
{kind=link}
On this tutorial, we’ll discover the distilled model of Steady Diffusion (SD) by an in-depth information, this tutorial additionally contains the usage of Gradio to carry the mannequin to life. Our journey begins with constructing comprehension of the information distilled model of steady diffusion and its significance. To higher perceive the idea of Information Distillation (KD), we have extensively coated it in a earlier weblog publish. You’ll be able to confer with the hyperlink offered for an in depth understanding of KD.
Moreover, we’ll attempt to breakdown the mannequin structure as defined within the related analysis paper. We are going to use this to assist us run the mission’s included code demo, permitting us to achieve a hands-on expertise with the mannequin utilizing the free GPUs supplied by Paperspace. We are able to simply run the mannequin utilizing on the platform with the offered Run on Paperspace hyperlink on the high of this web page. Use the offered pocket book to comply with alongside and recreate the work proven on this article.
Participating with the code demo will present a sensible grasp of using the mannequin, contributing to a well-rounded studying expertise. We additionally encourage you to take a look at our earlier weblog posts on Steady Diffusion if eager about studying extra about underlying base mannequin.
Introduction
SD fashions are one of the vital well-known open-source fashions on the whole, although most significantly for his or her capabilities in textual content to picture generations. SD has proven distinctive capabilities and has been a spine in a number of textual content to picture era purposes. SD fashions are latent diffusion fashions, the diffusion operations in these fashions are carried in a semantically compressed area. Inside a SD mannequin, a U-Internet performs an iterative sampling to steadily take away noise from a randomly generated latent code. This course of is supported by each a textual content encoder and a picture decoder, working collaboratively to generate photographs that align with offered textual content descriptions or the prompts. Nonetheless, this course of turns into computationally costly and infrequently hinders in its utilization. To sort out the issue quite a few approaches have been launched.
The examine of diffusion fashions unlocked the potential of compressing the classical structure to realize a smaller and sooner mannequin. The analysis carried out to attain a distilled model of SD, reduces the sampling steps and applies community quantization with out altering the unique architectures. This course of has proven larger effectivity. This distilled model mannequin demonstrates the efficacy, even with useful resource constraints. With simply 13 A100 days and a small dataset, this compact fashions proved to be able to successfully mimicking the unique Steady Diffusion Fashions (SDMs). Given the fee related to coaching SDMs from the bottom zero, exceeding 6,000 A100 days and involving 2,000 million pairs, the analysis reveals that community compression emerges as a notably cost-effective strategy when developing compact and versatile diffusion fashions.
What’s Distilled Steady Diffusion?
Steady Diffusion belongs to deep studying fashions referred to as as diffusion fashions. These Massive textual content to picture (T2I) diffusion mannequin works by eradicating noise from noisey, randomized knowledge. SD fashions are normally skilled on billions of picture dataset and are skilled to generate new knowledge from what they’ve realized in the course of the mannequin coaching.
The idea of diffusion begins by including random noise to a picture, allow us to assume the picture to be a cat picture. Regularly, by including noise to the picture the picture turns to a extraordinarily blurry picture which can’t be acknowledged additional. That is referred to as Ahead Diffusion.

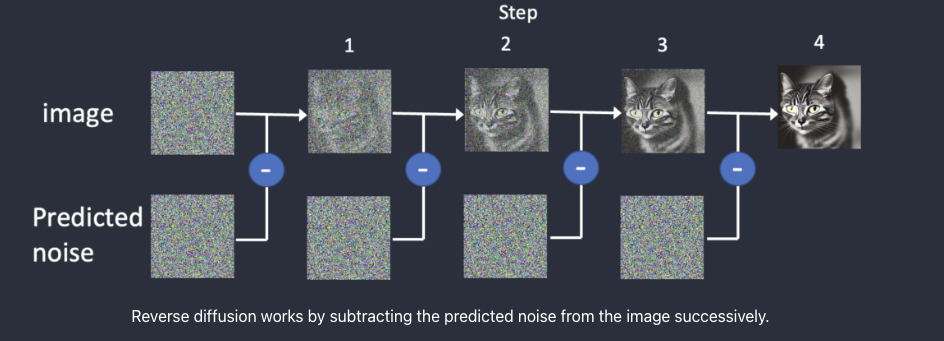
Subsequent, comes crucial half, the Reverse Diffusion. Right here, the unique picture is restored again by eradicating the noise iteratively. With the intention to carry out Reverse Diffusion, it is important to know the quantity of noise launched to a picture. This entails coaching a deep neural community mannequin to foretell the added noise, which is known as the noise predictor in Steady Diffusion. The noise predictor takes the type of a U-Internet mannequin.
The preliminary step entails making a random picture and utilizing a noise predictor to foretell the noise inside that picture. Subsequently, we subtract this estimated noise from the unique picture, and this course of is iteratively repeated. After just a few iterations, the end result is a picture that represents both a cat or a canine.
Nonetheless, this course of is just not an environment friendly course of and to hurry up the method Latent Diffusion Mannequin is launched. Steady Diffusion capabilities as a latent diffusion mannequin. Slightly than working inside the high-dimensional picture area, it initially compresses the picture right into a latent area. This latent area is 48 instances smaller, resulting in the benefit of processing considerably fewer numbers. That is the explanation for its notably sooner efficiency. Steady Diffusion makes use of a way referred to as because the Variational Autoencoder or VAE neural community. This VAE has two components an encoder and a decoder. The encoder compresses the picture right into a decrease dimensional picture and decoder restores the picture.
Throughout coaching, as a substitute of producing noisy photographs, the mannequin generates tensor in latent area. As an alternative of introducing noise on to a picture, Steady Diffusion disrupts the picture within the latent area with latent noise. This strategy is chosen for its effectivity, as working within the smaller latent area leads to a significantly sooner course of.
Nonetheless, right here we’re speaking about photographs now, the query is from the place does the textual content to picture comes?
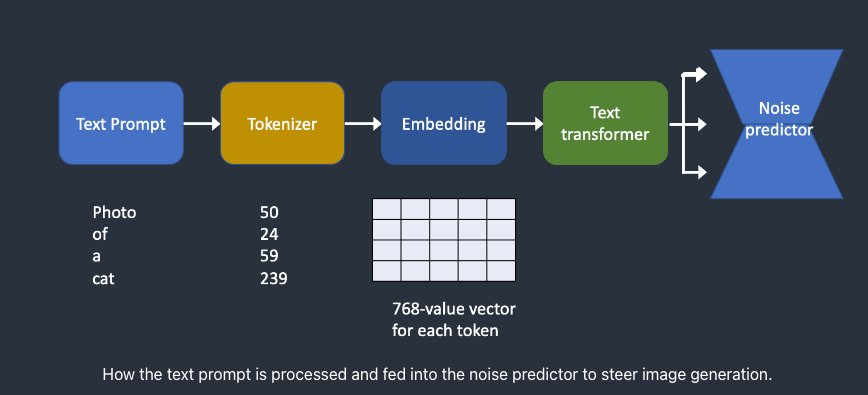
In SDMs, a textual content immediate is handed to a tokenizer to transform the immediate to tokens or numbers. Tokens are numerical values representing the phrases and these are utilized by the pc to know these phrases. Every of those tokens are then transformed right into a 768-value vector referred to as embedding. Subsequent, these embeddings are then processed by the textual content transformer. On the finish the output from the transformers are fed to the Noise Predictor U-Internet.
The SD mannequin initiates a random tensor in latent area, this random tensor could be managed by the seed of the random quantity generator. This noise is the picture in latent area. The Noise predictor takes on this latent noisy picture and the immediate and predicts the noise in latent area (4x64x64 tensor).
Moreover, this latent noise is subtracted from the latent picture to generate the brand new latent picture. These steps are iterated which could be adjusted by the sampling steps. Subsequent, the decoder VAE converts the latent picture to pixel area, producing the picture aligning with the immediate.
Total, the latent diffusion mannequin combines components of chance, generative modeling, and diffusion processes to create a framework for producing complicated and lifelike knowledge from a latent area.
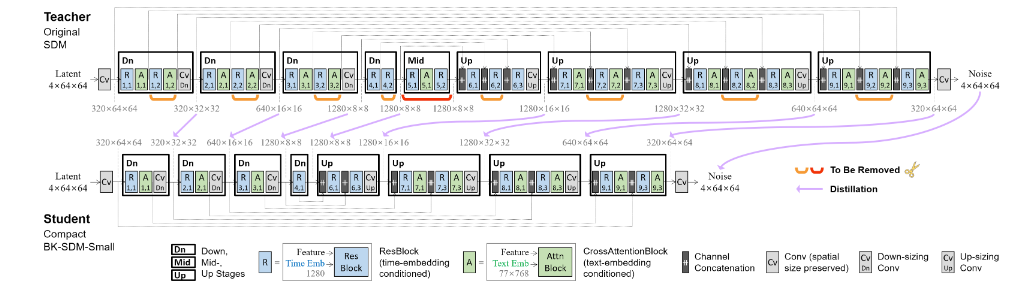
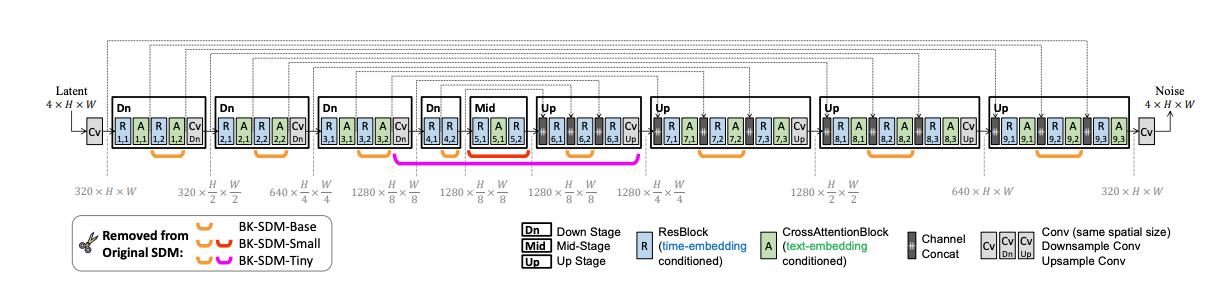
Utilizing Steady Diffusion could be computationally costly because it entails denoising latents iteratively to generate a picture. To scale back the mannequin complexities, the Distilled Steady Diffusion mannequin from Nota AI is launched. This distilled model streamlines the UNet by eradicating sure residual and a focus blocks of SDM, leading to a 51% discount in mannequin dimension and a 43% enchancment in latency on CPU/GPU. This work has been capable of obtain larger outcomes and but being on skilled on finances.
As mentioned within the analysis paper , Within the Information-distilled SDMs, the U-Internet is simplified, which is probably the most computationally intensive a part of the system. The U-Internet, embedded by textual content and time-step data, goes by denoising steps to generate latent representations. The per-step calculations within the U-Internet is additional minimized, leading to a extra environment friendly mannequin. The structure of the mannequin obtained by compressing SDM-v1 is proven within the picture beneath.
Code Demo
Deliver this mission to life
Click on the hyperlink offered on this article and navigate to the distilled_stable_diffusion.ipynb pocket book. Comply with the steps to run the pocket book.
Let’s start by putting in the required libraries. Along with the DSD libraries, we can even set up Gradio.
!pip set up --quiet git+https://github.com/huggingface/diffusers.git@d420d71398d9c5a8d9a5f95ba2bdb6fe3d8ae31f
!pip set up --quiet ipython-autotime
!pip set up --quiet transformers==4.34.1 speed up==0.24.0 safetensors==0.4.0
!pip set up --quiet ipyplot
!pip set up gradio
%load_ext autotimeSubsequent, we’ll construct pipeline and generate the primary picture and save the generated picture.
# Import the mandatory libraries
from diffusers import StableDiffusionXLPipeline
import torch
import ipyplot
import gradio as gr
pipe = StableDiffusionXLPipeline.from_pretrained("segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
immediate = "an orange cat staring off with fairly eyes, Placing picture, 8K, Desktop background, Immensely sharp."
neg_prompt = "ugly, poorly Rendered face, low decision, poorly drawn ft, poorly drawn face, out of body, further limbs, disfigured, deformed, physique out of body, blurry, dangerous composition, blurred, watermark, grainy, signature, lower off, mutation"
picture = pipe(immediate=immediate, negative_prompt=neg_prompt).photographs[0]
picture.save("take a look at.jpg")
ipyplot.plot_images([image],img_width=400)
The above code imports the ‘StableDiffusionXLPipeline’ class from the ‘diffusers’ module. Publish importing the mandatory libraries, we’ll create an occasion of the ‘StableDiffusionXLPipeline’ class named ‘pipe.’ Subsequent, load the pre-trained mannequin named “segmind/SSD-1B” into the pipeline. The mannequin is configured to make use of 16-bit floating-point precision that we specify in dtype argument, and secure tensors are enabled. The variant is about to “fp16”. Since we’ll use ‘GPU’ we’ll transfer the pipeline to CUDA machine for sooner computation.
Allow us to improve the code additional, by adjusting the steerage scale, which impacts the prompts on the picture era. On this case, it’s set to 7.5. The parameter ‘num_inference_steps’ is about to 30, this quantity signifies the steps to be taken in the course of the picture era course of.
allimages = pipe(immediate=immediate, negative_prompt=neg_prompt,guidance_scale=7.5,num_inference_steps=30,num_images_per_prompt=2).photographs
Construct Your Net UI utilizing Gradio
Gradio supplies the quickest technique to showcase your machine studying mannequin by a user-friendly net interface, enabling accessibility for anybody to make use of. Allow us to learn to constructed a easy UI utilizing Gradio.
Outline a operate to generate the photographs which we’ll use to constructed the gradio interface.
def gen_image(textual content, neg_prompt):
return pipe(textual content,
negative_prompt=neg_prompt,
guidance_scale=7.5,
num_inference_steps=30).photographs[0]Subsequent, code snippet makes use of the Gradio library to create a easy net interface for producing AI-generated photographs utilizing a operate referred to as gen_image.
txt = gr.Textbox(label="immediate")
txt_2 = gr.Textbox(label="neg_prompt")
Two textboxes (txt and txt_2) are outlined utilizing the gr.Textbox class. These textboxes function enter fields the place customers can enter textual content knowledge. These fields are used for coming into the immediate and the adverse immediate.
#Gradio Interface Configuration
demo = gr.Interface(fn=gen_image, inputs=[txt, txt_2], outputs="picture", title="Generate A.I. picture utilizing Distill Steady Diffusion😁")
demo.launch(share=True)
- First specify the operate
gen_imagebecause the operate to be executed when the interface receives enter. - Defines the enter parts for the interface, that are the 2 textboxes for the immediate and adverse immediate (
txtandtxt_2). outputs="picture": generate the picture output and set the title of the interfacetitle="Generate A.I. picture utilizing Distill Steady Diffusion😁"- The
launchtechnique is known as to start out the Gradio interface. Theshare=Trueparameter signifies that the interface ought to be made shareable, permitting others to entry and use it.
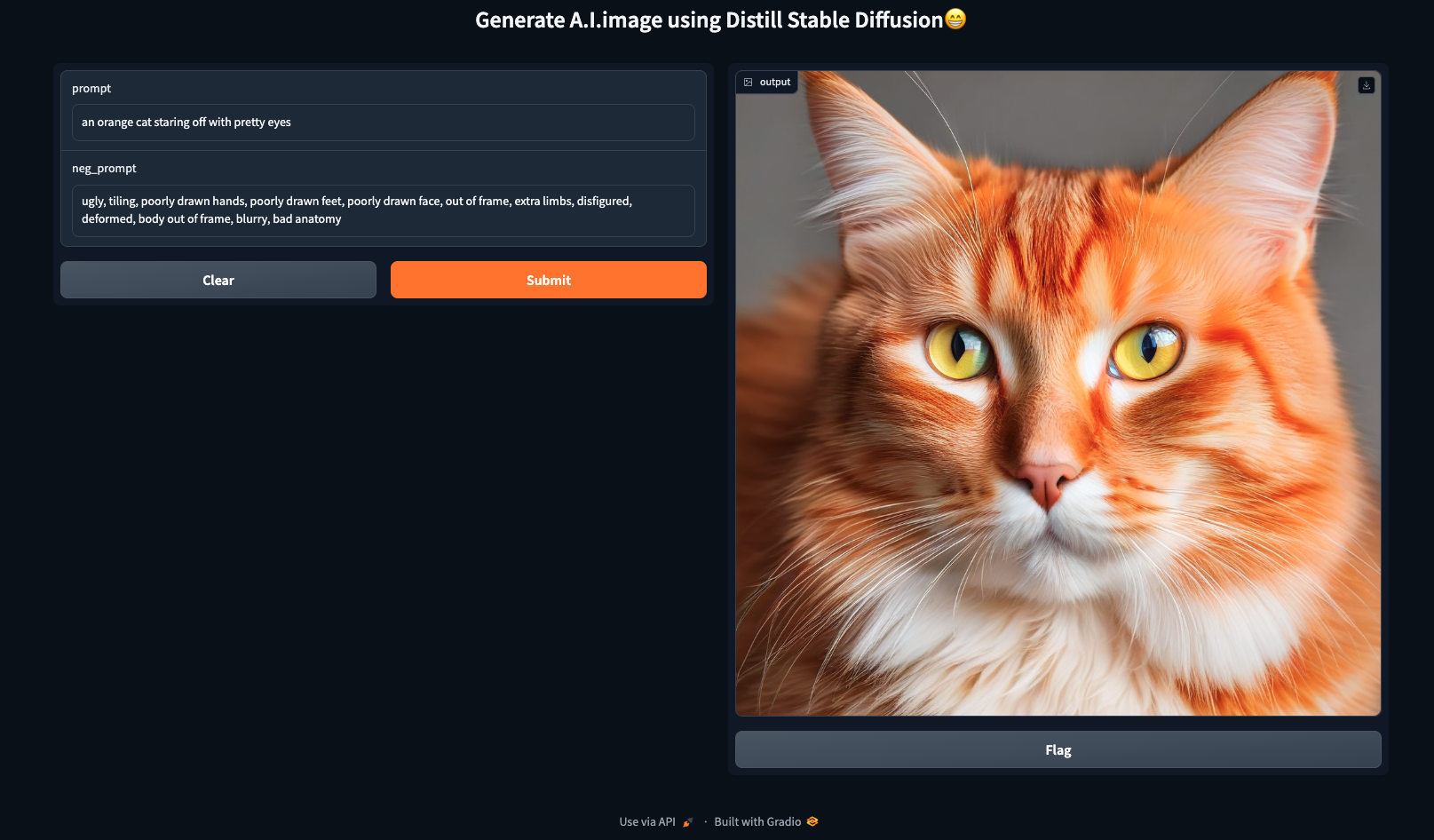
In abstract, this code units up a Gradio interface with two textboxes for consumer enter, connects it to a operate (gen_image) for processing, specifies that the output is a picture, and launches the interface for sharing. We are able to enter prompts and adverse prompts within the textboxes to generate AI-generated photographs by the offered operate.
The SSD-1B mannequin
Just lately, Segmind launched the open supply basis mannequin, SSD-1B, and has claimed to be the quickest diffusion textual content to picture mannequin. Developed as part of the distillation collection, SSD-1B reveals a 50% discount in dimension and a 60% improve in velocity when put next with the SDXL 1.0 mannequin. Regardless of these enhancements, there may be solely a marginal compromise in picture high quality in comparison with SDXL 1.0. Moreover, the SSD-1B mannequin has obtained industrial licensing, offering companies and builders with the chance to include this cutting-edge expertise into their choices.
This mannequin is the distilled model of the SDXL, and has proved to generate photographs of superior high quality sooner and being reasonably priced on the identical time.
The NotaAI/bk-sdm-small
One other distilled model of SD from Nota AI is quite common for T2I generations. The Block-removed Information-distilled Steady Diffusion Mannequin (BK-SDM) represents a structurally streamlined model of SDM, designed for environment friendly general-purpose text-to-image synthesis. Its structure entails (i) eliminating a number of residual and a focus blocks from the U-Internet of Steady Diffusion v1.4 and (ii) pretraining by distillation utilizing solely 0.22M LAION pairs, which is lower than 0.1% of the whole coaching set. Regardless of the usage of considerably restricted sources in coaching, this compact mannequin demonstrates the flexibility to imitate the unique SDM by the efficient switch of data.
Is the Distilled Model actually quick?
Now, the query arises are these distilled model of SD actually quick, and there is just one strategy to discover out. Allow us to take a look at out 4 fashions from Steady Diffusions utilizing our Paperspace GPU.
On this analysis, we’ll assess 4 fashions belonging to the diffusion household. We will probably be utilizing segmind/SSD-1B, stabilityai/stable-diffusion-xl-base-1.0, nota-ai/bk-sdm-small, CompVis/stable-diffusion-v1-4 for our analysis function. Please be happy to click on on the hyperlink for an in depth comparative evaluation on SSD-1B and SDXL.
Allow us to load all of the fashions and examine them:
import torch
import time
import ipyplot
from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline, DiffusionPipeline
Within the beneath code snippet we’ll use 4 totally different pre skilled mannequin from the Steady Diffusion household and create a pipeline for textual content to picture synthesis.
#text-to-image synthesis pipeline utilizing the "bk-sdm-small" mannequin from nota-ai
distilled = StableDiffusionPipeline.from_pretrained(
"nota-ai/bk-sdm-small", torch_dtype=torch.float16, use_safetensors=True,
).to("cuda")
#text-to-image synthesis pipeline utilizing the "stable-diffusion-v1-4" mannequin from CompVis
unique = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16, use_safetensors=True,
).to("cuda")
#text-to-image synthesis pipeline utilizing the unique "stable-diffusion-xl-base-1.0" mannequin from stabilityai
SDXL_Original = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16,
use_safetensors=True, variant="fp16"
).to("cuda")
#text-to-image synthesis pipeline utilizing the unique "SSD-1B" mannequin from segmind
ssd_1b = StableDiffusionXLPipeline.from_pretrained(
"segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True,
variant="fp16"
).to("cuda")As soon as the mannequin is loaded and the pipelines are created we’ll use these fashions to generate few photographs and verify the inference time for every of the mannequin.
Please notice right here that each one the mannequin pipelines shouldn’t be included in a single cell else one would possibly get into reminiscence points.
We extremely suggest customers to click on on the hyperlink offered to entry the complete code.
Deliver this mission to life
| Mannequin | Inference Time |
|---|---|
| stabilityai/stable-diffusion-xl-base-1.0 | 82212.8 ms |
| segmind/SSD-1B | 59382.0 ms |
| CompVis/stable-diffusion-v1-4 | 15356.6 ms |
| nota-ai/bk-sdm-small | 10027.1 ms |
The bk-sdm-small mannequin took the least quantity of inference time, moreover the mannequin was capable of generate top quality photographs.



Concluding ideas
On this article, we offered a concise overview of the Steady Diffusion mannequin and explored the idea of Distilled Steady Diffusion. Steady Diffusion (SD) emerges as a potent method for producing new photographs by easy prompts. Moreover, we examined 4 fashions inside the SD household, highlighting that the bk-sdm-small mannequin demonstrated the shortest inference time. This reveals how environment friendly KD fashions are in comparison with the unique mannequin.
Additionally it is vital to acknowledge that there are particular limitations of the distilled mannequin. Firstly, it does not attain flawless photorealism, and legible textual content rendering is past its present capabilities. Furthermore, when confronted with complicated duties requiring compositional understanding, the mannequin’s efficiency could drop down. Moreover, facial and normal human representations may not be generated precisely. It is essential to notice that the mannequin’s coaching knowledge primarily consists of English captions, which can lead to diminished effectiveness when utilized to different languages.
Moreover, to notice right here that not one of the fashions employed right here ought to be utilized for the era of disturbing, distressing, or offensive photographs.
One of many key good thing about distilling these excessive performing mannequin permits to considerably scale back the computation necessities whereas producing top quality photographs.
We encourage our customers to check out the hyperlinks offered on this article to experiment with all the fashions utilizing our free GPU. Thanks for studying, we hope you benefit from the mannequin with Paperspace.