{kind=link}

The development of pc imaginative and prescient, a subject mixing machine studying with pc science, has been considerably uplifted by the emergence of deep studying. This text on deep studying for pc imaginative and prescient explores the transformative journey from conventional pc imaginative and prescient strategies to the progressive heights of deep studying. We start with an outline of foundational strategies like thresholding and edge detection and the important position of OpenCV in conventional approaches.
Temporary Historical past and Evolution of Conventional Laptop Imaginative and prescient
Laptop imaginative and prescient, a subject on the intersection of machine studying and pc science, has its roots within the Sixties when researchers first tried to allow computer systems to interpret visible knowledge. The journey started with easy duties like distinguishing shapes and progressed to extra advanced features. Key milestones embody the event of the primary algorithm for digital picture processing within the early Nineteen Seventies and the next evolution of function detection strategies. These early developments laid the groundwork for contemporary pc imaginative and prescient, enabling computer systems to carry out duties starting from object detection to advanced scene understanding.
Core Strategies in Conventional Laptop Imaginative and prescient
Thresholding: This system is prime in picture processing and segmentation. It entails changing a grayscale picture right into a binary picture, the place pixels are marked as both foreground or background primarily based on a threshold worth. As an example, in a primary software, thresholding can be utilized to tell apart an object from its background in a black-and-white picture.
Edge Detection: Vital in function detection and picture evaluation, edge detection algorithms just like the Canny edge detector determine the boundaries of objects inside a picture. By detecting discontinuities in brightness, these algorithms assist perceive the shapes and positions of varied objects within the picture, laying the muse for extra superior evaluation.
The Dominance of OpenCV
OpenCV (Open Supply Laptop Imaginative and prescient Library) is a key participant in pc imaginative and prescient, providing over 2500 optimized algorithms because the late Nineties. Its ease of use and flexibility in duties like facial recognition and visitors monitoring have made it a favourite in academia and trade, particularly in real-time functions.
The sphere of pc imaginative and prescient has developed considerably with the appearance of deep studying, shifting from conventional, rule-based strategies to extra superior and adaptable techniques. Earlier strategies, similar to thresholding and edge detection, had limitations in advanced eventualities. Deep studying, notably Convolutional Neural Networks (CNNs), overcomes these by studying immediately from knowledge, permitting for extra correct and versatile picture recognition and classification.
This development, propelled by elevated computational energy and huge datasets, has led to important breakthroughs in areas like autonomous autos and medical imaging, making deep studying a basic facet of contemporary pc imaginative and prescient.
Deep Studying Fashions:
ResNet-50 for Picture Classification
ResNet-50 is a variant of the ResNet (Residual Community) mannequin, which has been a breakthrough within the subject of deep studying for pc imaginative and prescient, notably in picture classification duties. The “50” in ResNet-50 refers back to the variety of layers within the community – it incorporates 50 layers deep, a major enhance in comparison with earlier fashions.
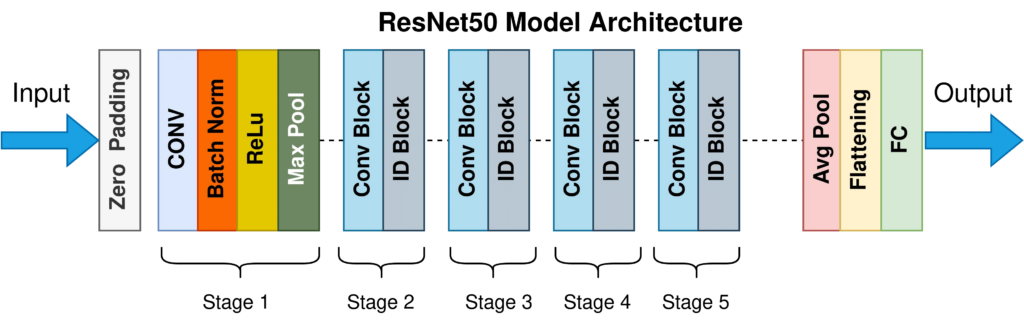
Key Options of ResNet-50:
1. Residual Blocks: The core concept behind ResNet-50 is its use of residual blocks. These blocks permit the mannequin to skip a number of layers via what are often called “skip connections” or “shortcut connections.” This design addresses the vanishing gradient downside, a standard concern in deep networks the place gradients get smaller and smaller as they backpropagate via layers, making it laborious to coach very deep networks.
2. Improved Coaching: Thanks to those residual blocks, ResNet-50 could be educated a lot deeper with out affected by the vanishing gradient downside. This depth permits the community to study extra advanced options at numerous ranges, which is a key think about its improved efficiency in picture classification duties.
3. Versatility and Effectivity: Regardless of its depth, ResNet-50 is comparatively environment friendly when it comes to computational assets in comparison with different deep fashions. It achieves glorious accuracy on numerous picture classification benchmarks like ImageNet, making it a well-liked alternative within the analysis group and trade.
4. Functions: ResNet-50 has been broadly utilized in numerous real-world functions. Its skill to categorise photos into 1000’s of classes makes it appropriate for duties like object recognition in autonomous autos, content material categorization in social media platforms, and aiding diagnostic procedures in healthcare by analyzing medical photos.
Affect on Laptop Imaginative and prescient:
ResNet-50 has considerably superior the sector of picture classification. Its structure serves as a basis for a lot of subsequent improvements in deep studying and pc imaginative and prescient. By enabling the coaching of deeper neural networks, ResNet-50 opened up new potentialities within the accuracy and complexity of duties that pc imaginative and prescient techniques can deal with.
YOLO (You Solely Look As soon as) Mannequin
The YOLO (You Solely Look As soon as) mannequin is a revolutionary strategy within the subject of pc imaginative and prescient, notably for object detection duties. YOLO stands out for its pace and effectivity, making real-time object detection a actuality.
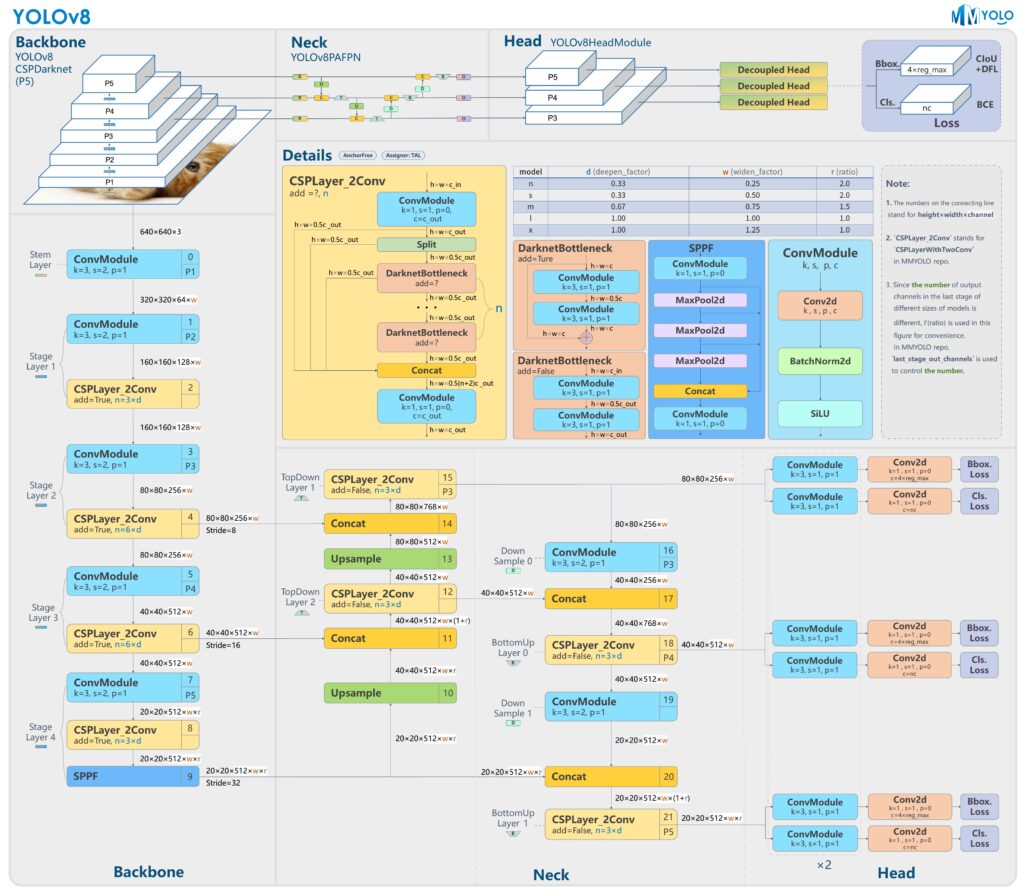
Key Options of YOLO
Single Neural Community for Detection: In contrast to conventional object detection strategies which generally contain separate steps for producing area proposals and classifying these areas, YOLO makes use of a single convolutional neural community (CNN) to do each concurrently. This unified strategy permits it to course of photos in real-time.
Velocity and Actual-Time Processing: YOLO’s structure permits it to course of photos extraordinarily quick, making it appropriate for functions that require real-time detection, similar to video surveillance and autonomous autos.
International Contextual Understanding: YOLO seems to be on the whole picture throughout coaching and testing, permitting it to study and predict with context. This world perspective helps in lowering false positives in object detection.
Model Evolution: Latest iterations similar to YOLOv5, YOLOv6, YOLOv7, and the newest YOLOv8, have launched important enhancements. These newer fashions give attention to refining the structure with extra layers and superior options, enhancing their efficiency in numerous real-world functions.
Affect on Laptop Imaginative and prescient
YOLO’s contribution to the sector of deep studying for pc imaginative and prescient has been important. Its skill to carry out object detection in real-time, precisely, and effectively has opened up quite a few potentialities for sensible functions that had been beforehand restricted by slower detection speeds. Its evolution over time additionally displays the speedy development and innovation throughout the subject of deep studying in pc imaginative and prescient.
Actual-World Functions of YOLO
Site visitors Administration and Surveillance Programs: A pertinent real-world software of the YOLO mannequin is within the area of visitors administration and surveillance techniques. This software showcases the mannequin’s skill to course of visible knowledge in actual time, a important requirement for managing and monitoring city visitors circulate.
Implementation in Site visitors Surveillance: Automobile and Pedestrian Detection – YOLO is employed to detect and observe autos and pedestrians in real-time via visitors cameras. Its skill to course of video feeds rapidly permits for the rapid identification of several types of autos, pedestrians, and even anomalies like jaywalking.
Site visitors Stream Evaluation: By repeatedly monitoring visitors, YOLO helps in analyzing visitors patterns and densities. This knowledge can be utilized to optimize visitors gentle management, lowering congestion and bettering visitors circulate.
Accident Detection and Response: The mannequin can detect potential accidents or uncommon occasions on roads. In case of an accident, it might probably alert the involved authorities promptly, enabling quicker emergency response.
Enforcement of Site visitors Guidelines: YOLO may also help in implementing visitors guidelines by detecting violations like dashing, unlawful lane modifications, or operating pink lights. Automated ticketing techniques could be built-in with YOLO to streamline enforcement procedures.
Imaginative and prescient Transformers
This mannequin applies the ideas of transformers, initially designed for pure language processing, to picture classification and detection duties. It entails splitting a picture into fixed-size patches, embedding these patches, including positional info, after which feeding them right into a transformer encoder.
The mannequin makes use of a mix of Multi-head Consideration Networks and Multi-Layer Perceptrons inside its structure to course of these picture patches and carry out classification.
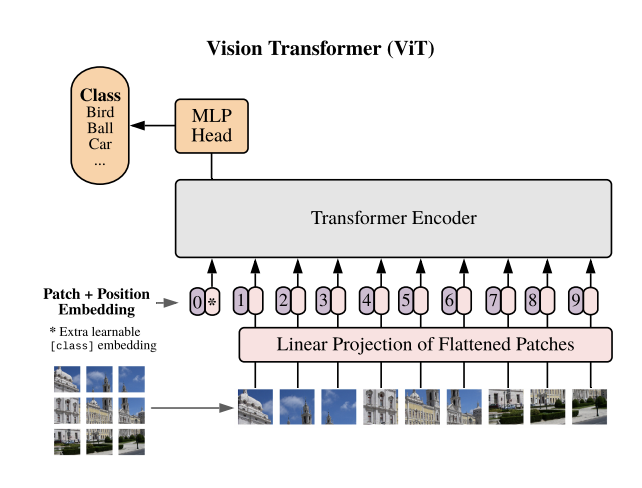
Key Options
Patch-based Picture Processing: ViT divides a picture into patches and linearly embeds them, treating the picture as a sequence of patches.
Positional Embeddings: To keep up the spatial relationship of picture components, positional embeddings are added to the patch embeddings.
Multi-head Consideration Mechanism: It makes use of a multi-head consideration community to give attention to important areas throughout the picture and perceive the relationships between totally different patches.
Layer Normalization: This function ensures secure coaching by normalizing the inputs throughout the layers.
Multilayer Perceptron (MLP) Head: The ultimate stage of the ViT mannequin, the place the outputs of the transformer encoder are processed for classification.
Class Embedding: ViT features a learnable class embedding, enhancing its functionality to categorise photos precisely.
Affect on Laptop Imaginative and prescient
Enhanced Accuracy and Effectivity: ViT fashions have demonstrated important enhancements in accuracy and computational effectivity over conventional CNNs in picture classification.
Adaptability to Completely different Duties: Past picture classification, ViTs are successfully utilized in object detection, picture segmentation, and different advanced imaginative and prescient duties.
Scalability: The patch-based strategy and a spotlight mechanism make ViT scalable for processing massive and sophisticated photos.
Revolutionary Method: By making use of the transformer structure to photographs, ViT represents a paradigm shift in how machine studying fashions understand and course of visible info.
The Imaginative and prescient Transformer marks a major development within the subject of pc imaginative and prescient, providing a strong different to traditional CNNs and paving the best way for extra refined picture evaluation strategies.
Imaginative and prescient Transformers (ViTs) are more and more being utilized in a wide range of real-world functions throughout totally different fields as a consequence of their effectivity and accuracy in dealing with advanced picture knowledge.
Actual World Functions
Picture Classification and Object Detection: ViTs are extremely efficient in picture classification, categorizing photos into predefined courses by studying intricate patterns and relationships throughout the picture. In object detection, they not solely classify objects inside a picture but in addition localize their positions exactly. This makes them appropriate for functions in autonomous driving and surveillance, the place correct detection and positioning of objects are essential.
Picture Segmentation: In picture segmentation, ViTs divide a picture into significant segments or areas. They excel in discerning fine-grained particulars inside a picture and precisely delineating object boundaries. This functionality is especially worthwhile in medical imaging, the place exact segmentation can support in diagnosing ailments and circumstances.
Motion Recognition: ViTs are being utilized in motion recognition to know and classify human actions in movies. Their sturdy picture processing capabilities, makes them helpful in areas similar to video surveillance and human-computer interplay.
Generative Modeling and Multi-Modal Duties: ViTs have functions in generative modeling and multi-modal duties, together with visible grounding (linking textual descriptions to corresponding picture areas), visual-question answering, and visible reasoning. This displays their versatility in integrating visible and textual info for complete evaluation and interpretation.
Switch Studying: An vital function of ViTs is their capability for switch studying. By leveraging pre-trained fashions on massive datasets, ViTs could be fine-tuned for particular duties with comparatively small datasets. This considerably reduces the necessity for intensive labeled knowledge, making ViTs sensible for a variety of functions.
Industrial Monitoring and Inspection: In a sensible software, the DINO pre-trained ViT was built-in into Boston Dynamics’ Spot robotic for monitoring and inspection of commercial websites. This software showcased the flexibility of ViTs to automate duties like studying measurements from industrial processes and taking data-driven actions, demonstrating their utility in advanced, real-world environments.
Steady Diffusion V2: Key Options and Affect on Laptop Imaginative and prescient

Key Options of Steady Diffusion V2
Superior Textual content-to-Picture Fashions: Steady Diffusion V2 incorporates sturdy text-to-image fashions, using a brand new textual content encoder (OpenCLIP) that enhances the standard of generated photos. These fashions can produce photos with resolutions like 512×512 pixels and 768×768 pixels, providing important enhancements over earlier variations.
Tremendous-resolution Upscaler: A notable addition in V2 is the Upscaler Diffusion mannequin that may enhance the decision of photos by an element of 4. This function permits for changing low-resolution photos into a lot higher-resolution variations, as much as 2048×2048 pixels or extra when mixed with text-to-image fashions.
Depth-to-Picture Diffusion Mannequin: This new mannequin, often called depth2img, extends the image-to-image function from the sooner model. It will probably infer the depth of an enter picture after which generate new photos utilizing each textual content and depth info. This function opens up potentialities for inventive functions in structure-preserving image-to-image and shape-conditional picture synthesis.
Enhanced Inpainting Mannequin: Steady Diffusion V2 contains an up to date text-guided inpainting mannequin, permitting for clever and fast modification of components of a picture. This makes it simpler to edit and improve photos with excessive precision.
Optimized for Accessibility: The mannequin is optimized to run on a single GPU, making it extra accessible to a wider vary of customers. This optimization displays a dedication to democratizing entry to superior AI applied sciences.
Affect on Laptop Imaginative and prescient
Revolutionizing Picture Era: Steady Diffusion V2’s enhanced capabilities in producing high-quality, high-resolution photos from textual descriptions signify a leap ahead in computer-generated imagery. This opens new avenues in numerous fields like digital artwork, graphic design, and content material creation.
Facilitating Inventive Functions: With options like depth-to-image and upscaling, Steady Diffusion V2 permits extra advanced and inventive functions. Artists and designers can experiment with depth info and high-resolution outputs, pushing the boundaries of digital creativity.
Enhancing Picture Enhancing and Manipulation: The superior inpainting capabilities of Steady Diffusion V2 permit for extra refined picture modifying and manipulation. This will have sensible functions in fields like promoting, the place fast and clever picture modifications are sometimes required.
Enhancing Accessibility and Collaboration: By optimizing the mannequin for single GPU use, Steady Diffusion V2 turns into accessible to a broader viewers. This democratization may result in extra collaborative and progressive makes use of of AI in visible duties, fostering a community-driven strategy to AI growth.
Setting a New Benchmark in AI: Steady Diffusion V2’s mixture of superior options and accessibility might set new requirements within the AI and pc imaginative and prescient group, encouraging additional improvements and functions in these fields.
Actual-world Functions:
Medical and Well being Schooling: MultiMed, a well being know-how firm, makes use of Steady Diffusion know-how to offer accessible and correct medical steerage and public well being training in a number of languages.
Audio Transcription and Picture Era: AudioSonic venture transforms audio narratives into photos, enhancing the listening expertise with corresponding visuals.
Inside Design: An internet software makes use of Steady Diffusion to empower people with AI in dwelling design, permitting prospects to create and visualize inside designs rapidly and effectively.
Comedian E book Manufacturing: AI-Comedian-Manufacturing facility combines Falcon AI and SDXL know-how with Steady Diffusion to revolutionize comedian ebook manufacturing, enhancing each narratives and visuals.
Instructional Summarization Software: Summerize, an online software, gives structured info retrieval and summarization from on-line articles, together with related picture prompts, aiding analysis and displays.
Interactive Storytelling in Gaming: SonicVision integrates generative music and dynamic artwork with storytelling, creating an immersive gaming expertise.
Cooking and Recipe Era: DishForge makes use of Steady Diffusion to visualise substances and generate customized recipes primarily based on person preferences and dietary wants.
Advertising and marketing and Promoting: EvoMate, an autonomous advertising and marketing agent, creates focused campaigns and content material, leveraging Steady Diffusion for content material creation.
Podcast Truth-Checking and Media Enhancement: TrueCast makes use of AI algorithms for real-time fact-checking and media presentation throughout stay podcasts.
Private AI Assistants: Initiatives like Shadow AI and BlaBlaLand use Steady Diffusion for producing related photos and creating immersive, customized AI interactions.
3D Meditation and Studying Platforms: Functions like 3D Meditation and PhenoVis make the most of Steady Diffusion for creating immersive meditation experiences and academic 3D simulations.
AI in Medical Schooling: Affected person Simulator aids medical professionals in practising affected person interactions, utilizing Steady Diffusion for enhanced communication and coaching.
Promoting Manufacturing Effectivity: ADS AI goals to enhance promoting manufacturing time by utilizing AI applied sciences, together with Steady Diffusion, for inventive product picture and content material technology.
Inventive Content material and World Constructing: Platforms like Text2Room and The Universe use Steady Diffusion for producing 3D content material and immersive sport worlds.
Enhanced On-line Conferences: Baatcheet.AI revolutionizes on-line conferences with voice cloning and AI-generated backgrounds, bettering focus and communication effectivity.
These functions exhibit the flexibility and potential of Steady Diffusion V2 in enhancing numerous industries by offering progressive options to advanced issues.
Standard Frameworks – PyTorch and Keras
PyTorch

Developed by Fb’s AI Analysis lab, PyTorch is an open-source machine studying library. It’s identified for its flexibility, ease of use, and native help for dynamic computation graphs, which makes it notably appropriate for analysis and prototyping. PyTorch additionally offers sturdy help for GPU acceleration, which is important for coaching massive neural networks effectively.
Checkout: Getting began with Pytorch.
Keras

Keras, now built-in with TensorFlow (Google’s AI framework), is a high-level neural networks API designed for simplicity and ease of use. Initially developed as an impartial venture, Keras focuses on enabling quick experimentation and prototyping via its user-friendly interface. It helps all of the important options wanted for constructing deep studying fashions however abstracts away most of the advanced particulars, making it very accessible for freshmen.
Checkout: Getting began with Keras
Each frameworks are extensively utilized in each tutorial and industrial settings for a wide range of machine studying and AI functions, from easy regression fashions to advanced deep neural networks.
PyTorch is usually most popular for analysis and growth as a consequence of its flexibility, whereas Keras is favored for its simplicity and ease of use, particularly for freshmen.
Conclusion: The Ever-Evolving Panorama of AI Fashions
As we glance in the direction of the way forward for AI and machine studying, it’s essential to acknowledge that one mannequin doesn’t match all. Even a decade from now, we would nonetheless see using basic fashions like ResNet alongside modern ones like Imaginative and prescient Transformers or Steady Diffusion V2.
The sphere of AI is characterised by steady evolution and innovation. It reminds us that the instruments and fashions we use should adapt and diversify to satisfy the ever-changing calls for of know-how and society.