
{kind=link}
Introduction
On the Google I/O occasion, we noticed many updates and new initiatives. One of many initiatives that caught my consideration is Peligemma. A flexible and light-weight vision-language mannequin (VLM) impressed by PaLI-3 and based mostly on open parts such because the SigLIP imaginative and prescient mannequin and the Gemma language mannequin.
PaliGemma is launched in three forms of fashions: pretrained (pt) fashions, combine fashions, and fine-tuned (ft) fashions, every accessible in numerous resolutions and precisions. The fashions are meant for analysis functions and are outfitted with transformers integration.
PaliGemma’s capabilities embody picture captioning, visible query answering, entity detection, and referring expression segmentation, making it appropriate for a variety of vision-language duties. The mannequin just isn’t designed for conversational use however might be fine-tuned for particular use instances. PaliGemma represents a big development in vision-language fashions and has the potential to revolutionize how know-how interacts with human language.

Understanding PaliGemma
PaliGemma, a state-of-the-art vision-language mannequin developed by Google, combines picture and textual content processing capabilities to generate textual content outputs. The mixed PaliGemma mannequin is pre-trained on image-text knowledge and might course of and generate human-like language with an unbelievable understanding of context and nuance.
Below the Hood
The structure of PaliGemma consists of SigLIP-So400m because the picture encoder and Gemma-2B because the textual content decoder. SigLIP is a state-of-the-art mannequin that may perceive each photographs and textual content and is educated collectively. Much like PaLI-3, the mixed PaliGemma mannequin is pre-trained on image-text knowledge. The enter textual content is tokenized usually, and a <bos> token is added initially, and an extra newline token (n) is appended. The tokenized textual content can be prefixed with a set variety of <picture> tokens. The mannequin makes use of full block consideration for the whole enter (picture + bos + immediate + n), and a causal consideration masks for the generated textual content.
Mannequin Choices for Each Want
The crew at Google has launched three forms of PaliGemma fashions: the pretrained (pt) fashions, the combo fashions, and the fine-tuned (ft) fashions, every with totally different resolutions and accessible in a number of precisions for comfort. The pretrained fashions are designed to be fine-tuned on downstream duties, akin to captioning or referring segmentation. The combo fashions are pretrained fashions fine-tuned to a mix of duties, appropriate for general-purpose inference with free-text prompts and analysis functions solely. The fine-tuned fashions might be configured to unravel particular duties by conditioning them with process prefixes, akin to “detect” or “phase.” PaliGemma is a single-turn imaginative and prescient language mannequin not meant for conversational use, and it really works greatest when fine-tuned to a selected use case.
Additionally learn: The Omniscient GPT-4o + ChatGPT is HERE!
PaliGemma’s Superpowers
PaliGemma’s capabilities span a variety of vision-language duties, making it a flexible and highly effective mannequin in pure language processing and pc imaginative and prescient.
From Picture Captioning to Q&A
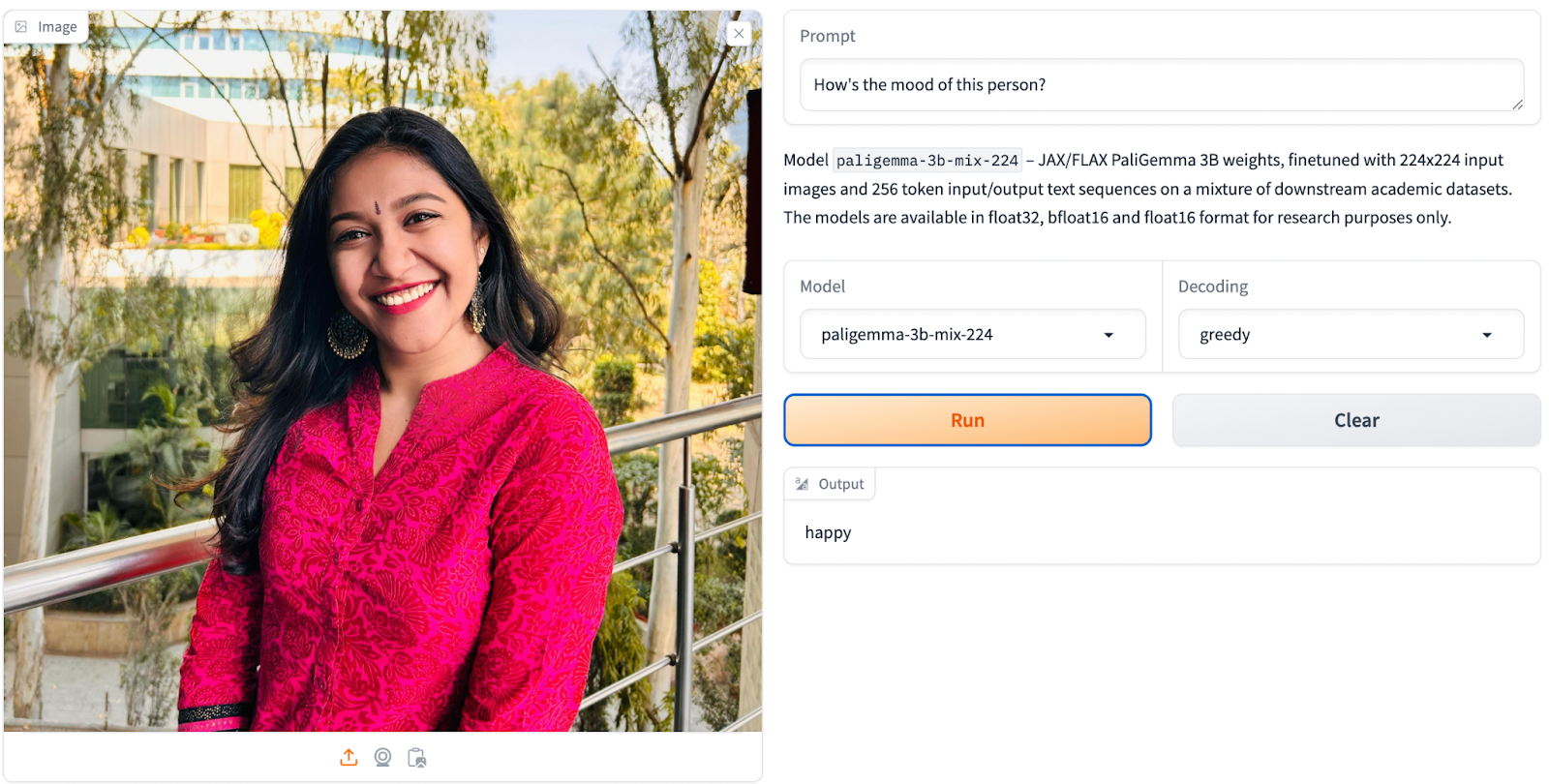
PaliGemma is provided with the power to caption photographs when prompted to take action. It might probably generate descriptive textual content based mostly on the content material of a picture, offering worthwhile insights into its visible content material. Moreover, PaliGemma can reply questions on a picture, demonstrating its proficiency in visible question-answering duties. By passing a query together with a picture, PaliGemma can present related and correct solutions, showcasing its understanding of visible and textual info.
Immediate: “How’s the temper of this particular person?”
Immediate: “Describe the background”
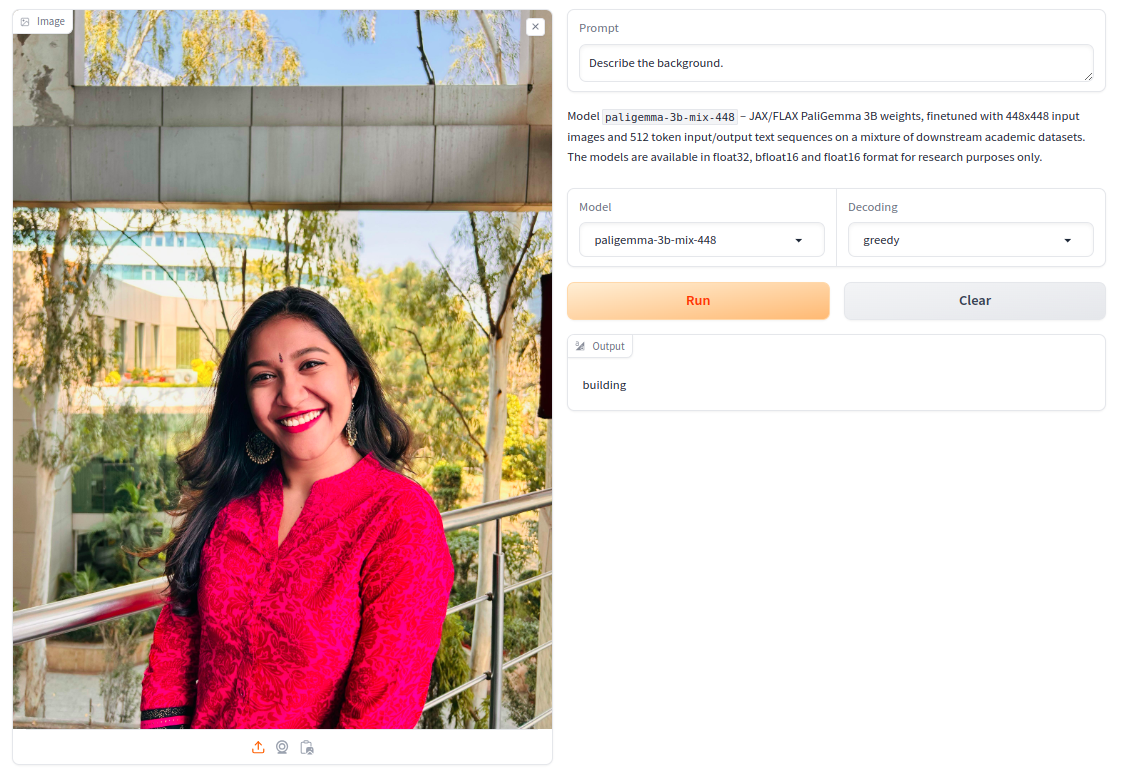
The Energy of Combine Fashions
The combo fashions of PaliGemma have been fine-tuned on a mix of duties, making them appropriate for general-purpose inference with free-text prompts and analysis functions. These fashions are designed to be transferred (by fine-tuning) to particular duties utilizing an identical immediate construction. They provide nice doc understanding and reasoning capabilities, making them worthwhile for vision-language duties. The combo fashions are notably helpful for interactive testing, permitting customers to discover and unlock the total potential of PaliGemma’s capabilities. By leveraging the combo fashions, customers can experiment with numerous captioning prompts and visible question-answering duties to grasp how PaliGemma responds to totally different inputs and prompts.
PaliGemma’s combine fashions usually are not designed for conversational use however might be fine-tuned to particular use instances. They are often configured to unravel particular duties by conditioning them with process prefixes, akin to “detect” or “phase.” The combo fashions are a part of the three fashions launched by the Google crew, together with the pretrained (pt) fashions and the fine-tuned (ft) fashions, every providing totally different resolutions and accessible in a number of precisions for comfort. These fashions have been educated to imbue them with a wealthy set of capabilities, together with question-answering, captioning, segmentation, and extra, making them versatile instruments for numerous vision-language duties.
Additionally learn: How will we use GPT 4o API for Imaginative and prescient, Textual content, Picture, and extra?
Placing PaliGemma to Work
PaliGemma, Google’s cutting-edge vision-language mannequin, presents a variety of capabilities and might be utilized for numerous duties, together with picture captioning, visible query answering, and doc understanding.
Operating Inference with PaliGemma (Transformers & Past)
To run an inference with PaliGemma, the PaliGemmaForConditionalGeneration class can be utilized with any of the launched fashions. The enter textual content is tokenized usually, and a <bos> token is added initially, together with an extra newline token (n). The tokenized textual content can be prefixed with a set variety of <picture> tokens. The mannequin makes use of full block consideration for the whole enter (picture + bos + immediate + n) and a causal consideration masks for the generated textual content. The processor and mannequin lessons robotically deal with these particulars, permitting for inference utilizing the acquainted high-level transformers API.
Fantastic-Tuning PaliGemma for Your Wants
Fantastic-tuning PaliGemma is easy, because of transformers. The mannequin might be simply fine-tuned on downstream duties, akin to captioning or referring segmentation. The discharge contains three fashions: pretrained (pt) fashions, combine fashions, and fine-tuned (ft) fashions, every with totally different resolutions and accessible in a number of precisions for comfort. The combo fashions, fine-tuned on numerous duties, are appropriate for general-purpose inference with free-text prompts and analysis functions. The fine-tuned fashions might be configured to unravel particular duties by conditioning them with process prefixes, akin to “detect” or “phase.” PaliGemma is a single-turn imaginative and prescient language mannequin not meant for conversational use, and it really works greatest when fine-tuned to a selected use case. The big_vision codebase was used to coach PaliGemma, making it a part of a lineage of superior fashions developed by Google.
Additionally learn: GPT-4o vs Gemini: Evaluating Two Highly effective Multimodal AI Fashions
Conclusion
The discharge of PaliGemma marks a big development in vision-language fashions, providing a strong software for researchers and builders. With its potential to grasp photographs and textual content collectively, PaliGemma offers a flexible resolution for a variety of vision-language duties. The mannequin’s structure, consisting of SigLIP-So400m because the picture encoder and Gemma-2B because the textual content decoder, permits it to course of and generate human-like language with a deep understanding of context and nuance. The provision of pretrained (pt) fashions, combine fashions, and fine-tuned (ft) fashions, every with totally different resolutions and precisions, presents flexibility and comfort for numerous use instances. PaliGemma’s potential functions in picture captioning, visible query answering, doc understanding, and extra make it a worthwhile asset for advancing analysis and growth within the AI neighborhood.
I hope you discover this text informative. If in case you have any options or suggestions, remark under. For extra articles like this, discover our weblog part.