
{kind=link}
Carry this challenge to life
NLP stands out as probably the most broadly adopted sub-disciplines of Machine/Deep Studying. Its prominence has turn into much more evident as a result of widespread integration of Generative Pretrained Transformer (GPT) fashions like ChatGPT, Alpaca, Llama, Falcon, Bard, and quite a few others throughout numerous on-line platforms.
With the development of those fashions, there’s an enormous give attention to making them extra accessible to all. Open-source fashions are notably essential on this effort, enabling researchers, builders, and fans to discover their complexities, customise them for particular functions, and broaden upon their fundamentals.
On this weblog publish, we’ll discover the Falcon LLM mannequin which is rating prime on Hugging Face leaderboard as the most important open-source LLMs. Falcon’s huge success is making waves within the AI group, with some going as far as to name it an official Llama Killer. To additional discover Falcon LLM, we’ve included a demo on tips on how to run Falcon 40b inside a Paperspace pocket book. On this code demo we’ll run Falcon 40b, utilizing the A4000x2 GPU, geared up with 90GB of VRAM, and the price shall be solely $1.52 per hour.

Introduction to Falcon – a brand new entrant within the LLM area
The Expertise Innovation Institute (TII) within the United Arab Emirates (UAE) has revealed Falcon 180B on sixth September 2023, essentially the most intensive open-source giant language mannequin (LLM) presently accessible, boasting a reported 180 billion parameters. This mannequin was educated utilizing 3.5 trillion tokens, with a context window of 2048 tokens. That’s 4x instances the quantity of knowledge used to coach Llama 2.
The mannequin coaching utilized 4096 A100 40GB GPUs, utilizing a 3D parallelism technique (TP=8, PP=8, DP=64) mixed with ZeRO. Along with that, the mannequin underwent coaching for roughly 7,000,000 GPU hours. Falcon 180B reveals a 2.5 instances better pace in comparison with LLMs like Llama 2.
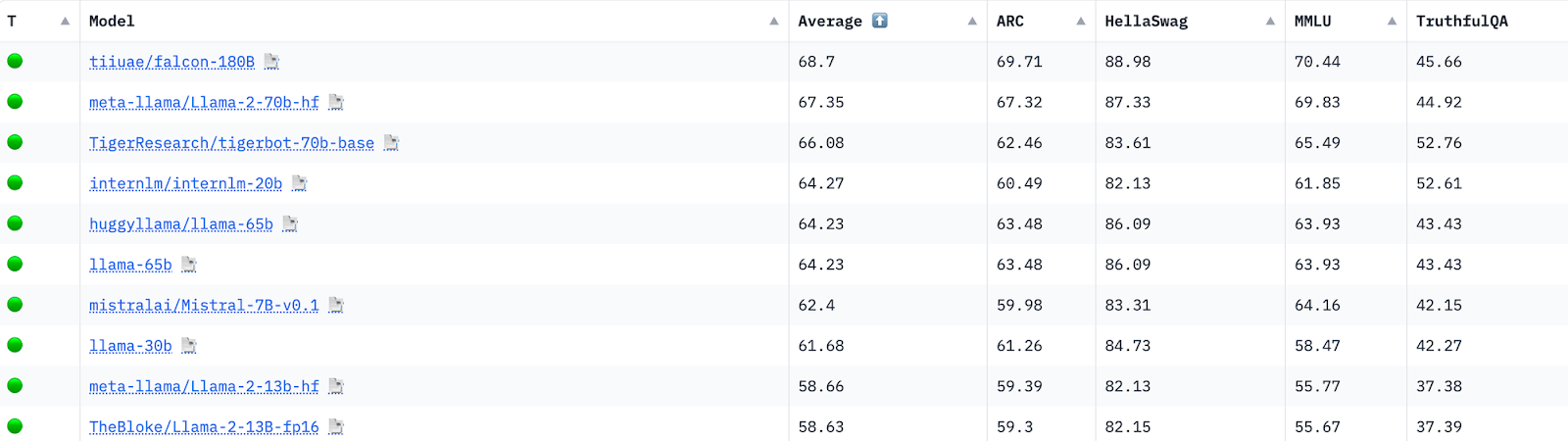
The mannequin additionally outperforms Llama 2 in multi-task language understanding (MMLU) duties. This open LLM tops the Hugging Face leaderboard for pre-trained fashions and is accessible for analysis and business functions. It additionally matches Google’s PaLM 2-Giant on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD.
Moreover, they discovered that, all collectively in combination, they had been capable of present that Falcon 180B has accuracy similar to the top-of-the-line PaLM-2 Giant mannequin. Falcon has confirmed to be a competitor for PaLM-2 and GPT-3 as effectively and is simply behind GPT-4.
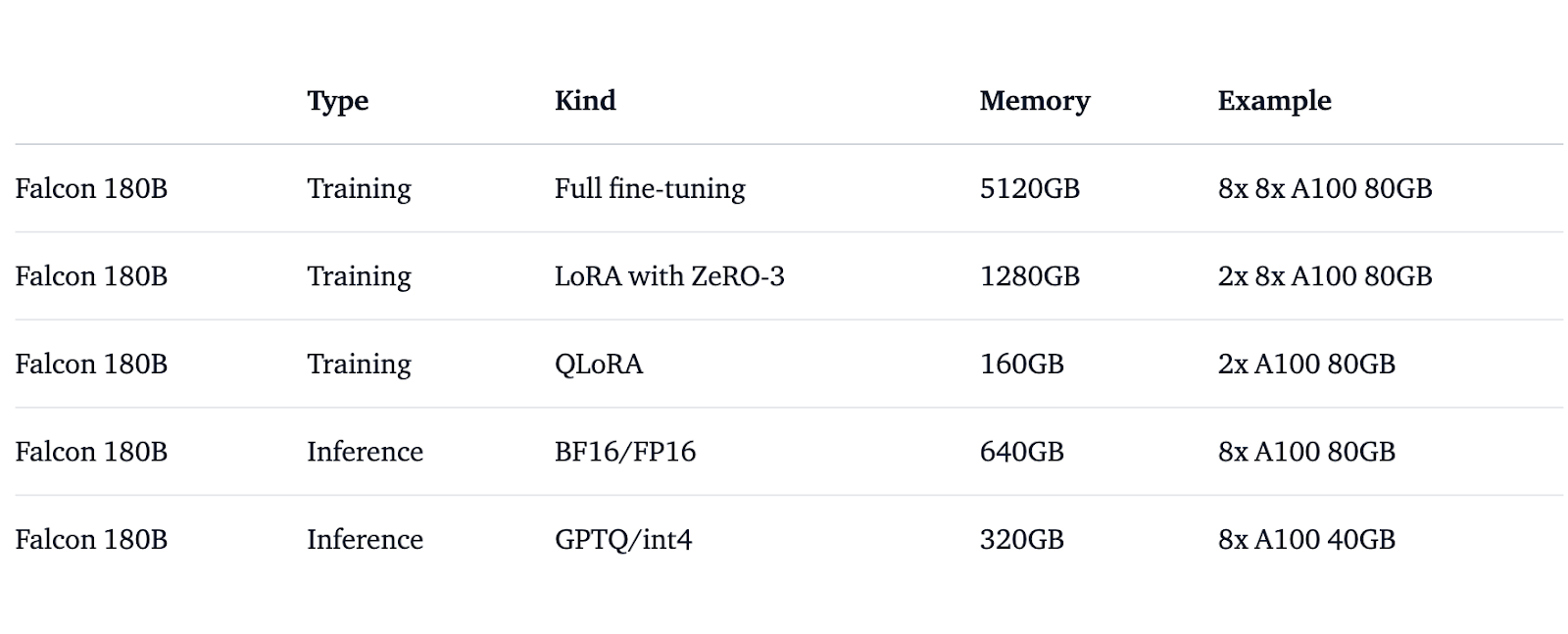
It is essential to focus on that the mannequin’s dimension requires a minimal of 320GB of reminiscence for correct functioning, which may entail a major funding in assets.
Temporary overview of enormous language fashions
Giant Language Mannequin or LLMs are deep studying algorithms which might be designed to carry out Pure Language Processing (NLP) duties. The bottom of any LLMs are usually Transformers blocks, and these fashions are sometimes educated on huge quantities of knowledge. The Massive Information coaching required to make an LLM is the rationale it’s referred to as the Giant Language Mannequin.
Other than instructing AI purposes in human languages, giant language fashions will be educated for numerous duties, together with decoding protein buildings, producing software program code, and extra. To carry out these particular duties these LLMs much like the human mind require coaching and high quality tuning. Their problem-solving talents discover utility in healthcare, finance, and leisure, the place giant language fashions assist varied NLP duties like translation, chatbots, and AI assistants.
The LLMs are normally educated on a large variety of hyperparameters and coaching knowledge which helps the mannequin to know the sample of the information.
Falcon’s structure and design
As we understood, the bottom structure of any LLMs is the Transformer mannequin which consists of an encoder and a decoder.
Transformers in Giant Language Fashions (LLMs) work by using the Transformer structure. This construction permits these fashions to course of and perceive language by utilizing self-attention mechanisms. In easier phrases, transformers deal with enter knowledge in a parallel method, enabling them to think about your entire context of a sentence or piece of textual content.
Every phrase or token in a sentence is embedded right into a high-dimensional area. Transformers then apply consideration mechanisms permitting each phrase to ‘attend’ or contribute to the understanding of each different phrase within the sentence. This mechanism helps seize the relationships between phrases and their contextual which means inside the sentence.
Transformers in LLMs are made up of a number of layers, every containing a sequence of self-attention mechanisms and feedforward neural networks. This multi-layered strategy permits for classy language understanding and era. The mannequin learns to signify the textual content knowledge in a means that helps in varied pure language processing duties, equivalent to textual content era, sentiment evaluation, language translation, and extra.
Falcon 180B, an evolution from Falcon 40B, expands upon its improvements, together with multiquery consideration for enhanced scalability. Skilled on as much as 4096 GPUs, totaling round 7,000,000 GPU hours, it’s 2.5 instances bigger than Llama 2 and utilized 4 instances the computational energy to coach.
The coaching dataset primarily includes RefinedWeb knowledge, accounting for roughly 85% of the dataset. RefinedWeb knowledge is a novel huge net dataset which is predicated on CommonCrawl. Moreover, it has been educated utilizing a mixture of rigorously curated data, together with discussions, technical papers, and a minor portion of code, constituting round 3% of the dataset.
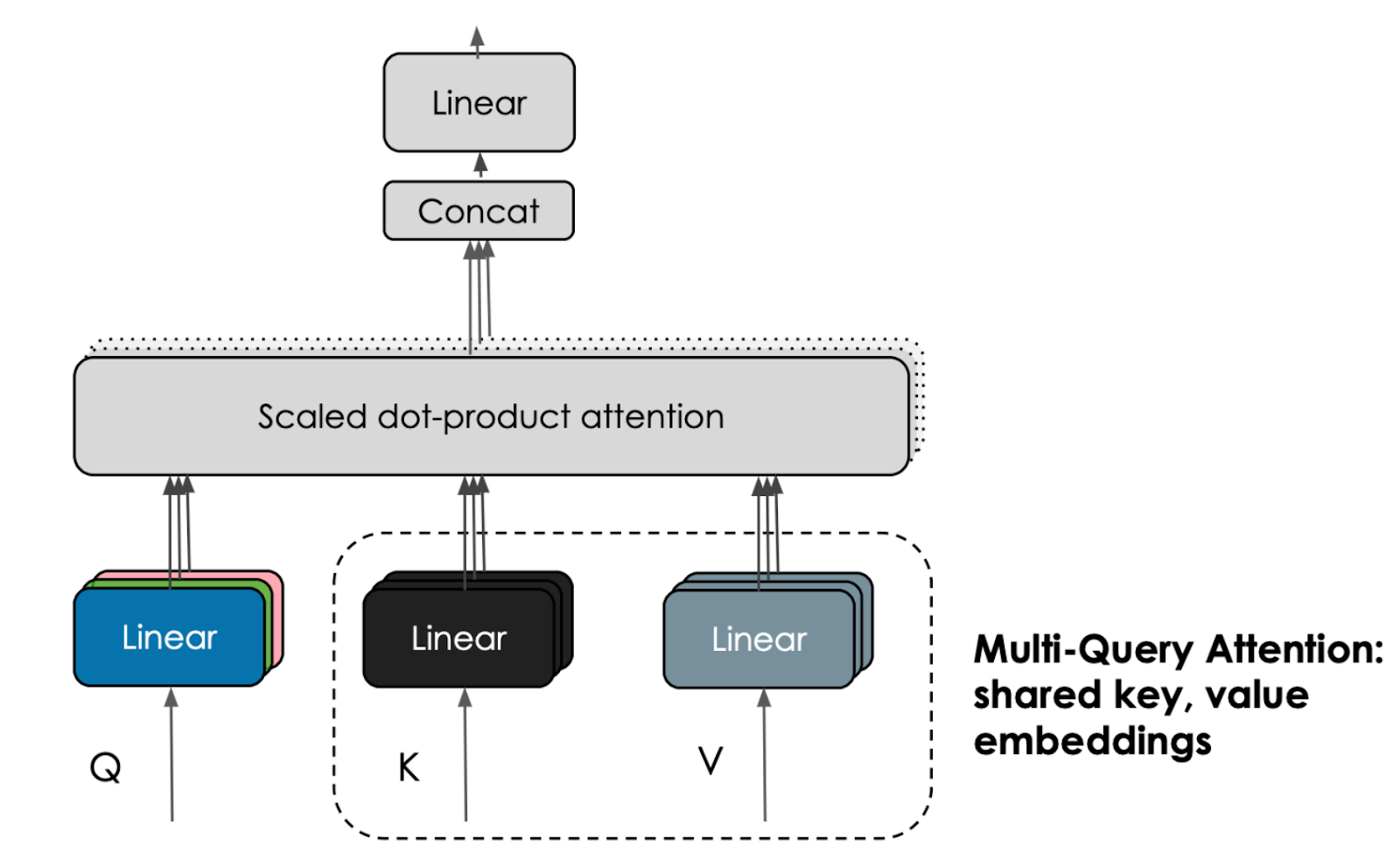
The Falcon 180B structure is roughly tailored from the GPT-3 paper (Brown et al., 2020), with just a few key variations equivalent to:
Falcon’s structure is fine-tuned for inference, surpassing main fashions like these developed by Google, Anthropic, Deepmind, and LLaMa, as demonstrated by its efficiency on the OpenLLM Leaderboard.
Comparability with current language fashions
- Falcon 180 billion is considerably greater when in comparison with GPT-3 which has 175 billion parameters. Falcom 180b scores lies in between GPT-3.5 and GPT-4
- All the LLMs are educated on a large dataset. The precise coaching dimension of the GPT mannequin isn’t clear as GPT fashions are nonetheless closed supply. Nonetheless, Falcon 180b is educated on 3.5 trillion tokens utilizing TII’s RefinedWeb dataset
- By way of scale, Falcon 180B is 2.5 instances bigger than Meta’s LLaMa 2 mannequin, which was beforehand thought to be probably the most succesful open-source LLMs. Falcon 180B, with a rating of 68.74 on the Hugging Face Leaderboard, has achieved the best rating amongst overtly launched pre-trained LLMs, surpassing Meta’s LLaMA 2, which scored 67.35
- Falcon is an open supply and permits business utilization not like Open AI’s GPT fashions
- Falcon 180B not solely exceeds LLaMa 2 but additionally surpasses different fashions in each scale and benchmark efficiency throughout varied pure language processing (NLP) duties
Falcon 180B is presently the most important accessible language mannequin, exceeding each its predecessors and rivals in dimension. Please be happy to entry the weblog publish hyperlink on Paperspace Platform for an intensive clarification of the GPT mannequin structure.
Benefits of Falcon over current fashions
Falcon and its variants – 1B, 7B, 40B, 180B have gained immense recognition as essentially the most highly effective open-source language mannequin so far. This highly effective LLM is obvious within the Hugging Face Leaderboard. Additionally, being open supply will empower researchers and innovators to discover the mannequin carefully.
Meticulous filtering and relevance checks assure the inclusion of top-quality knowledge. Constructing a powerful knowledge pipeline for environment friendly processing was essential, as high-quality coaching knowledge considerably influences language mannequin efficiency. TII researchers utilized superior filtering and de-duplication strategies to extract superior content material from the net.
Other than English, this LLM possesses an understanding in German, Spanish, and French. Additionally they exhibit primary proficiency in a number of European languages equivalent to Dutch, Italian, Romanian, Portuguese, Czech, Polish, and Swedish. This intensive linguistic vary broadens Falcon’s potential purposes throughout numerous language contexts.
Whereas LLaMA’s codes are open sourced in github, the burden of the mannequin continues to be hidden therefore possessing a limitation on the utilization. Falcon which employs a modified Apache license enabling the LLM for fine-tuning and business utility.
{Hardware} Necessities
Falcon has been launched because the open supply LLM for analysis and business functions. The requirement of enormous quantities of reminiscence and costly GPU to run the mannequin stays a draw back of the Falcon 180b.
To run the mannequin, it requires 640GB of reminiscence that’s 8 X A100 80GB GPUs quantized to half precision. Moreover, if quantized all the way down to int4, it requires 320GB of reminiscence that’s 8 X A100 40GB GPUs.
Addressing potential limitations and challenges
The first concern is the appreciable useful resource demand of the Falcon 180B. For optimum efficiency, the mannequin necessitates a considerable 400GB of VRAM, which equates to roughly 5 A100 GPUs. These excessive specs render the mannequin inaccessible for many medium-sized companies and pose a major problem for a lot of researchers.
The bottom mannequin doesn’t include a predefined immediate format. It is essential to notice that it isn’t designed for producing conversational responses, because it hasn’t been educated with particular directions. Whereas the pretrained mannequin serves as a strong basis for additional fine-tuning, utilizing it as-is for producing dialog could not yield optimum outcomes. The chat mannequin follows a simple dialog construction.
The fee to run inference on this mannequin provides as much as 1000’s of {dollars}, which once more isn’t possible for a lot of researchers and AI fans.
Other than the immense useful resource wants, there is a scalability concern. The mannequin is nearing a degree the place including extra parameters to a mannequin will not acquire additional vital outcomes. Each expertise, together with AI fashions, has boundaries. This raises issues in regards to the sustainability of frequently rising mannequin dimension. In brief, there is a restrict to the developments we are able to obtain by means of this strategy. This strategy might need an opportunity to make LLAMA 2 a extra sensible selection for a lot of within the open-source sphere.
Final however not least, the present pattern exhibits a race to be the largest and the most effective with out contemplating the practicalities of actual world purposes. The main target should not solely revolve across the magnitude and dimensions of those fashions, however moderately on their practicality, effectiveness, and broader utility for a extra intensive consumer base.
Quite the opposite, smaller fashions are able to working successfully on normal shopper {hardware}, providing customers the flexibility to fine-tune and personalize them in keeping with their necessities.
Falcon 40b in Motion utilizing Paperspace Platform
On this tutorial we’ll load and run Falcon 40b utilizing Paperspace platform.
Working the 40b parameter would possibly result in reminiscence points and likewise will be costly. Reminiscence points would possibly nonetheless persist even when using Nvidia A100 GPUs and 45 GB RAM. Nonetheless, with the varied vary of Paperspace GPUs one can execute the mannequin at an reasonably priced value. On this code demo we used a Pocket book powered by a A4000x2 GPU enabled machine, geared up with 90GB of VRAM, with a value of solely $1.52 per hour.
Carry this challenge to life
- We begin by Putting in the required libraries to run the mannequin
#set up the dependencies
!pip set up -qU transformers speed up einops langchain xformers bitsandbytes- The beneath code is used to initialize and cargo a pre-trained mannequin for language modeling utilizing the Hugging Face Transformers library. Allow us to perceive the code by additional breaking it down into elements.
#import essential libraries to get the mannequin working
import torch
from torch import cuda, bfloat16
import transformers
#Retailer the pre educated mannequin to the variable
model_name="tiiuae/falcon-40b"
#Determines the computing gadget for use for mannequin inference. If a CUDA-enabled GPU is accessible, it units the gadget to the GPU (particularly, the present CUDA gadget); in any other case, it defaults to the CPU.
gadget = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
# set quantization configuration to load giant mannequin with much less GPU reminiscence
# this requires the `bitsandbytes` library
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=bfloat16
)
mannequin = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto'
)
mannequin.eval()
print(f"Mannequin loaded on {gadget}")- Quantization Configuration (bnb_config): The code units up a quantization configuration utilizing the BitsAndBytesConfig class from the transformers library. Quantization is a method to cut back the reminiscence footprint of a mannequin. The configuration contains parameters equivalent to loading in 4-bit precision, specifying the quantization kind, utilizing double quantization, and setting the compute knowledge kind to bfloat16.
- mannequin = transformers.AutoModelForCausalLM.from_pretrained(…): This line of code masses the pre-trained mannequin for language modeling utilizing the desired mannequin identify (‘tiiuae/falcon-40b’). It makes use of the AutoModelForCausalLM class from the Transformers library.
- mannequin.eval(): This places the loaded mannequin in analysis mode. In PyTorch, this usually disables dropout layers, that are generally used throughout coaching however not throughout inference.
- print(f”Mannequin loaded on {gadget}”): Subsequent, print the message indicating on which gadget the mannequin has been loaded, whether or not it is the GPU (specified by CUDA) or the CPU.
This code will take roughly 30 min to load the pre-trained mannequin with the desired quantization configurations, contemplating the GPU availability and utilization.
- Create the tokenizer,
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
- Subsequent, use the Hugging Face Transformers library to transform token sequences into their corresponding token IDs.
The primary goal of the code is to transform particular token sequences into their numerical representations a.ok.a (token IDs) utilizing a tokenizer, and retailer the leads to the stop_token_ids record. These token IDs may very well be used as stopping standards in the course of the mannequin coaching.
from transformers import StoppingCriteria, StoppingCriteriaList
#take a listing of tokens (x) and convert them into their corresponding token IDs utilizing the tokenizer.
stop_token_ids = [tokenizer.convert_tokens_to_ids(x) for x in [['Human', ':'], ['AI', ':']]]
stop_token_ids- We are going to convert every integer worth within the stop_token_ids record right into a PyTorch LongTensor after which transfer the ensuing tensors to a specified gadget.
import torch
#changing every integer worth in stop_token_ids right into a PyTorch LongTensor and shifting it to a specified gadget
stop_token_ids = [torch.LongTensor(x).to(device) for x in stop_token_ids]
stop_token_ids- The beneath code units up a textual content era pipeline utilizing the Hugging Face Transformers library. The ensuing generate_text object is a callable operate that, when supplied with a immediate, will generate textual content primarily based on the desired configuration. This pipeline simplifies the method of interacting with our pre-trained Falcon 40b mannequin for textual content era duties. Allow us to perceive the steps together with the code.
#create the mannequin pipeline
generate_text = transformers.pipeline(
mannequin=mannequin, #move the mannequin
tokenizer=tokenizer, #move the tokenizer
return_full_text=True, #to return the unique question, making it simpler for prompting.
activity='text-generation', #activity
# we move mannequin parameters right here too
stopping_criteria=stopping_criteria, #to get rid of pointless conversations
temperature=0.3, #for 'randomness' of mannequin outputs, 0.0 is the min and 1.0 the max
max_new_tokens=512, #max variety of tokens to generate within the output
repetition_penalty=1.1 #with out this output begins repeating (be sure that to experiment with this)
)- generate_text = transformers.pipeline(…): This line instantiates a textual content era pipeline utilizing the pipeline operate from the Transformers library. It takes within the beneath talked about parameters.
- mannequin=mannequin and tokenizer=tokenizer: These parameters specify the pre-trained language mannequin that must be thought of and the tokenizer for use within the textual content era pipeline. These parameters we’ve already declared in our earlier code.
- return_full_text=True: This parameter signifies that the generated output ought to embrace the unique question.
- activity=’text-generation’: This parameter specifies the duty for the pipeline, on this case, textual content era.
- stopping_criteria=stopping_criteria: This parameter makes use of a stopping standards beforehand outlined within the code. Stopping standards are situations that, when met, halt the textual content era course of. This may be helpful for controlling the size or high quality of the generated textual content. Please use this parameter cautiously.
- temperature=0.3: Temperature is a hyperparameter that controls the randomness of the mannequin’s output. Decrease values (nearer to 0) make the output extra deterministic, whereas larger values (nearer to 1) introduce extra randomness.
- max_new_tokens=512: This parameter units the utmost variety of tokens to generate within the output. It can be used to restrict the size of the generated textual content. Be happy to experiment with this parameter.
- repetition_penalty=1.1: Repetition penalty is a hyperparameter that provides a penalty to the mannequin from repeating the identical tokens in its output. It helps in producing extra numerous textual content.
- Subsequent we’ll generate the output,
#generate output
res = generate_text("Clarify to me the distinction between centrifugal power and centripetal power.")
print(res[0]["generated_text"])
#generate sequential output
sequences = generate_text("Girafatron is obsessive about giraffes, essentially the most superb animal on the face of this Earth. Giraftron believes all different animals are irrelevant when in comparison with the fantastic majesty of the giraffe.nDaniel: Hiya, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
Please click on on the demo hyperlink to view your entire code and experiment with the code and the mannequin.
Carry this challenge to life
Future Developments in LLM and Impacts
The dimensions of the worldwide AI market is estimated to rise as much as $1,811.8 billion by 2030.
Throughout the realm of AI, Pure Language Processing (NLP) is experiencing vital consideration, with forecasts suggesting the worldwide NLP market will surge from $3 billion in 2017 to a projected $43 billion by 2025 (Supply). With the event of no code platforms LLMs are rising because the leading edge expertise to spice up enterprise development and scale back human effort.
Moreover future LLMs have further properties to reality verify the knowledge themselves. Doing this can make the mannequin extra dependable and higher fitted to real-world purposes.
As of now LLMs are nonetheless behind people in the case of language understanding and attributable to this generally gives incorrect data. To unravel these points the demand for immediate engineers are rising. These engineers specializing in immediate engineering can improve the mannequin’s skill to supply extra pertinent and exact responses, even when coping with intricate inquiries. Two widely known strategies in immediate engineering embrace Few-Shot Studying and Chain of Thought prompting. Few-Shot Studying includes crafting prompts containing just a few comparable cases together with the supposed outcome, performing as navigational aids for the mannequin to generate responses. Chain of Thought prompting includes a sequence of methods tailor-made for duties requiring logical reasoning or step-by-step computation.
Along with typical fine-tuning strategies, new rising approaches goal to reinforce the precision of LLMs. For instance is Reinforcement Studying from Human Suggestions (RLHF), a technique employed within the coaching of ChatGPT. Equally, High quality-Tuning with PEFT (Parameter Environment friendly High quality Tuning) is used for Falcon. Utilizing the PEFT library, the fine-tuning process makes use of the QLoRA methodology, incorporating adapters for fine-tuning over a locked 4-bit mannequin.
Rising concepts equivalent to integrating quantum computing into expansive language fashions mark the evolving panorama of improvements in LLMs. It is an exhilarating prospect to anticipate how forthcoming developments will sort out the persisting challenges encountered by these language fashions.
Concluding Ideas
The Falcon LLMs have demonstrated spectacular capabilities when in comparison with closed-source LLMs. Hugging Face’s leaderboard has indicated its potential to compete with Google’s PaLM 2, the language mannequin supporting Bard, emphasizing that it surpasses the efficiency of GPT-3.5. Nonetheless, to run the Falcon 180b, one wants to concentrate to GPU necessities, RAM and VRAM.
Though the bigger Falcon fashions equivalent to 40b and 180b demand vital computational assets, the smaller 7B variant will be operated on utilizing low-cost or free Paperspace GPUs. Refinement is achievable through QLoRA, PEFT, and SFT Coach.
The discharge of Falcon 180B underscores the speedy evolution of AI, emphasizing that no single supplier will indefinitely dominate the market. Regardless of OpenAI’s preliminary lead with ChatGPT, rivals constantly advance, making it difficult for any supplier to take care of a particular edge as others improve their efficiency.
On this article, we coated a short introduction to Falcon 180b and included a code demo to run Falcon 40b utilizing the Paperspace platform. We additionally understood just a few related subjects within the realm of Giant Language Mannequin. Additionally, Falcon 180b is a strong open supply mannequin. This a lot is abundantly clear from our experimentation. We now have made this LLM accessible by means of the strong infrastructure and a variety of GPUs supplied by Paperspace.
Please be happy to check out this tutorial! Thanks for studying.