{kind=link}
Editor’s word: This submit is a part of the AI Decoded collection, which demystifies AI by making the expertise extra accessible, and showcases new {hardware}, software program, instruments and accelerations for RTX PC customers.
The period of the AI PC is right here, and it’s powered by NVIDIA RTX and GeForce RTX applied sciences. With it comes a brand new option to consider efficiency for AI-accelerated duties, and a brand new language that may be formidable to decipher when selecting between the desktops and laptops out there.
Whereas PC avid gamers perceive frames per second (FPS) and comparable stats, measuring AI efficiency requires new metrics.
Coming Out on TOPS
The primary baseline is TOPS, or trillions of operations per second. Trillions is the vital phrase right here — the processing numbers behind generative AI duties are completely large. Consider TOPS as a uncooked efficiency metric, much like an engine’s horsepower score. Extra is best.
Examine, for instance, the lately introduced Copilot+ PC lineup by Microsoft, which incorporates neural processing models (NPUs) in a position to carry out upwards of 40 TOPS. Performing 40 TOPS is ample for some gentle AI-assisted duties, like asking an area chatbot the place yesterday’s notes are.
However many generative AI duties are extra demanding. NVIDIA RTX and GeForce RTX GPUs ship unprecedented efficiency throughout all generative duties — the GeForce RTX 4090 GPU affords greater than 1,300 TOPS. That is the type of horsepower wanted to deal with AI-assisted digital content material creation, AI tremendous decision in PC gaming, producing pictures from textual content or video, querying native giant language fashions (LLMs) and extra.
Insert Tokens to Play
TOPS is barely the start of the story. LLM efficiency is measured within the variety of tokens generated by the mannequin.
Tokens are the output of the LLM. A token is usually a phrase in a sentence, or perhaps a smaller fragment like punctuation or whitespace. Efficiency for AI-accelerated duties may be measured in “tokens per second.”
One other vital issue is batch dimension, or the variety of inputs processed concurrently in a single inference move. As an LLM will sit on the core of many fashionable AI methods, the power to deal with a number of inputs (e.g. from a single software or throughout a number of purposes) will likely be a key differentiator. Whereas bigger batch sizes enhance efficiency for concurrent inputs, in addition they require extra reminiscence, particularly when mixed with bigger fashions.
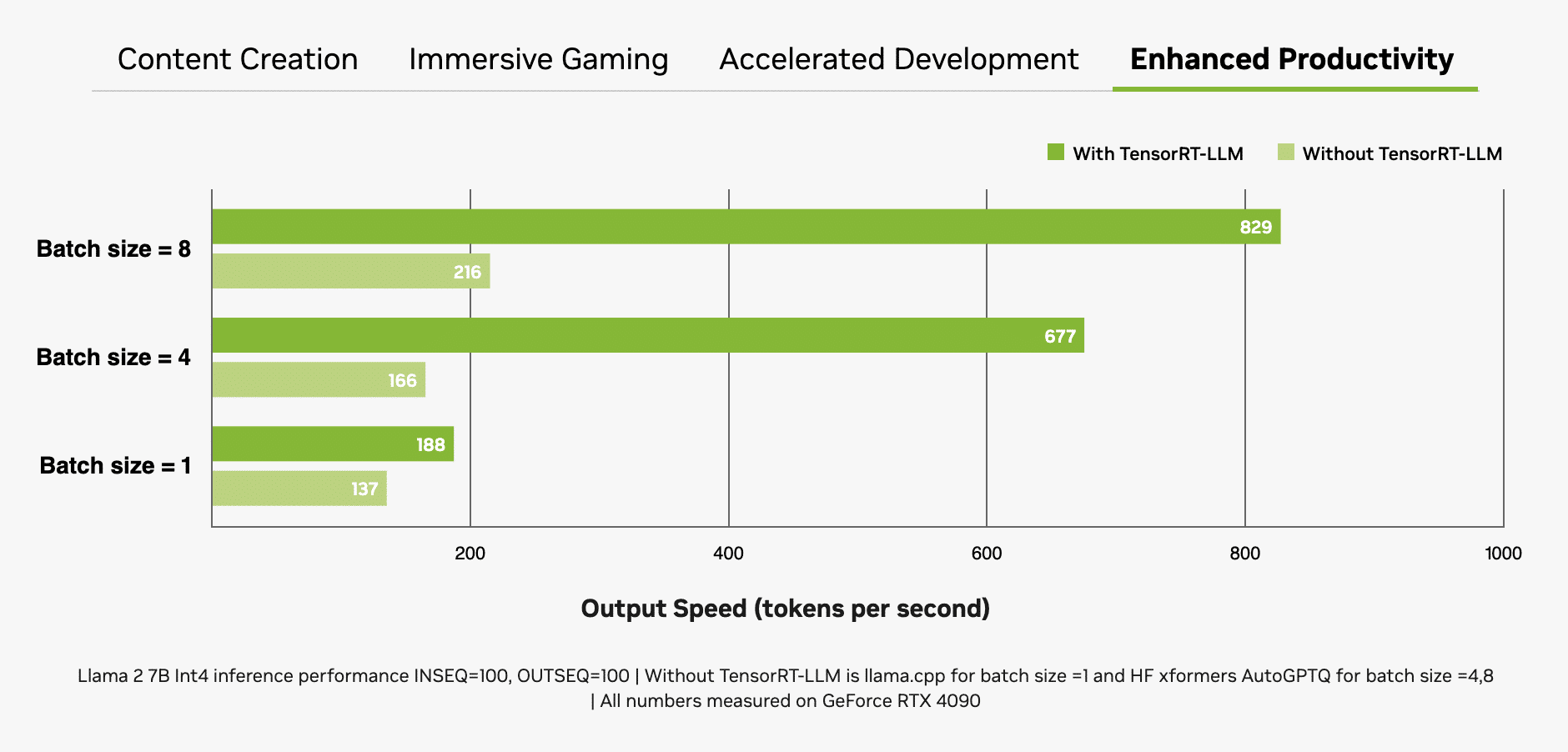
RTX GPUs are exceptionally well-suited for LLMs attributable to their giant quantities of devoted video random entry reminiscence (VRAM), Tensor Cores and TensorRT-LLM software program.
GeForce RTX GPUs provide as much as 24GB of high-speed VRAM, and NVIDIA RTX GPUs as much as 48GB, which may deal with bigger fashions and allow larger batch sizes. RTX GPUs additionally make the most of Tensor Cores — devoted AI accelerators that dramatically pace up the computationally intensive operations required for deep studying and generative AI fashions. That most efficiency is definitely accessed when an software makes use of the NVIDIA TensorRT software program growth package (SDK), which unlocks the highest-performance generative AI on the greater than 100 million Home windows PCs and workstations powered by RTX GPUs.
The mixture of reminiscence, devoted AI accelerators and optimized software program provides RTX GPUs large throughput positive aspects, particularly as batch sizes improve.
Textual content-to-Picture, Sooner Than Ever
Measuring picture era pace is one other option to consider efficiency. One of the easy methods makes use of Steady Diffusion, a well-liked image-based AI mannequin that permits customers to simply convert textual content descriptions into advanced visible representations.
With Steady Diffusion, customers can rapidly create and refine pictures from textual content prompts to realize their desired output. When utilizing an RTX GPU, these outcomes may be generated sooner than processing the AI mannequin on a CPU or NPU.
That efficiency is even larger when utilizing the TensorRT extension for the favored Automatic1111 interface. RTX customers can generate pictures from prompts as much as 2x sooner with the SDXL Base checkpoint — considerably streamlining Steady Diffusion workflows.
ComfyUI, one other well-liked Steady Diffusion person interface, added TensorRT acceleration final week. RTX customers can now generate pictures from prompts as much as 60% sooner, and may even convert these pictures to movies utilizing Steady Video Diffuson as much as 70% sooner with TensorRT.
TensorRT acceleration may be put to the check within the new UL Procyon AI Picture Era benchmark, which delivers speedups of fifty% on a GeForce RTX 4080 SUPER GPU in contrast with the quickest non-TensorRT implementation.
TensorRT acceleration will quickly be launched for Steady Diffusion 3 — Stability AI’s new, extremely anticipated text-to-image mannequin — boosting efficiency by 50%. Plus, the brand new TensorRT-Mannequin Optimizer allows accelerating efficiency even additional. This leads to a 70% speedup in contrast with the non-TensorRT implementation, together with a 50% discount in reminiscence consumption.
In fact, seeing is believing — the true check is within the real-world use case of iterating on an unique immediate. Customers can refine picture era by tweaking prompts considerably sooner on RTX GPUs, taking seconds per iteration in contrast with minutes on a Macbook Professional M3 Max. Plus, customers get each pace and safety with the whole lot remaining personal when operating domestically on an RTX-powered PC or workstation.
The Outcomes Are in and Open Sourced
However don’t simply take our phrase for it. The staff of AI researchers and engineers behind the open-source Jan.ai lately built-in TensorRT-LLM into its native chatbot app, then examined these optimizations for themselves.
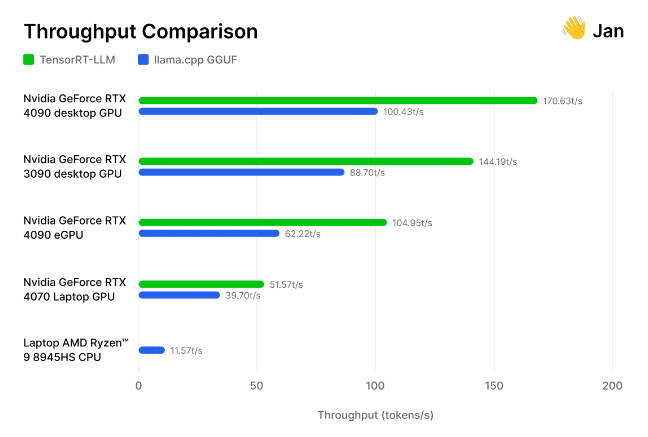
The researchers examined its implementation of TensorRT-LLM in opposition to the open-source llama.cpp inference engine throughout quite a lot of GPUs and CPUs utilized by the group. They discovered that TensorRT is “30-70% sooner than llama.cpp on the identical {hardware},” in addition to extra environment friendly on consecutive processing runs. The staff additionally included its methodology, inviting others to measure generative AI efficiency for themselves.
From video games to generative AI, pace wins. TOPS, pictures per second, tokens per second and batch dimension are all issues when figuring out efficiency champs.
Generative AI is reworking gaming, videoconferencing and interactive experiences of all types. Make sense of what’s new and what’s subsequent by subscribing to the AI Decoded e-newsletter.