
{kind=link}
Introduction
Deliver this venture to life
Massive-scale Textual content-to-Picture (T2I) fashions, like Secure Diffusion, have gained fast prominence in inventive domains, producing visually fascinating outputs primarily based on textual prompts. Regardless of their success, making certain a constant type management stays a problem, typically requiring fine-tuning and handbook intervention to separate content material and elegance. The paper “StyleAligned Picture Era by way of Shared Consideration” introduces StyelAligned, a novel approach geared toward establishing type alignment inside a sequence of generated photos. By minimal ‘consideration sharing’ in the course of the diffusion course of, the primary strategy maintains type consistency in T2I fashions. This permits the creation of style-consistent photos utilizing a reference type via a easy inversion operation. Analysis throughout various types and textual content prompts showcases the strategy’s effectiveness, highlighting its skill to attain constant type throughout a spread of inputs with high-quality synthesis and constancy.

This strategy eliminates the necessity for optimization and is relevant to any attention-based text-to-image diffusion mannequin. The unique analysis paper demonstrates that incorporating minimal consideration sharing operations all through the diffusion course of, from every generated picture to the preliminary one in a batch, ends in a style-consistent set. Moreover, via diffusion inversion, this methodology can generate style-consistent photos primarily based on a reference type picture, requiring no optimization or fine-tuning.
Key advantages of this strategy
There have been a number of research centered on textual content conditioned picture generative fashions, and these research have been profitable in producing top quality picture from the given immediate. In diffusion fashions, Hertz et al. demonstrated the affect of cross and self-attention maps on shaping the structure and content material of the generated photos in the course of the diffusion course of. Right here we focus on few of the important thing advantages of this strategy:
- This strategy excels in producing photos with varied constructions and content material, which is kind of totally different from the entire earlier strategies. So as to add extra this strategy preserves the constant type interpretation.
- A really shut strategy to this examine is StyleDrop, which may generate a constant set of photos with out the optimization part. Additionally, this strategy doesn’t depend on a number of photos of coaching. To make sure this, the strategy entails the creation of customized encoders devoted to injecting new priors instantly into T2I fashions utilizing a single enter picture. Nevertheless, these strategies face challenges in separating type from content material, as their focus is on producing the identical topic as introduced within the enter picture. This difficulty is tackled within the type alignment strategy.
- The qualitative comparability with StyleDrop (SDXL), StyleDrop (unofficial implementation of MUSE unofficial), and Dreambooth-LoRA (SDXL) was performed on this analysis. It was discovered that the photographs generated with this methodology are way more constant throughout the types corresponding to coloration palette, drawing type, composition, and pose.
- A consumer examine was performed utilizing StyleAligned, StyleDrop, and DreamBooth. The consumer had been proven 4 photos from the above strategies and it was discovered that almost all favored StyleAligned by way of type consistency, and textual content alignment.
- StyleAligned addresses the challenges of reaching picture technology inside the realm of huge scale T2I fashions. That is achieved utilizing minimal consideration sharing operations with AdaIN modulation in the course of the diffusion course of. This methodology has been able to establishing style-consistency and visible coherence throughout generated photos.
Now that we have now mentioned the capabilities of StyleAligned, allow us to stroll via establishing the platform to run this mannequin efficiently and discover the capabilities utilizing Paperspace GPUs.
StyleAligned demo on Paperspace
Working the demo on Paperspace is comparatively easy. To begin, click on the hyperlink supplied on this article, which can spin up the pocket book on Paperspace. We’re supplied with 5 notebooks which embody:
- style_aligned_sd1 pocket book for producing StyleAligned photos utilizing sd.
- style_aligned_sdxl pocket book for producing StyleAligned photos utilizing SDXL.
- style_aligned_transfer_sdxl pocket book for producing photos with a method from reference picture utilizing SDXL.
- style_aligned_w_controlnet pocket book for producing StyleAligned and depth conditioned photos utilizing SDXL with ControlNet-Depth.
- style_aligned_w_multidiffusion can be utilized for producing StyleAligned panoramas utilizing SD V2 with MultiDiffusion.
So as to add extra we have now supplied a helper.ipynb pocket book that facilitates the short launch of the Gradio app in your browser.
Setup
Deliver this venture to life
With that finished, we will get began with our first pocket book style_aligned_sd1.ipynb. This pocket book consists of all of the code that may help you generate the photographs.
- Run the primary cell, this may begin the set up course of for the required libraries.
#Set up the libraries utilizing pip
!pip set up -r necessities.txt
!pip set up -U transformers diffusers
!pip set up -y torch torchvision torchaudio
!pip3 set up torch torchvision torchaudio --index-url https://obtain.pytorch.org/whl/cu121
!python3 -m pip set up torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://obtain.pytorch.org/whl/cu117
This code cell will set up all the pieces wanted to run StyleAligned within the pocket book. As soon as all of the packages are put in run all of the cells supplied within the pocket book.
- StyleAligned utilizing secure diffusion to generate photos.
from diffusers import DDIMScheduler,StableDiffusionPipeline
import torch
import mediapy
import sa_handler
import math
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False,
set_alpha_to_one=False)
pipeline = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
scheduler=scheduler
)
pipeline = pipeline.to("cuda")
handler = sa_handler.Handler(pipeline)
sa_args = sa_handler.StyleAlignedArgs(share_group_norm=True,
share_layer_norm=True,
share_attention=True,
adain_queries=True,
adain_keys=True,
adain_values=False,
)
handler.register(sa_args, )
# run StyleAligned
sets_of_prompts = [
"a toy train. macro photo. 3d game asset",
"a toy airplane. macro photo. 3d game asset",
"a toy bicycle. macro photo. 3d game asset",
"a toy car. macro photo. 3d game asset",
"a toy boat. macro photo. 3d game asset",
]
photos = pipeline(sets_of_prompts, generator=None).photos
mediapy.show_images(photos)This code will arrange the diffusion mannequin with a particular scheduler, configure a StyleAligned handler, register the handler by passing sure arguments, after which use the diffusion pipeline to generate photos primarily based on a set of prompts and show the outcomes.

- ControlNet depth with StyleAligned over SDXL
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline, AutoencoderKL
from diffusers.utils import load_image
from transformers import DPTImageProcessor, DPTForDepthEstimation
import torch
import mediapy
import sa_handler
import pipeline_calls
# init fashions
#This code units up a depth estimation mannequin, a management web mannequin, a #variational autoencoder (VAE), and a diffusion pipeline with StyleAligned #configuration.
depth_estimator = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to("cuda")
feature_processor = DPTImageProcessor.from_pretrained("Intel/dpt-hybrid-midas")
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-depth-sdxl-1.0",
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16).to("cuda")
pipeline = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
pipeline.enable_model_cpu_offload()
sa_args = sa_handler.StyleAlignedArgs(share_group_norm=False,
share_layer_norm=False,
share_attention=True,
adain_queries=True,
adain_keys=True,
adain_values=False,
)
handler = sa_handler.Handler(pipeline)
handler.register(sa_args, )Allow us to break down the code for a greater understanding:
depth_estimator: An occasion of a depth estimation mannequin is (DPTForDepthEstimation) loaded from a pre-trained mannequin (“Intel/dpt-hybrid-midas”), and moved to the CUDA gadget.feature_processor: An occasion of a picture processor (DPTImageProcessor) loaded from a pre-trained mannequin (“Intel/dpt-hybrid-midas”).controlnet: An occasion of a management web mannequin (ControlNetModel) loaded from a pre-trained mannequin (“diffusers/controlnet-depth-sdxl-1.0”). It makes use of mixed-precision (“fp16”) and is configured to make use of secure tensors.vae: An occasion of an autoencoder with KL divergence (AutoencoderKL) loaded from a pre-trained mannequin (“madebyollin/sdxl-vae-fp16-fix”).- Subsequent, the diffusion pipeline is (
StableDiffusionXLControlNetPipeline) loaded from a pre-trained mannequin (“stabilityai/stable-diffusion-xl-base-1.0”). - StyleAligned Handler Setup:
sa_args: Configuration arguments for the StyleAligned strategy, specifying choices corresponding to consideration sharing and AdaIN settings.
handler: An occasion of a StyleAligned handler (sa_handler.Handler) created with the configured diffusion pipeline. The handler is then registered with the required StyleAligned arguments.
The code units up the pipeline for picture processing, depth estimation, management web modeling, and diffusion-based picture technology with StyleAligned configuration. The fashions used listed below are pre-trained fashions and all the pipeline is configured for environment friendly computation on a CUDA gadget with mixed-precision assist.
As soon as this code runs efficiently transfer to the subsequent line of code. These strains of code load two photos from the instance folder. The pictures are processed via the depth estimator pipeline, after which the ensuing depth maps utilizing the mediapy library are displayed. It gives a visible illustration of the depth data inferred from the enter photos.
picture = load_image("./example_image/practice.png")
depth_image1 = pipeline_calls.get_depth_map(picture, feature_processor, depth_estimator)
depth_image2 = load_image("./example_image/solar.png").resize((1024, 1024))
mediapy.show_images([depth_image1, depth_image2])
# run ControlNet depth with StyleAligned
reference_prompt = "a poster in flat design type"
target_prompts = ["a train in flat design style", "the sun in flat design style"]
controlnet_conditioning_scale = 0.8
num_images_per_prompt = 3 # modify in keeping with VRAM measurement
latents = torch.randn(1 + num_images_per_prompt, 4, 128, 128).to(pipeline.unet.dtype)
for deph_map, target_prompt in zip((depth_image1, depth_image2), target_prompts):
latents[1:] = torch.randn(num_images_per_prompt, 4, 128, 128).to(pipeline.unet.dtype)
photos = pipeline_calls.controlnet_call(pipeline, [reference_prompt, target_prompt],
picture=deph_map,
num_inference_steps=50,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_images_per_prompt=num_images_per_prompt,
latents=latents)
mediapy.show_images([images[0], deph_map] + photos[1:], titles=["reference", "depth"] + [f'result {i}' for i in range(1, len(images))])This code block generates photos utilizing the ControlNet mannequin conditioned on a reference immediate, goal prompts, and depth maps. The outcomes are then visualized utilizing the mediapy library.

We extremely suggest customers experiment with the notebooks supplied to raised perceive the mannequin and synthesize photos.
Launching the Gradio Software
Now we have included a helper.ipynb pocket book which can launch the gradio software in your browser.
- Begin by putting in the required packages
!pip set up gradio
!pip set up -r necessities.txt
!pip set up -U transformers diffusers
!pip set up -y torch torchvision torchaudio
!pip3 set up torch torchvision torchaudio --index-url https://obtain.pytorch.org/whl/cu121- Launch the gradio software
!sed 's/.launch()/.launch(share=True)/' -i /notebooks/demo_stylealigned_sdxl.py
!python demo_stylealigned_sdxl.py 
The very first thing we will do is to check out some prompts to check the picture generations utilizing the StyleAligned SDXL mannequin.
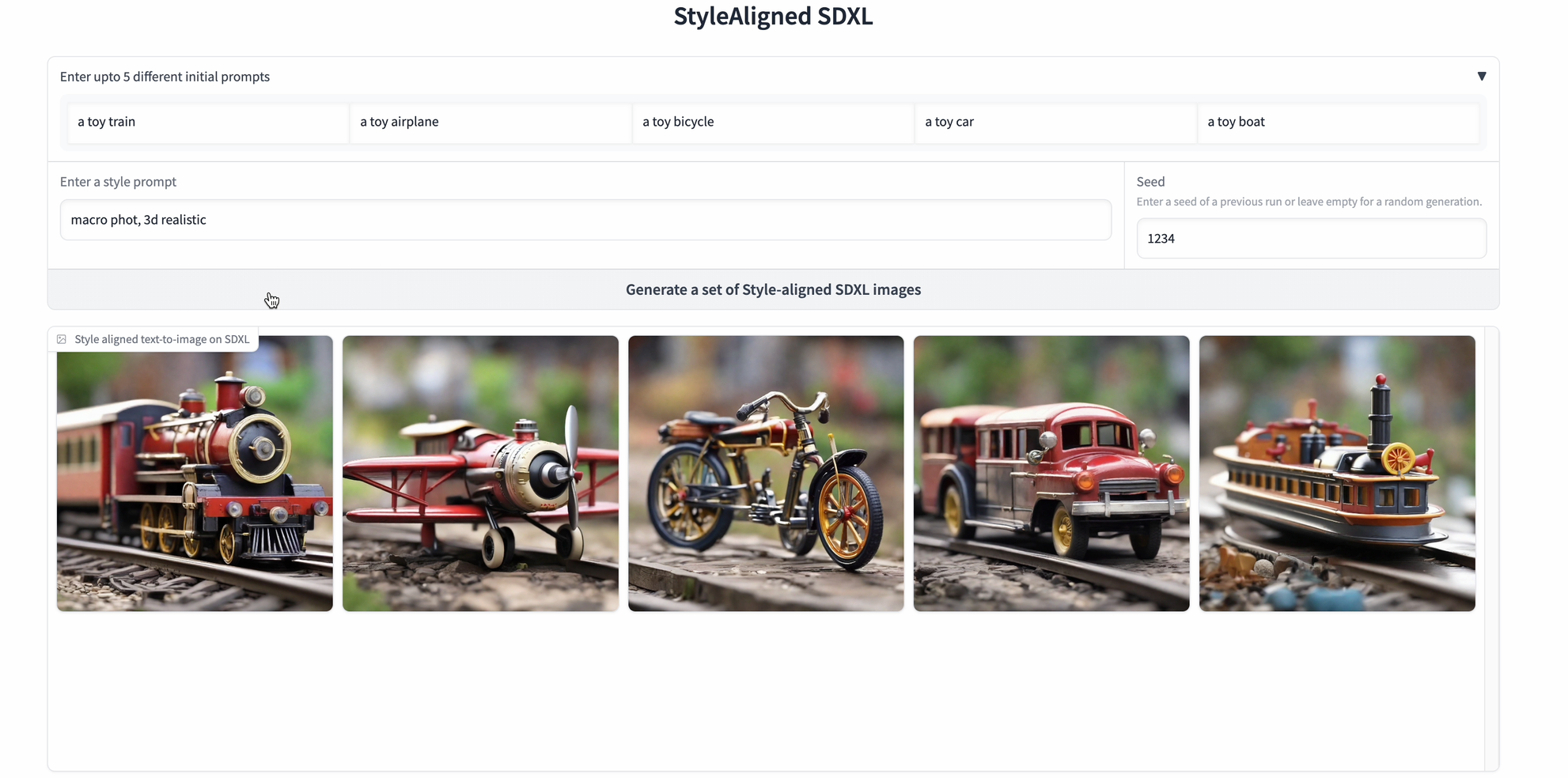
- Experiments with totally different fashions
Please be happy to change the code under to experiment with and run varied fashions.
!sed 's/.launch()/.launch(share=True)/' -i /notebooks/demo_desired_model_name.py
!python demo_desired_model_name.py
Closing Ideas
On this article, we have now walked via StyleAligned mannequin for picture technology. The demo showcases the effectiveness of StyleAligned for producing high-quality, style-consistent photos throughout a spread of types and textual prompts. This mannequin might discover potential software in inventive fields corresponding to content material creation and designs, e-commerce promoting, gaming, schooling, and extra. Our findings verify StyelAligned’s skill to interpret supplied descriptions and reference types whereas sustaining spectacular synthesis high quality. We suggest StyleAligned to customers who need to discover textual content to picture fashions intimately and are additionally skilled in working with secure diffusion fashions.
Thanks for studying, and remember to take a look at our different articles on Paperspace blogs associated to picture technology!