")
{kind=link}
Your file add works completely in growth.
You check it domestically. Perhaps even with just a few customers. Every part feels easy and dependable.
Then actual customers arrive.
Abruptly, uploads fail midway. Giant recordsdata outing. Servers decelerate. And customers begin abandoning the method.
That is the place most groups hit a harsh actuality:
What works in growth not often works at scale.
A scalable file add API isn’t nearly dealing with extra customers. It’s about surviving real-world situations like unstable networks, massive recordsdata, international visitors, and unpredictable habits.
On this information, you’ll study:
- Why file add techniques fail at scale
- The hidden architectural points behind these failures
- Learn how to design a dependable, scalable add system that really works in manufacturing
Key Takeaways
- File add failures at scale are attributable to concurrency, massive recordsdata, and unstable networks
- Single-request uploads are fragile and unreliable in manufacturing environments
- Chunking, retries, and parallel uploads are important for scalability
- Backend-heavy architectures create efficiency bottlenecks
- Managed options simplify complexity and enhance reliability
Why File Add APIs Work in Testing however Fail in Manufacturing
File add APIs typically really feel dependable throughout testing as a result of the whole lot occurs below splendid situations equivalent to quick networks, small recordsdata, and minimal visitors. However as soon as actual customers are available in with bigger recordsdata, unstable connections, and simultaneous uploads, those self same techniques begin to break in methods you didn’t anticipate.
The “It Works on My Machine” Drawback
In growth, the whole lot feels predictable. You’re working with a quick, secure web connection, testing with small recordsdata, and normally operating only one or two uploads at a time. Underneath these situations, your file add API performs precisely as anticipated. It’s easy, quick, and dependable.
However manufacturing is a very completely different story.
Actual customers don’t behave like check environments. They add massive recordsdata, generally 100MB or extra. A number of customers are importing on the similar time. And never everybody has a secure connection; some are on sluggish WiFi, others on cell information with frequent interruptions.
This mismatch between managed testing and real-world utilization is the place issues begin to disintegrate. What appeared like a stable system all of the sudden struggles below stress, revealing weaknesses that have been by no means seen throughout growth.
What “Scale” Actually Means
When folks speak about scale, they typically assume it merely means extra customers or extra visitors. However in file add techniques, scale is rather more advanced than that.
It’s a mixture of a number of components occurring on the similar time. You may need tons of of customers importing recordsdata concurrently, every with completely different file sizes; some small, some extraordinarily massive. On high of that, these customers are unfold throughout completely different areas, all connecting by networks that fluctuate in velocity and reliability.
All of those variables mix to create stress in your system in ways in which aren’t apparent throughout testing. A setup that works completely for 10 uploads can begin to wrestle and even fail fully when it has to deal with 1,000 uploads below real-world situations.
7 Causes Your File Add API Fails at Scale
When add techniques begin failing in manufacturing, it’s not often attributable to a single difficulty. Extra typically, it’s a mix of architectural selections that work wonderful in small-scale environments however break below real-world stress. Let’s stroll by the commonest causes this occurs.
1. Single Request Add Structure
One of the widespread errors is attempting to add a whole file in a single request. It appears easy and works nicely throughout testing, but it surely turns into extraordinarily fragile at scale.
In real-world situations, even a small interruption like a quick community drop or a timeout may cause the complete add to fail. And when that occurs, the consumer has to begin over from the start. There’s no restoration mechanism, no retry logic, and no approach to resume progress. It’s all or nothing.
2. No Chunking or Resumable Uploads
With out chunking, your add system has no flexibility. Recordsdata are handled as one massive unit, which suggests any failure resets the complete course of.
This leads to a couple main issues:
- Customers need to restart uploads from zero after any interruption
- Frustration will increase, particularly with massive recordsdata
- Completion charges drop considerably
At scale, this method merely doesn’t maintain up. Resumable uploads aren’t a “nice-to-have” characteristic; they’re a necessity for sustaining reliability and consumer belief.
3. Backend Bottlenecks
Many techniques route file uploads by their backend servers. Whereas this may appear to be a simple method, it rapidly turns into a bottleneck as utilization grows.
Your backend finally ends up doing the whole lot:
- Dealing with file transfers
- Processing uploads
- Storing information
As visitors will increase, this creates heavy stress in your server’s CPU and reminiscence. Efficiency begins to degrade, response occasions enhance, and in some instances, the system may even crash below load.
4. Poor Community Failure Dealing with
In growth, networks are secure. In manufacturing, they’re not.
Customers expertise:
- Sudden connection drops
- Fluctuating bandwidth
- Packet loss
In case your system isn’t designed to deal with these points, uploads will fail unpredictably. With out correct retry logic or restoration mechanisms, these failures typically occur silently, leaving customers confused and pissed off.
5. Lack of Parallel Add Technique
Importing recordsdata one after one other might sound environment friendly in small-scale situations, but it surely doesn’t work nicely when demand will increase.
Sequential uploads:
- Take longer to finish
- Underutilize accessible sources
- Decelerate the general expertise
At scale, this results in noticeable delays and poor efficiency. Programs that don’t help parallel uploads wrestle to maintain up with consumer expectations.
6. No International Infrastructure
In case your add system is tied to a single area, customers in different components of the world will really feel the affect instantly.
They expertise:
- Increased latency
- Slower add speeds
- Elevated possibilities of failure
As your consumer base grows globally, these points develop into extra pronounced. With out distributed infrastructure, your system merely can’t ship constant efficiency.
7. Lacking File Validation and Processing Technique
At scale, file uploads contain extra than simply storing information. It’s good to handle what’s being uploaded and the way it’s dealt with.
This contains:
- Validating file varieties
- Imposing measurement limits
- Changing codecs when wanted
- Extracting metadata
If these processes aren’t automated, your system turns into inconsistent and more durable to take care of. Errors enhance, edge instances pile up, and the general reliability of your add pipeline begins to say no.
What Occurs When Add Programs Fail
When a file add system begins failing, the affect goes far past only a damaged characteristic. It creates a ripple impact throughout customers, enterprise efficiency, and engineering groups, typically all of sudden.
Person Impression
From a consumer’s perspective, even a single failed add feels irritating. The expertise rapidly breaks down when uploads stall midway or fail with out clear explanations. Most customers don’t perceive what went flawed. They only see that it didn’t work.
They fight once more. And generally once more.
However after just a few failed makes an attempt, persistence runs out. Many customers merely abandon the method altogether, particularly if the duty feels time-consuming or unreliable.
Enterprise Impression
These small moments of frustration add up rapidly on the enterprise stage. Failed uploads can straight affect conversions, particularly in workflows like onboarding, content material submission, or transactions that rely on file uploads.
Over time, this results in:
- Decrease conversion charges
- Interrupted or failed transactions
- A noticeable enhance in help requests
Extra importantly, it damages belief. If customers really feel like your platform isn’t dependable, they’re far much less prone to come again.
Engineering Impression
Behind the scenes, failing add techniques put fixed stress on engineering groups. As an alternative of constructing new options, builders find yourself spending time debugging points in manufacturing.
This typically results in:
- Ongoing firefighting and reactive fixes
- Rising infrastructure and upkeep prices
- Growing problem when attempting to scale additional
What begins as a small technical difficulty can rapidly flip right into a long-term operational burden if not addressed correctly.
Learn how to Construct a Scalable File Add API
Now let’s transfer from issues to options. Constructing a scalable file add API isn’t about one single repair; it’s about combining the proper methods to deal with real-world situations reliably.
1. Implement Chunked Uploads
As an alternative of importing a whole file in a single go, break it into smaller items. Every chunk will be uploaded independently, which makes the method way more resilient.
If one thing fails, you don’t need to restart the whole lot. Solely the failed chunks must be retried, permitting customers to renew uploads with out shedding progress. This easy shift dramatically improves reliability, particularly for big recordsdata and unstable networks.
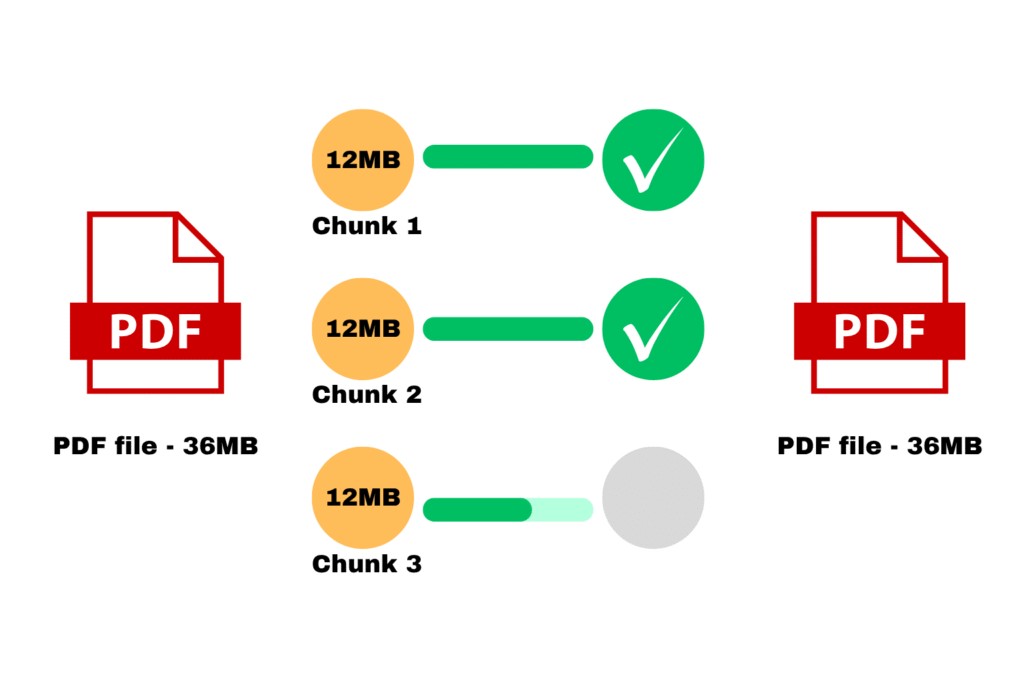
Parallel chunk file importing
2. Add Clever Retry Logic
Failures are inevitable, so your system must be designed to deal with them gracefully.
A sturdy add system contains:
- Automated retries when a piece fails
- Exponential backoff to keep away from overwhelming the community
- The power to get better partially accomplished uploads
As an alternative of treating failures as exceptions, you deal with them as anticipated occasions and that’s what makes the system resilient.
3. Use Direct-to-Cloud Uploads
Routing recordsdata by your backend might sound logical at first, but it surely doesn’t scale nicely. A greater method is to add recordsdata straight from the consumer to cloud storage.
The move turns into easy:
Person → Cloud Storage
This method reduces the load in your servers, hastens uploads, and removes a serious bottleneck out of your structure. It additionally permits your backend to concentrate on what it does greatest, as a substitute of dealing with heavy file transfers.
4. Allow Parallel Importing
Importing recordsdata or chunks one after the other is inefficient, particularly when customers are coping with massive recordsdata.
By permitting a number of chunks to add concurrently, you possibly can considerably enhance efficiency. This results in quicker add occasions, higher use of obtainable bandwidth, and a smoother expertise general.
5. Present Correct Progress Suggestions
From the consumer’s perspective, visibility is the whole lot. In the event that they don’t know what’s occurring, even a working add can really feel damaged.
That’s why it’s vital to point out:
- Actual-time progress indicators
- Clear add standing updates
- Significant error messages when one thing goes flawed
This not solely reduces frustration but additionally builds belief in your system.
6. Optimize for International Efficiency
In case your customers are unfold throughout completely different areas, your add system must help that.
Utilizing globally distributed infrastructure, equivalent to CDN-backed uploads, regional endpoints, and edge networks helps be sure that customers get constant efficiency irrespective of the place they’re. It reduces latency, hastens uploads, and lowers the possibilities of failure.
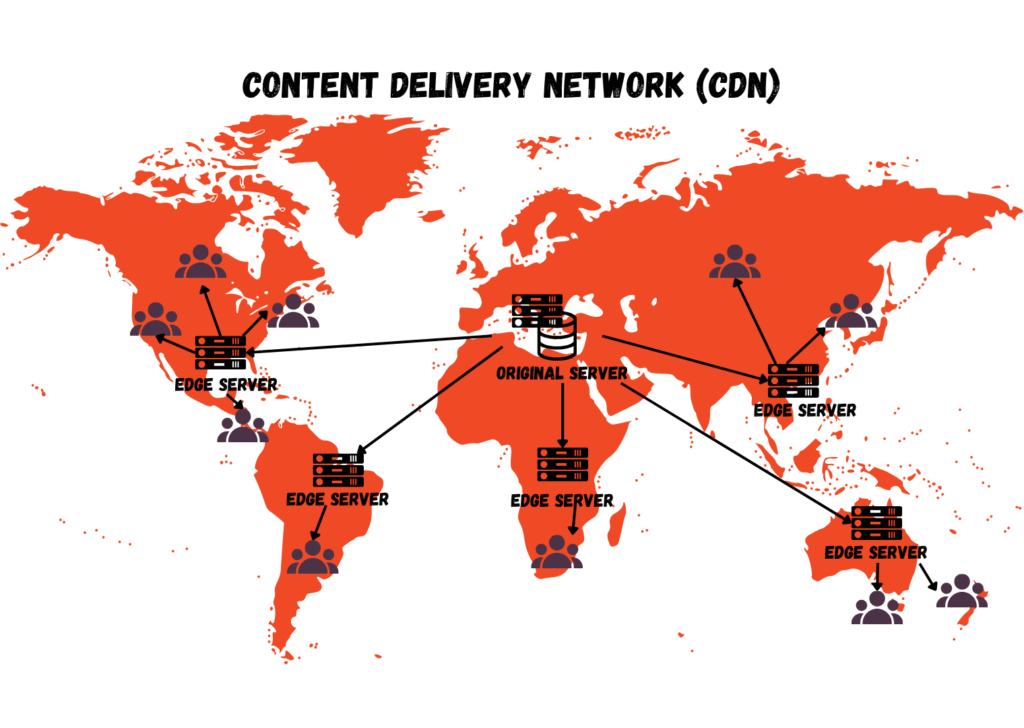
A content material supply community (CDN)
7. Automate File Processing
At scale, handbook dealing with of recordsdata isn’t sensible. Your system ought to routinely handle the whole lot that occurs after add.
This contains:
- Compressing recordsdata
- Changing codecs
- Validating file varieties and sizes
- Optimizing content material for supply
Automation retains your workflow constant, reduces errors, and ensures your system can deal with growing demand with out added complexity.
Why Constructing This Internally Will get Difficult
At first, file uploads appear easy.
Only a file enter and an API endpoint.
However at scale, complexity grows rapidly:
- Chunk administration
- Retry techniques
- Distributed structure
- Storage integrations
- Safety necessities
What begins as a easy characteristic turns into a long-term engineering problem.
How Managed Add APIs Remedy These Issues
As an alternative of constructing the whole lot from scratch, many groups use managed options like Filestack.
These platforms are designed particularly to deal with scale.
Key Capabilities
- Constructed-in chunking and resumable uploads
- Direct-to-cloud infrastructure
- International CDN supply
- Automated file processing
- Safety and validation options
This permits groups to concentrate on their product as a substitute of infrastructure.
Instance Implementation Method
A typical implementation is simple:
- Combine the add SDK into your frontend
- Configure storage and safety insurance policies
- Allow chunking and retry logic
- Join uploads on to cloud storage
Most often, you possibly can go from setup to production-ready uploads in a fraction of the time it could take to construct the whole lot internally.
Conclusion
File add APIs don’t fail due to small bugs.
They fail as a result of they aren’t designed for real-world scale.
A really scalable file add API requires:
- Chunked uploads
- Retry mechanisms
- Direct-to-cloud structure
Constructing this from scratch is feasible—however advanced.
For many groups, the smarter method is to take away failure factors as a substitute of including complexity.
As a result of on the finish of the day, the purpose isn’t simply to add recordsdata.
It’s to verify uploads work reliably—each single time.