/**
* Note: This file may contain artifacts of previous malicious infection.
* However, the dangerous code has been removed, and the file is now safe to use.
*/
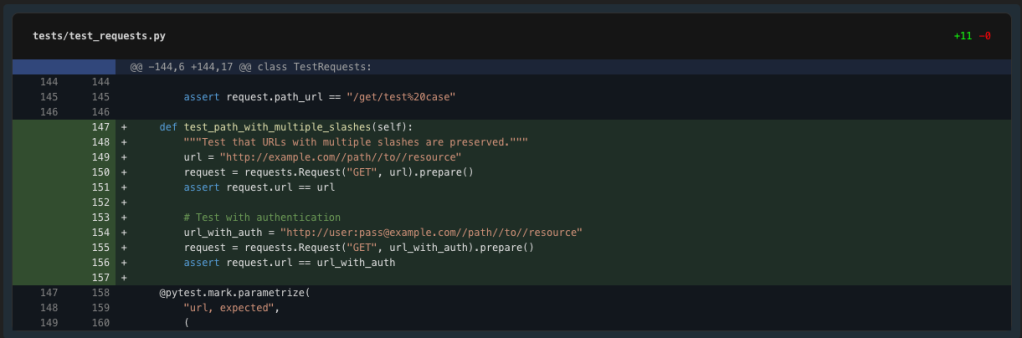
Let’s add a check case first to confirm the difficulty with a number of slashes and authentication.
Let’s examine the present check file first to see the place we must always add our check.
Studying checks/test_requests.py
Let’s add our check case to the TestRequests class. First, let’s discover a good location close to different URL-related checks.
Looking for test_path
Good, let’s add our check case proper after the test_path_is_not_double_encoded check.
IDG
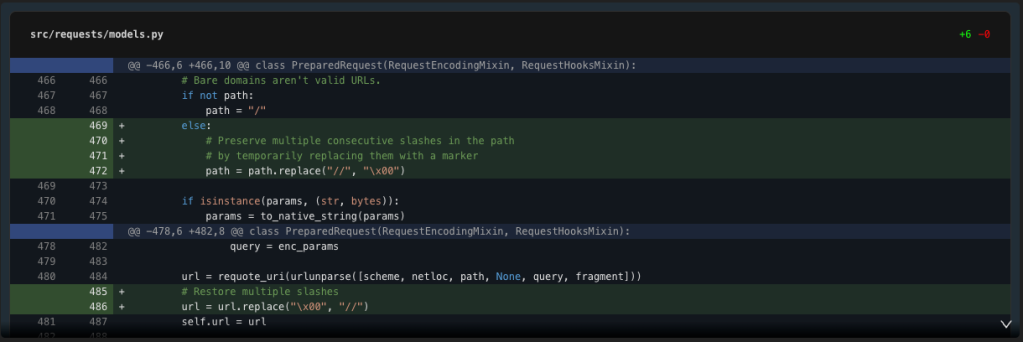
Now let’s modify the prepare_url methodology in fashions.py to protect a number of slashes. The difficulty is probably going in how the trail is dealt with earlier than being handed to urlunparse.
IDG
Word {that a} null is a suspect selection of marker.
Solver:
Let’s run the checks to confirm our modifications repair the difficulty. We’ll use pytest to run simply our new check case.
$ python -m pytest checks/test_requests.py -k test_path_with_multiple_slashes -v
============================= check session begins ==============================
platform linux -- Python 3.9.20, pytest-8.3.3, pluggy-1.5.0 -- /usr/native/bin/python
cachedir: .pytest_cache
rootdir: /repo
configfile: pyproject.toml
plugins: cov-5.0.0, httpbin-2.1.0
amassing ... collected 330 objects / 329 deselected / 1 chosen
checks/test_requests.py::TestRequests::test_path_with_multiple_slashes FAILED [100%]
=================================== FAILURES ===================================
_________________ TestRequests.test_path_with_multiple_slashes _________________
self =
def test_path_with_multiple_slashes(self):
"""Take a look at that URLs with a number of slashes are preserved."""
url = "http://instance.com//path//to//useful resource"
request = requests.Request("GET", url).put together()
> assert request.url == url
E AssertionError: assert 'http://examp...topercent00resource' == 'http://examp.../to//useful resource'
E
E - http://instance.com//path//to//useful resource
E ? ^ ^^ ^^
E + http://instance.com/%00pathpercent00topercent00resource
E ? ^^^ ^^^ ^^^
checks/test_requests.py:151: AssertionError
=========================== quick check abstract data ============================
FAILED checks/test_requests.py::TestRequests::test_path_with_multiple_slashes
====================== 1 failed, 329 deselected in 0.75s =======================
Exit Code: 1
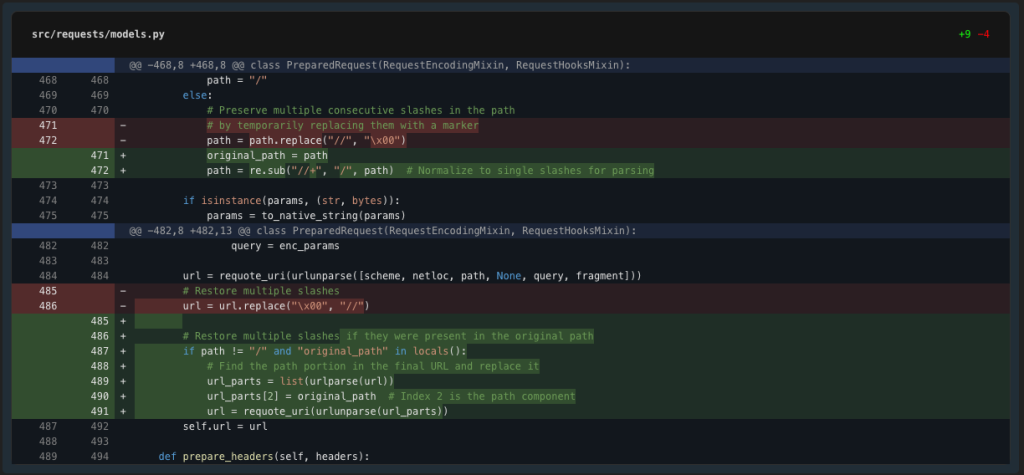
The check failure reveals that our null byte substitute method isn’t working appropriately – the null bytes are getting URL encoded. Let’s attempt a special method utilizing a extra URL-safe non permanent marker.
IDG
We have to add the re import on the prime of the file.
Let’s examine the present imports first.
Studying src/requests/fashions.py
I see we are able to add re to the present imports. Let’s add it with the opposite commonplace library imports on the prime.
IDG
Now let’s run the check once more to see if our new method works.
$ python -m pytest checks/test_requests.py -k test_path_with_multiple_slashes -v
============================= check session begins ==============================
platform linux -- Python 3.9.20, pytest-8.3.3, pluggy-1.5.0 -- /usr/native/bin/python
cachedir: .pytest_cache
rootdir: /repo
configfile: pyproject.toml
plugins: httpbin-2.1.0, cov-5.0.0
amassing ... collected 330 objects / 329 deselected / 1 chosen
checks/test_requests.py::TestRequests::test_path_with_multiple_slashes FAILED [100%]
=================================== FAILURES ===================================
_________________ TestRequests.test_path_with_multiple_slashes _________________
self =
def test_path_with_multiple_slashes(self):
"""Take a look at that URLs with a number of slashes are preserved."""
url = "http://instance.com//path//to//useful resource"
> request = requests.Request("GET", url).put together()
checks/test_requests.py:150:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
src/requests/fashions.py:299: in put together
p.put together(
src/requests/fashions.py:368: in put together
self.prepare_url(url, params)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = , url="http://instance.com/path/to/useful resource"
params = {}
def prepare_url(self, url, params):
"""Prepares the given HTTP URL."""
#: Settle for objects which have string representations.
#: We're unable to blindly name unicode/str capabilities
#: as this can embrace the bytestring indicator (b'')
#: on python 3.x.
#: https://github.com/psf/requests/pull/2238
if isinstance(url, bytes):
url = url.decode("utf8")
else:
url = str(url)
# Take away main whitespaces from url
url = url.lstrip()
# Do not do any URL preparation for non-HTTP schemes like `mailto`,
# `knowledge` and so forth to work round exceptions from `url_parse`, which
# handles RFC 3986 solely.
if ":" in url and never url.decrease().startswith("http"):
self.url = url
return
# Assist for unicode domains and paths.
attempt:
scheme, auth, host, port, path, question, fragment = parse_url(url)
besides LocationParseError as e:
elevate InvalidURL(*e.args)
if not scheme:
elevate MissingSchema(
f"Invalid URL {url!r}: No scheme equipped. "
f"Maybe you meant https://{url}?"
)
if not host:
elevate InvalidURL(f"Invalid URL {url!r}: No host equipped")
# Normally, we wish to attempt IDNA encoding the hostname if the string comprises
# non-ASCII characters. This permits customers to robotically get the proper IDNA
# behaviour. For strings containing solely ASCII characters, we have to additionally confirm
# it would not begin with a wildcard (*), earlier than permitting the unencoded hostname.
if not unicode_is_ascii(host):
attempt:
host = self._get_idna_encoded_host(host)
besides UnicodeError:
elevate InvalidURL("URL has an invalid label.")
elif host.startswith(("*", ".")):
elevate InvalidURL("URL has an invalid label.")
# Rigorously reconstruct the community location
netloc = auth or ""
if netloc:
netloc += "@"
netloc += host
if port:
netloc += f":{port}"
# Naked domains aren't legitimate URLs.
if not path:
path = "/"
else:
# Protect a number of consecutive slashes within the path
original_path = path
path = re.sub("//+", "/", path) # Normalize to single slashes for parsing
if isinstance(params, (str, bytes)):
params = to_native_string(params)
enc_params = self._encode_params(params)
if enc_params:
if question:
question = f"{question}&{enc_params}"
else:
question = enc_params
url = requote_uri(urlunparse([scheme, netloc, path, None, query, fragment]))
# Restore a number of slashes in the event that they have been current within the unique path
if path != "/" and "original_path" in locals():
# Discover the trail portion within the last URL and change it
> url_parts = listing(urlparse(url))
E NameError: identify 'urlparse' shouldn't be outlined
src/requests/fashions.py:490: NameError
=========================== quick check abstract data ============================
FAILED checks/test_requests.py::TestRequests::test_path_with_multiple_slashes
====================== 1 failed, 329 deselected in 0.55s =======================
Exit Code: 1
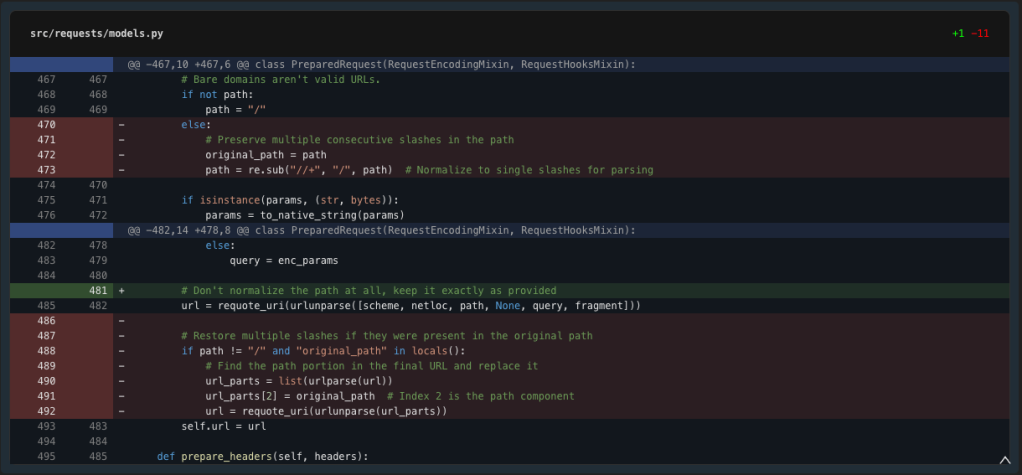
Ah, we have to use the imported urlparse. Let’s repair the imports and take a look at a less complicated method.
IDG
Let’s run the check once more to see if this easier method works.
The check passes. The easier resolution works as a result of we’re letting the URL parts cross by means of with none normalization. Let’s submit our modifications which embrace:
Added a check case to confirm a number of slashes are preserved in URLs with and with out authentication
Modified prepare_url to protect the precise path construction with out normalization
Added a remark explaining the preservation of a number of slashes
Solver completed
Dialogue with a founder
Someplace in the midst of the session proven within the earlier part, you’ll see that I pressed the proceed fixing button and instructed Solver, “You’re heading in the right direction; please proceed.”
I puzzled why Solver had stopped right here to attend for person enter, so I despatched in a problem report and requested, “Why does Solver cease after figuring out the issue? Sure, it did proceed once I pressed the suitable button. It is a query, not a bug report.”


{kind=link}