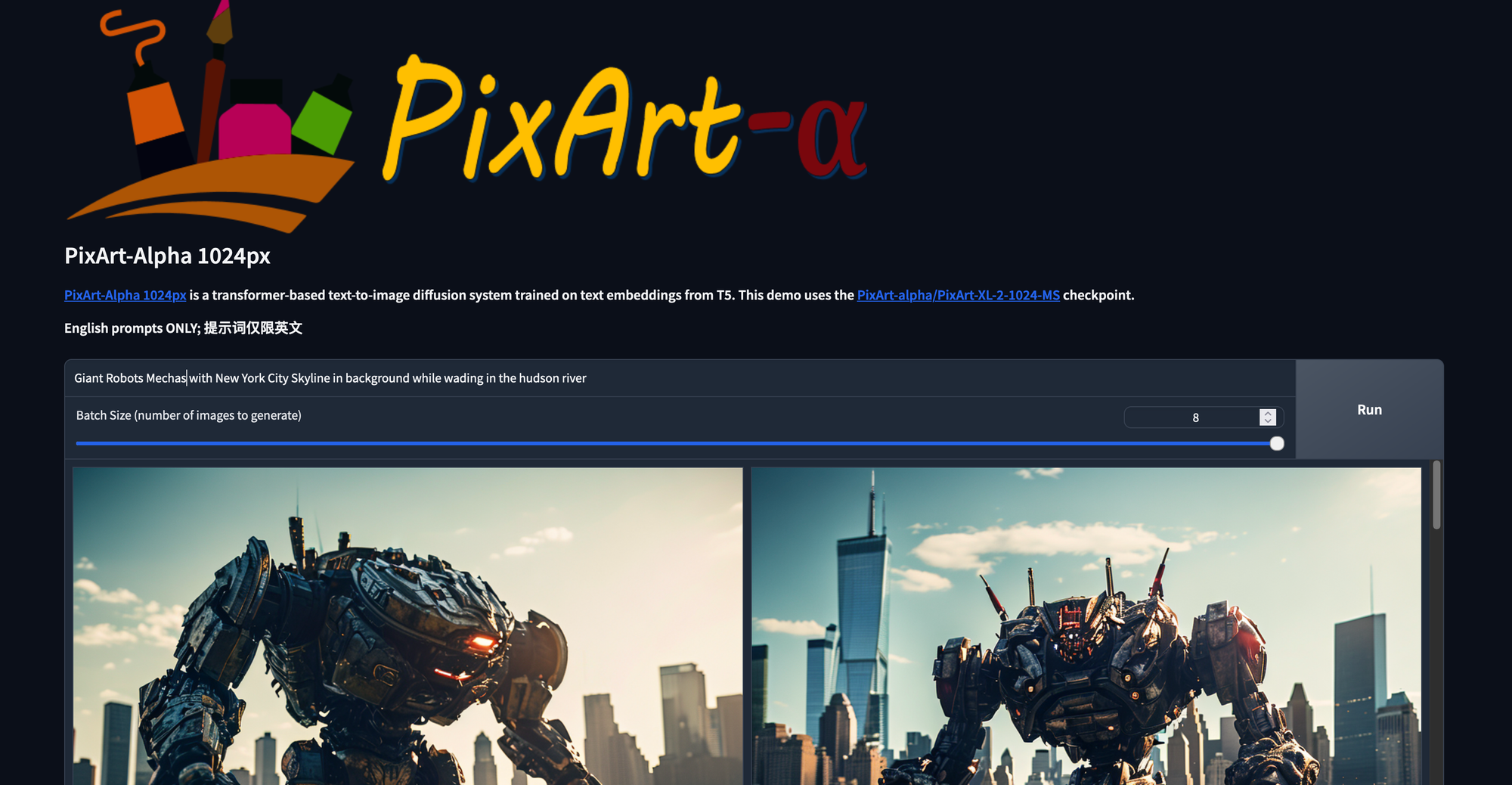
Right here is the principle web page for the online GUI. From right here, we will merely sort in no matter immediate we need and regulate the slider to match the specified variety of outputs. Observe that this resolution will not generate a number of photographs per run of the mannequin, as the present Transformers pipeline appears to solely generated unconditional outputs with a couple of picture generated per run. Nonetheless, we are going to replace the slider to have batch dimension and looping parameters when the pipeline itself can cope with it. For now, that is the best solution to view a number of photographs generated with the identical parameters directly.
We have now additionally adjusted the gallery modal inside to show all of the outputs from a present run. These are then moved to a brand new folder after the run is full.
Within the part under our output, we will discover a dropdown for superior settings. Right here we will do issues like:
- Manually set the seed or set it to be randomized
- Toggle on or off the detrimental immediate, which is able to act like the other of our enter immediate
- Enter the detrimental immediate
- Enter a picture fashion. Kinds will have an effect on the ultimate output, and embrace no fashion, cinematic, photographic, anime, manga, digital artwork, pixel artwork, fantasy artwork, neonpunk, and 3d mannequin types.
- Alter the steerage scale. In contrast to steady diffusion, this worth must be pretty low (beneficial 4.5) to keep away from any artifacting
- Alter variety of diffusion inference steps
Let’s check out some enjoyable examples we made.



Whereas the mannequin nonetheless clearly has some work to be achieved, these outcomes present immense promise for an preliminary launch.
Closing ideas
As proven within the article right this moment, PixArt Alpha represents the primary tangible, open supply competitors to Steady Diffusion to hit the market. We’re keen t see how this challenge continues to develop going ahead, and might be returning this matter shortly to show our readers methods to fine-tune PixArt alpha with Dreambooth!