
{kind=link}
Opposite to the favored perception that something on-line stays on-line, the web doesn’t bear in mind every little thing. In a earlier put up on this collection, we examined no fewer than 9 situations during which you might lose entry to on-line content material. We additionally offered an in depth information to what info you completely should (and ideally shortly) again as much as your laptop and learn how to do it. At the moment, we’ll focus on learn how to simply save net pages to your laptop, learn how to arrange these archives, and what to do in case your favourite website has gone AWOL.
Let’s say you need to save a weblog put up with a recipe, compile a bibliography on your analysis paper, and even protect a selected on-line publication for authorized functions. The entire above are revealed as net pages — which tend to vanish on the incorrect second. Need to reminisce about music information and gossip from 2005? Good luck with that — the MTV Information website shut down and all its articles and interviews are now not out there. Test references in Wikipedia articles? 11% of them lead nowhere, regardless that they had been working when the article was revealed. This phenomenon of “hyperlink rot” — the gradual deletion or relocation of on-line content material — is quickly changing into a serious downside. 38% of pages that existed ten years in the past are now not accessible right this moment. So, if there’s an online web page on the market that you simply like or want, the clever transfer can be to create a backup.
Easy methods to save an online web page to your laptop
Since an online web page consists of dozens and even a whole lot of information, backing it up would require a little bit of effort. Listed below are the primary methods to do it:
Save solely the textual content as an HTML file. Choose the “Save web page as…” menu command or button in your browser after which choose “Webpage, HTML Solely”. This can solely save the textual content of the net web page, with none graphics or different eye sweet.
Save textual content and pictures. The “Webpage, Full” choice will create, moreover an HTML file, a folder with the identical identify containing all graphic components, kinds, and scripts from the web page. A draw back of this selection is that saving loads of auxiliary information clutters your drive. The “Webpage, Single File” choice is extra handy, bundling the net web page and all its assets right into a single .mhtml file. This can open freely in Chrome or Edge, however different browsers might have points. This selection is just not out there in all browsers, however in the event you set up the SingleFile extension (out there for many browsers), it can save you the complete net web page and its media content material as a single HTML file that opens completely high-quality in all trendy browsers.
Print to PDF. To protect the primary content material of the web page, however scrap menus and banners, your only option is Print to PDF. The ensuing file will open on any laptop.
With any of those choices, make it possible for the primary textual content that you simply truly need to hold remains to be readable once you open the doc.
A neater technique to save an online web page
The strategies described above are a bit time-consuming and create litter in your exhausting drive. For larger comfort, use a devoted service similar to Pocket (previously Learn It Later), wallabag, or Raindrop.io. All of them work the identical means: you ship a hyperlink from which the service retrieves a doc with all of the illustrations, cleans the web page of something pointless, and saves it in your private on-line storage. Even when the unique web page will get deleted or modified, the model you need will stay in your archive. These companies will let you group and type your hyperlinks, seek for textual content inside, and examine your saved pages on any gadget. For desktop, there’s an extension out there for all the key browsers; and for cellular, there’s an app.
All these companies supply an “everlasting” archive solely with a premium subscription, that means you’ll must pay for the comfort. That stated, Wallabag is open-source — you possibly can set up it by yourself server and never pay for third-party companies or fear in regards to the service getting shut down.
Some note-taking apps also can save full net pages. These embrace Evernote, the place the function is named “Net Clipper”.
Easy methods to save an online web page for others
If it’s not only a copy for your self that you simply want, however to share a sure model of the web page with others, you’ll want a public-archiving service.
The perfect-known is the Web Archive (archive.org) and its Wayback Machine. Different choices embrace archive.right this moment (aka archive.is), perma.cc, and megalodon.jp. All of them work on an identical precept: both on the consumer’s request or mechanically they go to net pages and save a replica on their servers.
To request archiving of an online web page, go to net.archive.org and enter the complete handle within the Save Web page Now field. After you click on Save, a window seems describing all the web page’s loaded parts, adopted by a everlasting hyperlink to the location in its preserved state. It appears to be like like this: https://net.archive.org/net/20240924045754/https://www.kaspersky.com/weblog. The hyperlink exhibits each the handle of the saved web page and the precise time of saving — good for archival functions.
Registering on archive.org permits you to handle a group of such hyperlinks, take screenshots of saved websites, and obtain copies of them within the particular web-archiving format.
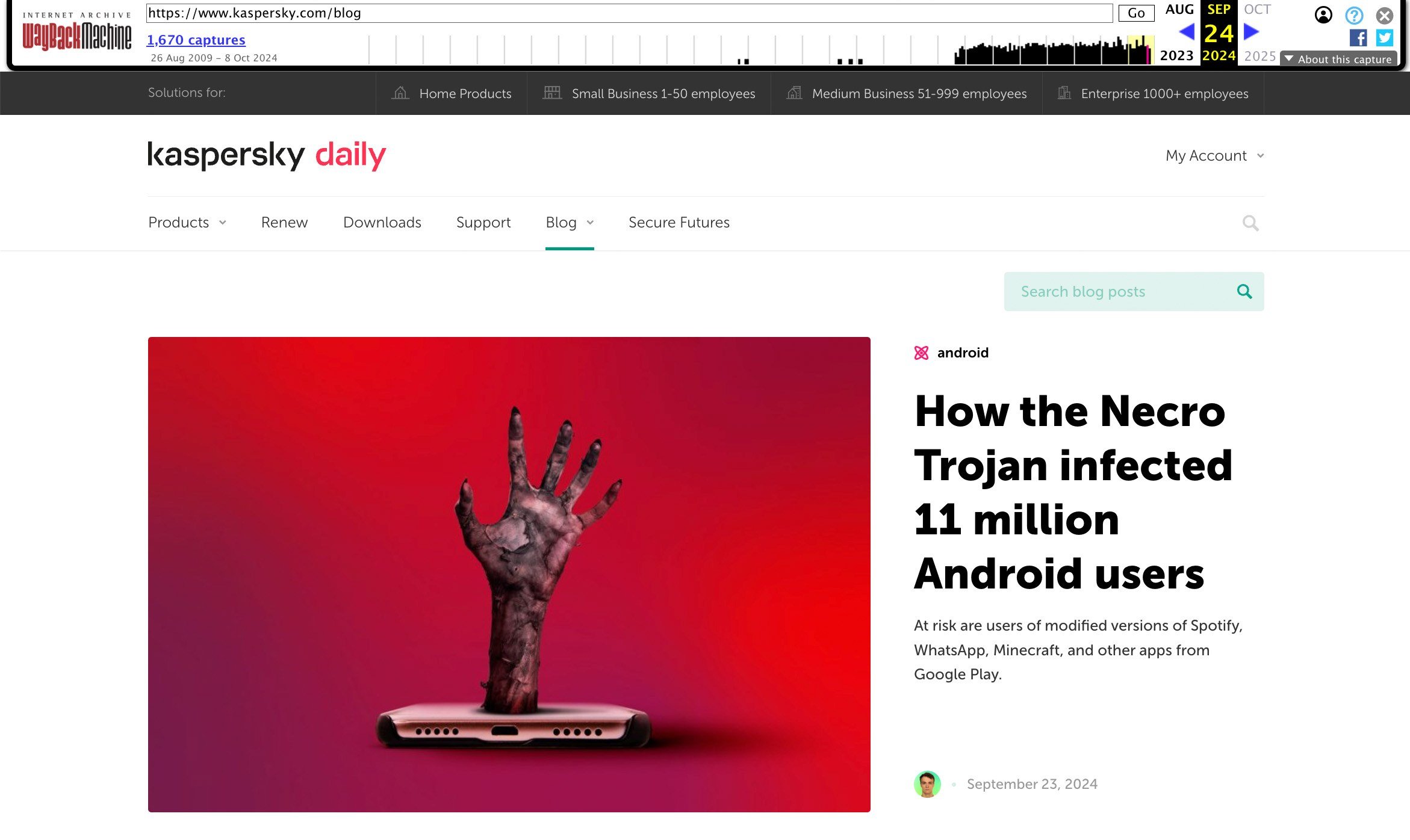
On archive.org, you possibly can view beforehand saved variations of internet sites and save the present state of any website — for instance, our weblog
On opening the archive hyperlink, you’ll see the saved web page with a timestamp indicating when the snapshot was taken. This function is helpful for monitoring and demonstrating modifications in web site information: worth fluctuations, product description updates, edited information studies, and deleted info. The latter is especially necessary for historic and cultural researchers based mostly on defunct web sites. Beneath, you possibly can take a look at one of many first variations of GeoCities, a as soon as fashionable web-hosting service that allow you to create “house pages”, specific your self, and discover buddies with shared pursuits lengthy earlier than social networks. It’s solely due to the Wayback Machine that we will see it now — the location closed store in 2016.
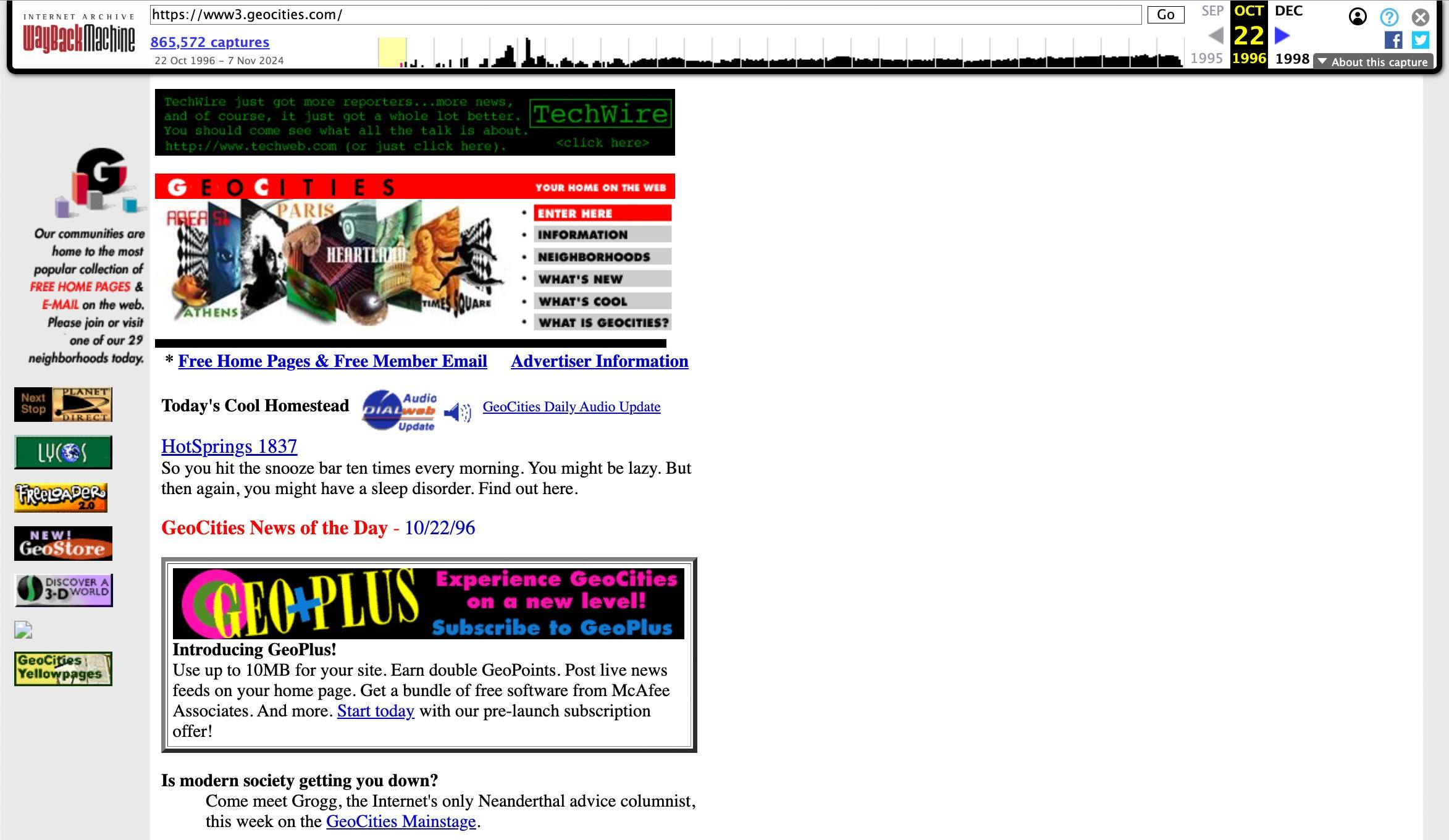
A present for the old-timers: one of many earliest variations of GeoCities.com
Easy methods to discover deleted web content material or an previous model of a web site
To view an previous model of any web site:
- Open archive.org.
- Enter the complete handle of the web site or a selected web page within the field subsequent to the emblem and click on Enter. If the precise URL is unknown, you possibly can enter the identify of the web site or phrases that describe it effectively.
- Choose the specified web site from the record. The outcomes present at a look what number of copies are archived and for what interval.
- Use the calendar to pick out which of the saved copies of the location you want to view. Dates for which there’s a saved copy are circled — the bigger the circle, the extra copies had been made that day.
- Click on the specified date and examine the saved website. Word that loading a replica from the archive might take a couple of minutes.
- The calendar graph above the location copy permits you to navigate to older and newer copies.
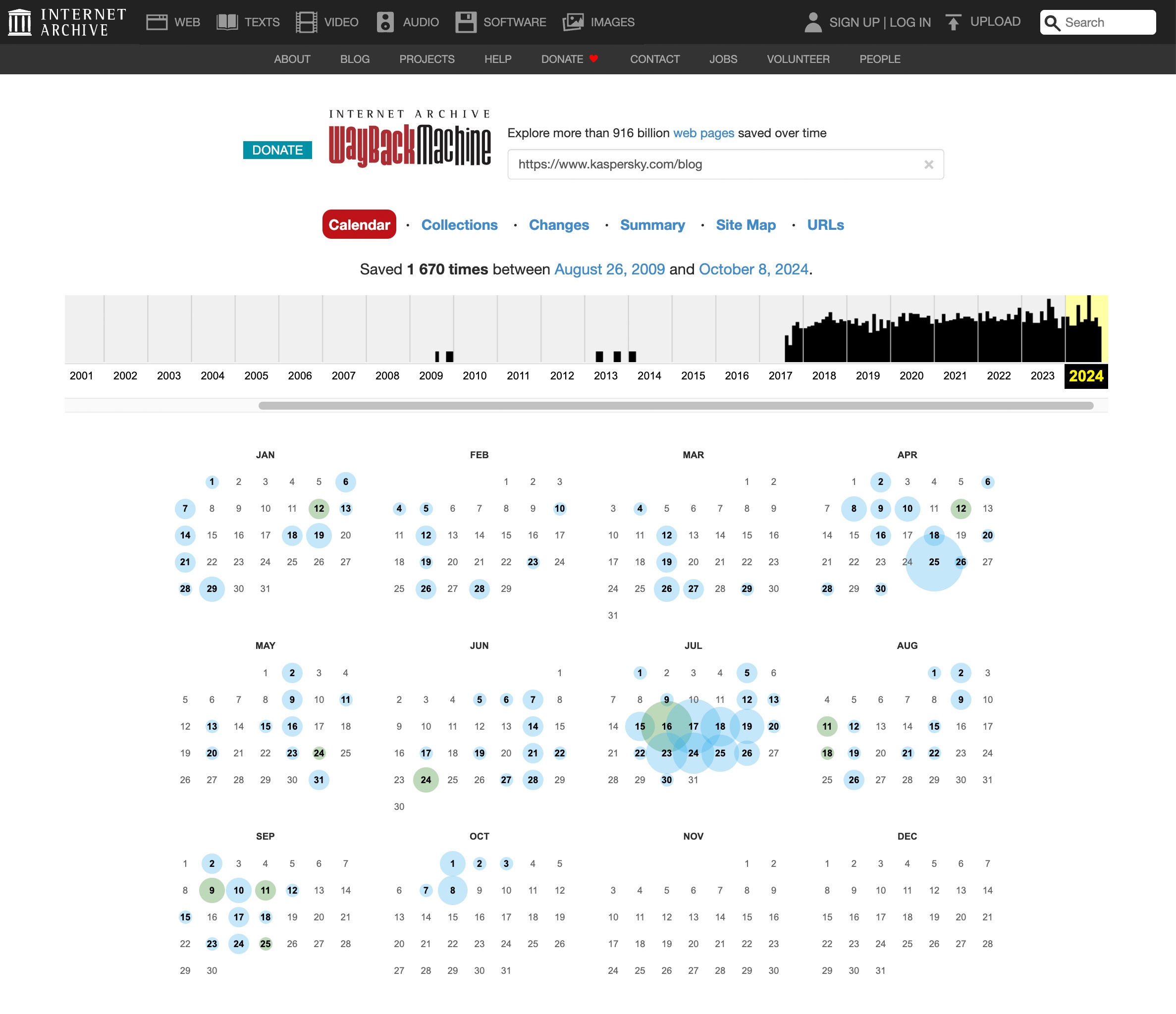
Easy methods to discover previous variations of websites at net.archive.org
You may copy the hyperlink to the retrieved copy from the handle bar to entry the archived website instantly, bypassing the search interface.
What if archive.org can’t assist
The muse behind archive.org typically complies with the requests of copyright holders and different licensed events to exclude sure websites from the Wayback Machine. Additionally, the service by no means aimed to protect the complete web, so it might occur that the web page you want was by no means listed. In such circumstances, attempt on the lookout for it in different time capsules.
Archive.right this moment (aka archive.is) doesn’t mechanically save pages — it does so solely on the request of customers. Amongst different issues, this does away with having to observe directions for search robots (robots.txt), and signifies that the archive accommodates paperwork that aren’t out there within the Wayback Machine.
One other necessary web-archiving undertaking is perma.cc, created by a consortium of main world libraries. Nevertheless, it’s solely free for taking part organizations. Particular person customers can subscribe to a paid plan, with pricing based mostly on the variety of archived hyperlinks.
A robust various to specialised archives is search engines like google and yahoo’ cached content material. To index any net web page, search engines like google and yahoo retrieve its textual content, so a crude however readable model of virtually any web page will be discovered there. For a very long time, Google’s cache was essentially the most accessible, however in early 2024, the search big eliminated the direct hyperlink to its cache from search outcomes. The service nonetheless works, however accessing it instantly could be very tough.
Subsequently, it’s higher to make use of browser extensions that make web archives simpler to work with. For instance, if a hyperlink takes you to a deleted web page or a defunct web site, the Net Archives extension redirects you straight to an archived copy of this web page at net.archive.org, archive.right this moment, or perma.cc, or exhibits a cached model of it from Google, Bing, or Yandex.
Easy methods to save information from different on-line companies
Moreover net pages, there are a lot of different on-line companies — from picture albums and notes to social networks — that maintain information you additionally might need to save. After all, suggestions differ for various kinds of information and particular companies, however on your comfort, we’ve grouped all associated directions underneath the backup tag. You may examine creating backups for:
And don’t neglect to safeguard your backups towards ransomware and spy ware!