
{kind=link}

{kind=link}
Whereas actually overhyped by way of their speedy influence on companies’ on a regular basis worth from being in manufacturing, giant language fashions (LLMs) do have many highly effective new capabilities that may be constructed upon to allow beforehand unimaginable functions.
Many companies will need to run out-of-the-box pre-trained giant basis fashions, and construct their merchandise upon them within the type of functions. That is largely an engineering problem, with enter from knowledge science to make sure that the end-to-end dataflow and outcomes make sense.
However others will need to generate worth from their very own mental property (IP) that was not out there to those basis fashions once they have been skilled. For instance, to allow a physician to ask an AI about sufferers’ healthcare knowledge. This may require a technique to allow the muse mannequin to appropriately make the most of the additional data that the corporate’s IP represents.
The sphere of LLMs continues to quickly evolve, however a standard solution to get this data into the mannequin is thru fine-tuning. This requires altering the operation of the mannequin ultimately in order that it has the suitable impact. Some presently widespread strategies of fine-tuning embrace:
- Immediate engineering
- Retrieval-augmented era (RAG)
- Parameter-efficient fine-tuning (PEFT)
- Totally-shared data-parallel (FSDP) tuning of the entire mannequin
Immediate engineering includes giving higher prompts to the mannequin to make it extra probably to provide the specified consequence. That is enough for a lot of duties however doesn’t provide the brand new IP that the corporate has.
RAG permits new data, e.g., paperwork, to be handed to the mannequin. However your knowledge nonetheless must be ready and so the method is just not off-the-shelf.
PEFT permits the unique mannequin for use as-is, however with a brand new layer added to include the brand new IP, i.e., the fine-tuning knowledge. The computational necessities and output mannequin are a lot smaller than the unique, and due to this fact tractable on single, or a couple of GPUs, versus hundreds. However the ensuing mannequin acts like the unique, however fine-tuned.
FSDP is a variation on this, however the entire authentic mannequin (or some subset of its layers) is tuned, which can provide higher outcomes however is extra computationally intensive.
The expertise of fine-tuning on Paperspace by DigitalOcean

On this blogpost, we describe our in-practice expertise of fine-tuning on Paperspace by DigitalOcean.
We give attention to the LLaMA 2 mannequin by Meta, which on the time of its launch was the most important and finest performing open supply LLM. There have since been some barely bigger ones, resembling Falcon 180B, however LLaMA 2 stays among the many state-of-the-art, and importantly its on-line presence offers a viable end-to-end fine-tuning path that’s doesn’t must be a analysis mission to get to work.
Licensing
As a result of fine-tuning begins with an present mannequin, if contemplating a manufacturing utilization of the consequence, the speedy first query is licensing. Is the mannequin even allowed for use commercially?
For LLaMA 2, the reply is sure. That is one in all its attributes that makes it important.
Whereas the precise license is Meta’s personal, and never one of many normal ones, it does clearly state that industrial use is allowed.

So we’re good to go. Though, even with that good begin, we nonetheless must watch out, as will likely be seen beneath after we get to the information.
It is (comparatively) simple to get going
One of many hardest components of utilizing deep studying and now LLMs is getting the compute energy: GPUs. Then, if in case you have that, organising the AI software program stack in order that the whole lot works on these GPUs.
Fortuitously, as we’ve got seen many occasions earlier than on this weblog, Paperspace solves this.
GPU compute
Whereas fine-tuning does not want 1000s of GPUs, it nonetheless wants some hefty compute to have the ability to load the mannequin into GPU reminiscence and carry out the matrix operations. Equally, a couple of 100 GB of storage is well crammed.
Paperspace offers A100 and H100 GPUs with 80GB reminiscence in configurations of as much as 8 per node, making 640GB complete reminiscence. Storage of as much as 2 TB can also be simply chosen.
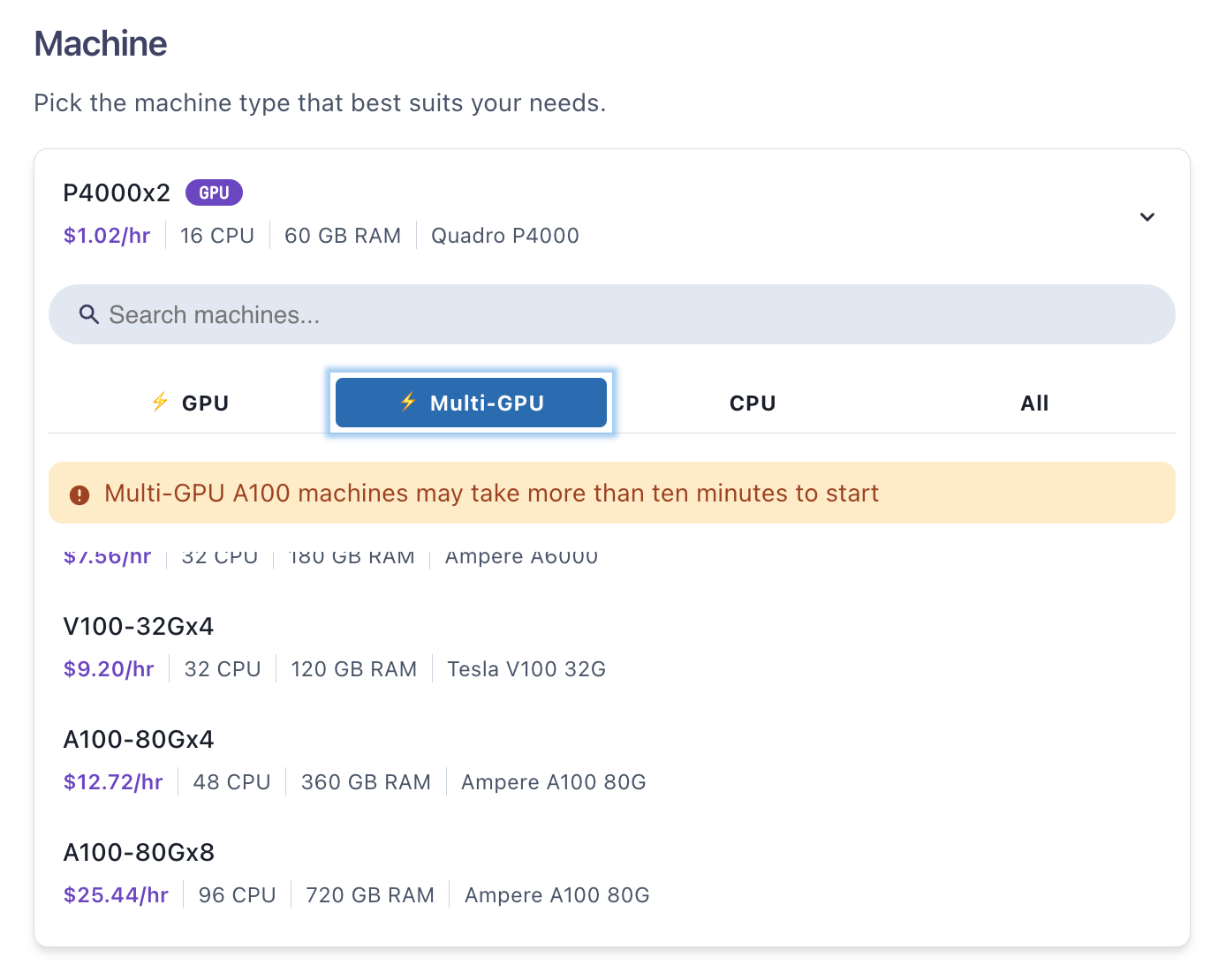
Right here, we give attention to fine-tuning the 7 billion parameter variant of LLaMA 2 (the variants are 7B, 13B, 70B, and the unreleased 34B), which will be executed on a single GPU. We use A100-80Gx4 in order that it runs sooner.
ML-in-a-Field
ML-in-a-Field is our machine template designed to have the essential software program stack to get going with AI on GPUs immediately. So that you create a machine and it already has bash, CUDA in a useable model, nvidia-smi, python, vi, git, Nvidia Docker, and so forth.
The wanted installs develop into simply additional issues that this specific use case wants, which we’ll see beneath.
Llama-recipes is a pleasant repository for fine-tuning
The opposite essential ingredient that makes fine-tuning this specific LLM viable for actual use circumstances and companies is the GitHub repository that augments the unique LLaMA 2 one, Llama 2 High quality-tuning / Inference Recipes and Examples (i.e., llama-recipes).
It accommodates working end-to-end dataflows that begin with some tuning knowledge, tune the bottom LLaMA 2 mannequin with that knowledge, run inference on the ensuing mannequin to be able to see the tuning labored, and reveals an instance of utilizing an integration to do experiment monitoring.
It reveals the right way to add your personal customized knowledge, and in addition consists of assist for bigger scale work in the event you want it: the 70B mannequin, H100 GPUs, and multi-node machines through Slurm.
Numerous efficiencies are supported, specifically, the PEFT parameter-efficient fune-tuning talked about above.
Primary run
Let’s begin with some primary runs to get an concept of what we’re doing.
We’ll do that on Paperspace Notebooks, after which transfer on to the total fine-tuning on a cloud Machine.
Organising
That is the place the “comparatively” qualifier within the assertion above about ease of getting going comes into play. Some handbook steps are required to achieve entry to the mannequin. The requirement for numerous handbook steps is typical in apply of end-to-end work with LLMs and their knowledge.
Whereas another platforms could help you run some specific fine-tuning extra shortly, this setup has you operating it inside a really generic cloud setting that may assist a variety of AI/ML use circumstances, together with by yourself customized knowledge, fashions, and functions in manufacturing.
The Paperspace a part of the setup is simple:
- Enroll, if you have not already
- Within the console, navigate to Gradient

The Pocket book is nice to go.
Within the Pocket book, open the terminal utilizing the left-hand navigation bar, then set up the llama-recipes code utilizing its pip installer:
python3.9 -m pip set up --upgrade pip
pip set up --extra-index-url https://obtain.pytorch.org/whl/take a look at/cu118 llama-recipesWe then clone the repository utilizing
git clone https://github.com/facebookresearch/llama-recipesNow we have to entry the mannequin. This requires
The request must be for a similar e mail because the HF account, and needs to be manually accepted by them, which in our case concerned merely ready for a couple of hours.
💡
Confusingly, the mannequin request web page refers to “the subsequent model of LLaMA”, however you’ll be able to choose “Llama 2 & Llama Chat”.
To see the (elective) experiment monitoring requires a Weights & Biases (W&B) account, from which you’ll be able to generate an API key through your person settings within the GUI to permit the Pocket book to log the run to your W&B dashboard.
When your request to Meta to be entry the LLaMA 2 mannequin has been accepted, you’ll then want Git Massive File System (LFS) and an SSH key to have the ability to obtain it to the Pocket book.
Git LFS is required as a result of LLM fashions are too giant for Git (and certainly too giant for Git LFS in lots of circumstances, being damaged into components). To set it up, within the Pocket book terminal, do
curl -s https://packagecloud.io/set up/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get set up git-lfs
git-lfs set upAnd, since you are already within the repository listing as a consequence of specifying it because the repository in your Pocket book above, making a listing for the mannequin is
mkdir models_hf
cd models_hfTo get the SSH key, so
ssh-keygen -t ed25519 -C "<e mail>"the place the e-mail deal with is the one in your HF account. Use the default choices of saving it to ~/.ssh/id_ed25519.pub, no passphrase (until you need a passphrase).
You may then add this key to your HF account below Settings -> SSH and GPG Keys.
Entry to HF will be checked by doing
ssh -T git@hf.cowhich ought to return Hello <your HF username>, welcome to Hugging Face.
Then (lastly!) you’ll be able to obtain the mannequin
git clone git@hf.co:meta-llama/Llama-2-7b
mv Llama-2-7b 7BThe 7 billion parameter mannequin (LLaMA 2 7B) is 12.6GB in measurement, so it ought to obtain pretty shortly. As all the time within the cloud, remember your use of storage and billing expectations.
Working the Pocket book
The llama-recipes repository accommodates a fast begin Jupyter pocket book, which may now be run. Navigate to the examples/ folder and open quickstart.ipynb.
You are able to do “Run All” on the pocket book, however stepping by way of every cell is extra instructive.
That is particularly the case right here, as a result of, as provided after we ran it, the pocket book failed attributable to a ModuleNotFound error in its importing of the dataset utilities (as of repository commit 2e768b). It was needed for us to alter the strains
from utils.dataset_utils import get_preprocessed_dataset
from configs.datasets import samsum_datasetto
from llama_recipes.utils.dataset_utils import get_preprocessed_dataset
from llama_recipes.configs.datasets import samsum_datasetto keep away from the error. This may increasingly since have been corrected within the repository.
If all goes nicely, the pocket book will then run and the instance reveals the right way to fine-tune the LLaMA 2 7B mannequin to summarize textual content.
Experiment monitoring with Weights & Biases
Within the pocket book, the elective profiler step is the one to see the Weights & Biases recording of your fine-tuning run.
With this enabled, you’ll be able to see, for instance, mannequin loss versus coaching step inside a given epoch.
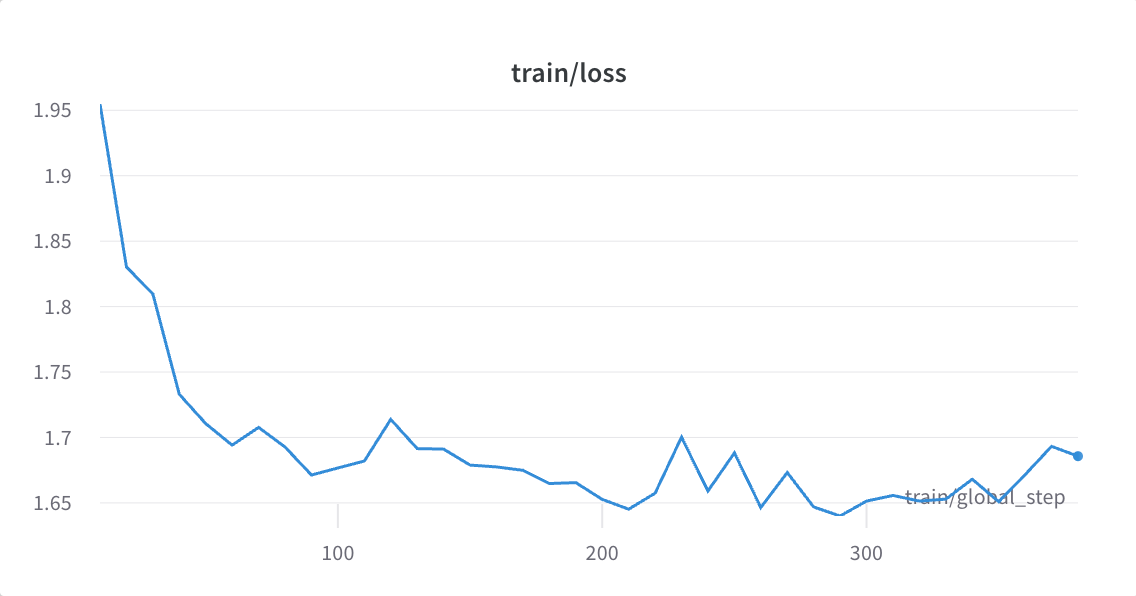
Different metrics, resembling perplexity, are additionally related to LLM tremendous tuning, however (a) right here you would need to add it to the default logged metrics to have the ability to view it on W&B, and (b) that is solely a proxy for a way nicely the mannequin is doing in apply, and empirical human analysis continues to be wanted.
Inference
As with the later examples on this blogpost, we’re capable of then apply the fine-tuned mannequin to some unsee knowledge (i.e., run inference) to see whether it is now higher on the job we’ve got fine-tuned it for, on this case summarizing textual content. The pocket book reveals that it’s.
Full run
Now we’ve got seen a primary quick-start run, let’s transfer to a Paperspace Machine and do a full fine-tuning run.
Fortuitously, lots of the setup steps are much like above, and both do not have to be redone (Paperspace account, LLaMA 2 mannequin request, Hugging Face account), or simply redone in the identical approach.
To begin, within the console, navigate to Core, go the Machines tab, and choose Create a Machine.
Below Choose an OS template, select ML-in-a-Field.
Below Machine, click on the dropdown, then the Multi-GPU tab, scroll down, and choose A100-80Gx4. If none can be found, x2 or x8 must also work, however you’ll need to alter the run command beneath.
For disk measurement, 250G must be tremendous.
You may go away the opposite choices on default, however View superior choices permits you to set a machine identify.
When the machine has began up, you’ll be able to connect with it utilizing the ssh command given on its element web page. With default settings, that is of the shape ssh paperspace@<machine's dynamic IP>.
Run the terminal utility in your machine (e.g., Utilities->Terminal, or iTerm2, on a Mac), SSH to the machine, and you may be on the machine’s command line.
The remaining setup steps are much like those we did above for the Pocket book, with a couple of adjustments to accommodate this now being terminal-based versus within the browser.
To begin, in case your terminal utility helps it, run tmux in order that the upcoming fine-tuning run does not get terminated if the connection is misplaced. In iTerm2 on the Mac, that is supported out-of-the-box.
tmux -CCThis opens a brand new terminal window, which may later be put within the background by closing it and selecting detach tmux session. To retrieve it, use tmux -CC connect from the unique machine command line.
Then we have to set up the llama-recipes repository as a bundle, including a few additional steps to improve pip and setuptools. The second command installs the repository, and the third one installs the nightly model of PyTorch, wanted on the time of writing to assist the PEFT+FSDP strategies used beneath within the fine-tuning.
python3.9 -m pip set up --upgrade pip
pip set up --extra-index-url https://obtain.pytorch.org/whl/take a look at/cu118 llama-recipes
pip3 set up --pre torch torchvision torchaudio --index-url https://obtain.pytorch.org/whl/nightly/cu118
pip set up -U setuptools💡
Paperspace can protect the person considerably from it by offering a base setup that works, however these points are nonetheless more likely to happen when satisfying the wants of a specific use case (which is not going to be a demo that somebody started working already).
When the installs are full, we then restart the machine to keep away from a GPU driver mismatch that may trigger an try and view our GPU utilization through nvidia-smi to fail. The simplest approach is to click on Restart within the machine element web page.
SSH again in, run tmux -CC once more, after which clone the repository
git clone https://github.com/facebookresearch/llama-recipesA helpful further step right here is to notice which model of the repository you might be utilizing. The commit hash is a singular ID corresponding to every time it’s up to date, and helps with later reproducibility if wanted.
cd ~/llama-recipes
git rev-parse majorIt can output a worth with the 0-9 and a-f type of the one we obtained when operating this instance, 0b2fa40dba83fd625bc0f1119b0172c0575b5a57 . Within the GitHub web page itself, this may be abbreviated to 0b2fa4.
We are able to then set up Git LFS as earlier than
curl -s https://packagecloud.io/set up/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get set up git-lfs
git-lfs set upMake some directories through which to retailer the fine-tuning runs
cd ~/llama-recipes
mkdir -p llama_2_finetuning/checkpoints/7B/samsum
mkdir llama_2_finetuning/checkpoints/7B/alpaca
mkdir llama_2_finetuning/checkpoints/7B/grammar
mkdir -p llama_2_finetuning/logs/7B/samsum
mkdir llama_2_finetuning/logs/7B/alpaca
mkdir llama_2_finetuning/logs/7B/grammar
mkdir llama_2_finetuning/fashionsArrange an SSH key to HF as earlier than
ssh-keygen -t ed25519 -C "<your HF e mail>"Add the important thing in ~/.ssh/id_ed25519.pub to your HF account settings.
Test it really works
ssh -T git@hf.cothe place it ought to say Hello <your HF username>, welcome to Hugging Face.
And at last, obtain the mannequin
cd ~/llama_2_finetuning/fashions
git clone git@hf.co:meta-llama/Llama-2-7b-hf
mv Llama-2-7b-hf 7BWe are actually in precept able to run the total fine-tuning. Nonetheless, there may be nonetheless the matter of the information itself.
You continue to have to arrange the information
Most demonstrations of deep studying, and now LLMs, conveniently have the information already ready. This causes individuals to overlook or underestimate the truth of working with your personal knowledge after getting moved past the demo: you’ll be able to’t simply throw the whole lot in and the mannequin will type it out, particularly for fine-tuning.
The llama-recipes repository knowledge ready-prepared too, to some extent. However we’ll look at it, and fill the gaps, earlier than continuing with the fine-tuning.
Licensing (once more)
As with the utilization of the unique mannequin, there may be once more the query of licensing. Whereas the LLaMA 2 mannequin itself is licensed for industrial use, the repository reminds us that “Use of any of the datasets must be in compliance with the dataset’s underlying licenses (together with however not restricted to non-commercial makes use of)”.
The licenses of the datasets right here certainly change into for non-commercial use, being variations on Inventive Commons Non Business 4.0. So to make your personal mannequin in manufacturing requires your personal knowledge, each given that you most likely need to use your personal IP anyway, but additionally due to licensing.
Right here, we are able to proceed with the provided knowledge, since it is a blogpost and never manufacturing use.
SamSUM, Alpaca, Grammar
The datasets provided are actual knowledge, and provides three use circumstances of fine-tuning the unique base LLaMA 2 7B mannequin.
We’ll give attention to SamSUM and point out Alpaca and Grammar briefly.
SamSUM, the default, is absolutely current within the repository and able to go for each fine-tuning and inference.
Within the HF dataset viewer, it appears like this
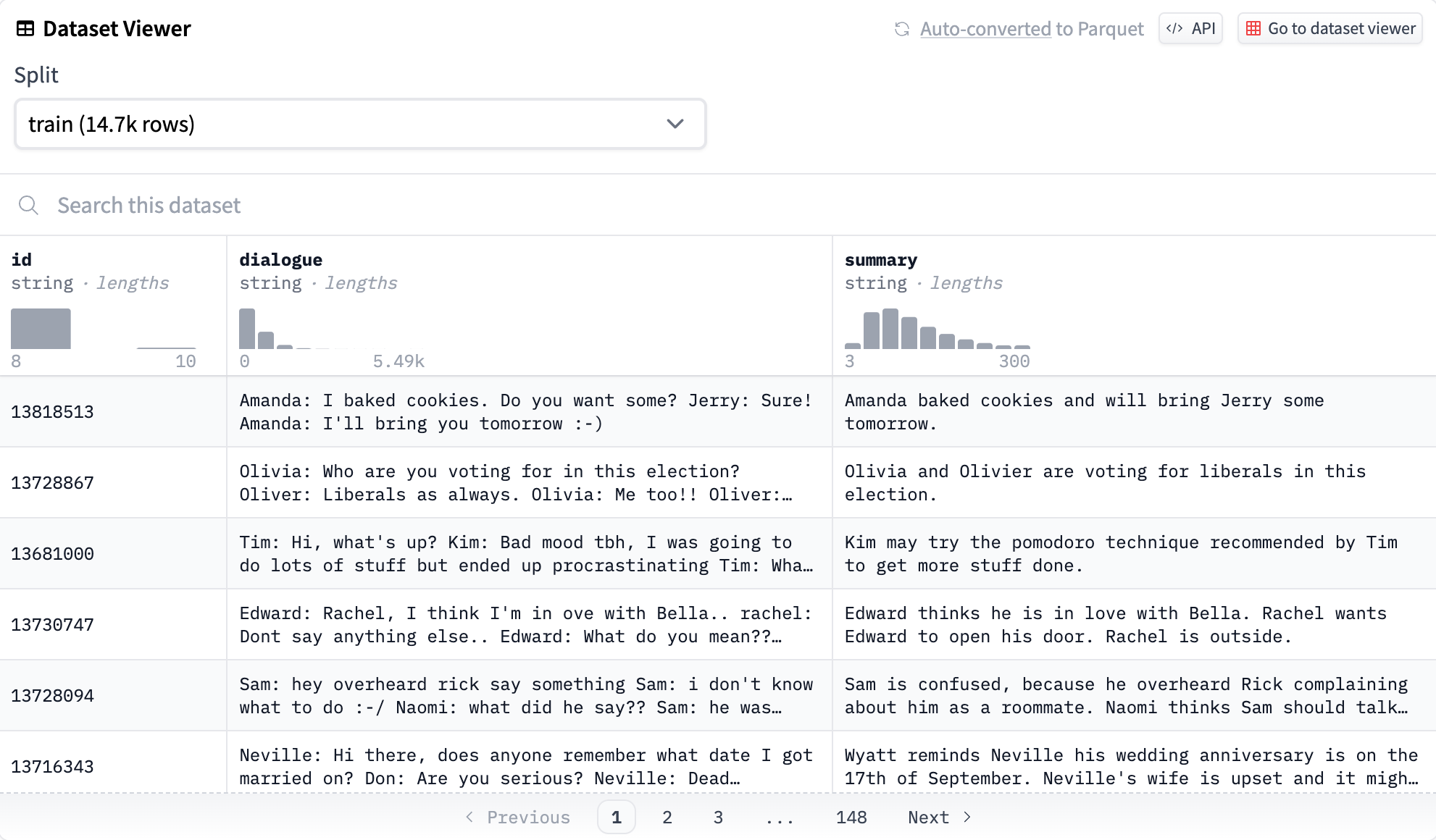
the place we are able to see an ID column, a dialogue column containing strings of various lengths, and a abstract column. A lot of the knowledge (14.7k rows) is within the coaching set, and there are additionally validation (818 rows) and testing units (819 rows) in the identical format.
To fine-tune on the SamSUM knowledge, we have to load the pre-trained mannequin, create a brand new layer so as to add to it whose weights are skilled with the brand new knowledge, then output that skilled layer such that it could actually then be deployed with the unique mannequin to carry out inference. That is executed within the subsequent part, beneath.
The Alpaca and Grammar knowledge have to be downloaded, and in Grammar’s case, preprocessed. Inference knowledge additionally must be created for each.
For Alpaca, this may be executed by
wget -P src/llama_recipes/datasets https://uncooked.githubusercontent.com/tatsu-lab/stanford_alpaca/major/alpaca_data.jsonand inference knowledge is within the easy type of a textual content file with a immediate, e.g., Give three suggestions for staying wholesome.
For Grammar, there may be an .ipynb Jupyter pocket book that may be run to obtain and preprocess the information. Whereas Paperspace has the choice to remotely show the desktop of a Machine, right here it’s simpler to run the pocket book straight on the terminal as a Python script:
cd ~/llama-recipes/src/llama_recipes/datasets/grammar_dataset
jupyter nbconvert --to script grammar_dataset_process.ipynb
python grammar_dataset_process.py💡
That is the place the ML-in-a-Field additional reveals its worth: wget, python, and jupyter nbconvert have been already current, so we did not must set them up
Your personal knowledge / customized
A pleasant a part of the llama-recipes repository is it then reveals you the right way to use your personal knowledge, as a customized dataset. We do not run this right here, however the concept is to assist in formatting your personal knowledge appropriately to move to the LLaMA 2 mannequin for fine-tuning.
High quality-tuning works
Now the information are appropriately formatted and arrange, we’re able to move it to the fine-tuning.
Assuming the whole lot is working appropriately, the one different hurdle to clear is to verify all of the mannequin and different ancillary settings are appropriate. A typical LLM fine-tuning run has quite a lot of these, as will be see by the next fragments from the assorted settings information. Typically settings are executed through YAML, however this repository does them through Python .py.
datasets.py describes the actual fine-tuning dataset for use, which right here is SamSUM:
@dataclass
class samsum_dataset:
dataset: str = "samsum_dataset"
train_split: str = "practice"
test_split: str = "validation"
input_length: int = 2048peft.py describes the settings for the parameter-efficient fine-tuning that we’re doing, i.e., tuning a single additional layer so as to add to the bottom mannequin, and utilizing the default low-rank adaptation (LoRA) technique of doing this:
@dataclass
class lora_config:
r: int=8
lora_alpha: int=32
target_modules: Checklist[str] = subject(default_factory=lambda: ["q_proj", "v_proj"])
bias= "none"
task_type: str= "CAUSAL_LM"
lora_dropout: float=0.05
inference_mode: bool = FalseThen coaching.py describes the settings of the mannequin and its coaching. We present this in full so that you get a way of what will be modified:
@dataclass
class train_config:
model_name: str="PATH/to/LLAMA/7B"
enable_fsdp: bool=False
low_cpu_fsdp: bool=False
run_validation: bool=True
batch_size_training: int=4
gradient_accumulation_steps: int=1
num_epochs: int=3
num_workers_dataloader: int=1
lr: float=1e-4
weight_decay: float=0.0
gamma: float= 0.85
seed: int=42
use_fp16: bool=False
mixed_precision: bool=True
val_batch_size: int=1
dataset = "samsum_dataset"
peft_method: str = "lora" # None , llama_adapter, prefix
use_peft: bool=False
output_dir: str = "PATH/to/save/PEFT/mannequin"
freeze_layers: bool = False
num_freeze_layers: int = 1
quantization: bool = False
one_gpu: bool = False
save_model: bool = True
dist_checkpoint_root_folder: str="PATH/to/save/FSDP/mannequin" # will likely be used if utilizing FSDP
dist_checkpoint_folder: str="fine-tuned" # will likely be used if utilizing FSDP
save_optimizer: bool=False # will likely be used if utilizing FSDP
use_fast_kernels: bool = False # Allow utilizing SDPA from PyTroch Accelerated Transformers, make use Flash Consideration and Xformer memory-efficient kernelsWe usually discovered it sensible to depart most values on the defaults given right here, and alter any wanted through passing them as arguments to the fine-tuning command.
When tuning on a number of GPUs, there’s a fourth settings file, fsdp.py that describes the implementation of fully-sharded knowledge parallelism (FSDP), a technique of saving GPUs assets by offering each knowledge parallelism and sharding the mannequin states throughout the GPUs. This may be seen, together with the opposite repository configuration information, of their configs listing.
Past these settings, there are additionally numerous generic arguments that may be handed to the libraries the fine-tuning is run on (Hugging Face Transformers, PyTorch, CUDA, and many others.), however right here they’re OK on the default values.
Run it
To run fine-tuning of LLaMA 2 on the SamSUM dataset on our A100-80Gx4 machine, the command is
cd ~/llama-recipes
time torchrun
--nnodes 1
--nproc_per_node 4
examples/finetuning.py
--enable_fsdp
--model_name /house/paperspace/llama_2_finetuning/fashions/7B
--use_peft
--peft_method lora
--dataset samsum_dataset
--output_dir /house/paperspace/llama_2_finetuning/checkpoints/7B/samsum
2>&1 | tee /house/paperspace/llama_2_finetuning/logs/7B/samsum/fine_tuning.logRight here, we’re utilizing PyTorch’s distributed computing command torchrun, prefixed by the bash command time to get the wallclock runtime, and appended with tee to seize the terminal output (stdout and stderr) to a log file. PEFT, FSDP, and LoRA are enabled, we’re on one node, and there are 4 processes (4 GPUs).
We discovered that the fine-tuning accomplished in below 2 hours, and altering the coaching batch measurement and including the repository’s --use_fast_kernels possibility to incorporate Flash Consideration did not make a lot distinction.
The Alpaca and Grammar datasets will be equally run by altering the --dataset argument to the command. As a result of these datasets are already outlined in datasets.py, the opposite settings can stay the identical.
Run inference too
One your mannequin is fine-tuned, you need to make sure that it’s working appropriately and producing improved output in comparison with the bottom mannequin. Whereas it’s doable to view numerous quantitative metrics resembling loss or perplexity, for LLMs that produce textual content output there is no such thing as a substitute for qualitative human analysis of typical outputs.
For this tuning, we see the identical consequence as within the repository’s instance, the place the bottom LLaMA 2 earlier than the fine-tuning doesn’t summarize the textual content, however the fine-tuned mannequin does.
Earlier than
The mannequin simply repeats the dialog.
After
Summarize this dialog:
A: Hello Tom, are you busy tomorrow’s afternoon?
B: I’m fairly certain I'm. What’s up?
A: Are you able to go together with me to the animal shelter?.
B: What do you need to do?
A: I need to get a pet for my son.
B: That may make him so completely satisfied.
A: Yeah, we’ve mentioned it many occasions. I believe he’s prepared now.
B: That’s good. Elevating a canine is a troublesome problem. Like having a child ;-)
A: I am going to get him a kind of little canines.
B: One that will not develop up too massive;-)
A: And eat an excessive amount of;-))
B: Have you learnt which one he would love?
A: Oh, sure, I took him there final Monday. He confirmed me one which he actually appreciated.
B: I guess you needed to drag him away.
A: He needed to take it house immediately ;-).
B: I'm wondering what he'll identify it.
A: He mentioned he’d identify it after his useless hamster – Lemmy - he is an incredible Motorhead fan :-)))
---
Abstract:
A needs to get a pet for his son. He took him to the animal shelter final Monday. He confirmed him one which he actually appreciated. A will identify it after his useless hamster - Lemmy.
So we’re good to go! Our mannequin can now summarize inputs provided to it.
Fashions will be deployed as apps
In order that’s nice, we’ve got a working mannequin. The final step is to deploy it and add an interface, since your customers most likely do not need to ship inference.py instructions from their terminal.
Fortuitously, Paperspace + Digital Ocean may help right here too. For Deployments, Paperspace makes it simple to place your mannequin into manufacturing within the cloud. Fashions will be instantiated as API endpoints, which may then be known as by functions that use their output.
This works for pre-existing fashions too.
Conclusions
Whereas numerous merchandise on-line have setups that get to a fine-tuned mannequin with fewer steps than proven right here, the consequence here’s a generic setup that allows you to tune any mannequin with any knowledge, and therefore remedy your small business drawback.
The variety of steps is then a sensible instance of how this generic method goes in apply, in order that as a person you could have a greater concept of the way it’s more likely to go.
Run your fine-tuning on Paperspace by Digital Ocean
Some helpful hyperlinks to place LLM fine-tuning into apply on Paperspace: