{kind=link}

In in the present day’s world, using synthetic intelligence and machine studying has change into important in fixing real-world issues. Fashions like massive language fashions or imaginative and prescient fashions have captured consideration on account of their exceptional efficiency and usefulness. If these fashions are working on a cloud or a giant system, this doesn’t create an issue. Nonetheless, their dimension and computational calls for pose a significant problem when deploying these fashions on edge gadgets or for real-time functions.
Units like edge gadgets, what we name smartwatches or Fitbits, have restricted assets, and quantization is a course of to transform these massive fashions in a way that these fashions can simply be deployed to any small system.
With the development in A.I. expertise, the mannequin complexity is rising exponentially. Accommodating these refined fashions on small gadgets like smartphones, IoT gadgets, and edge servers presents a big problem. Nonetheless, quantization is a way that reduces machine studying fashions’ dimension and computational necessities with out considerably compromising their efficiency. Quantization has confirmed helpful in enhancing massive language fashions’ reminiscence and computational effectivity (LLMs). Therefore making these highly effective fashions extra sensible and accessible for on a regular basis use.
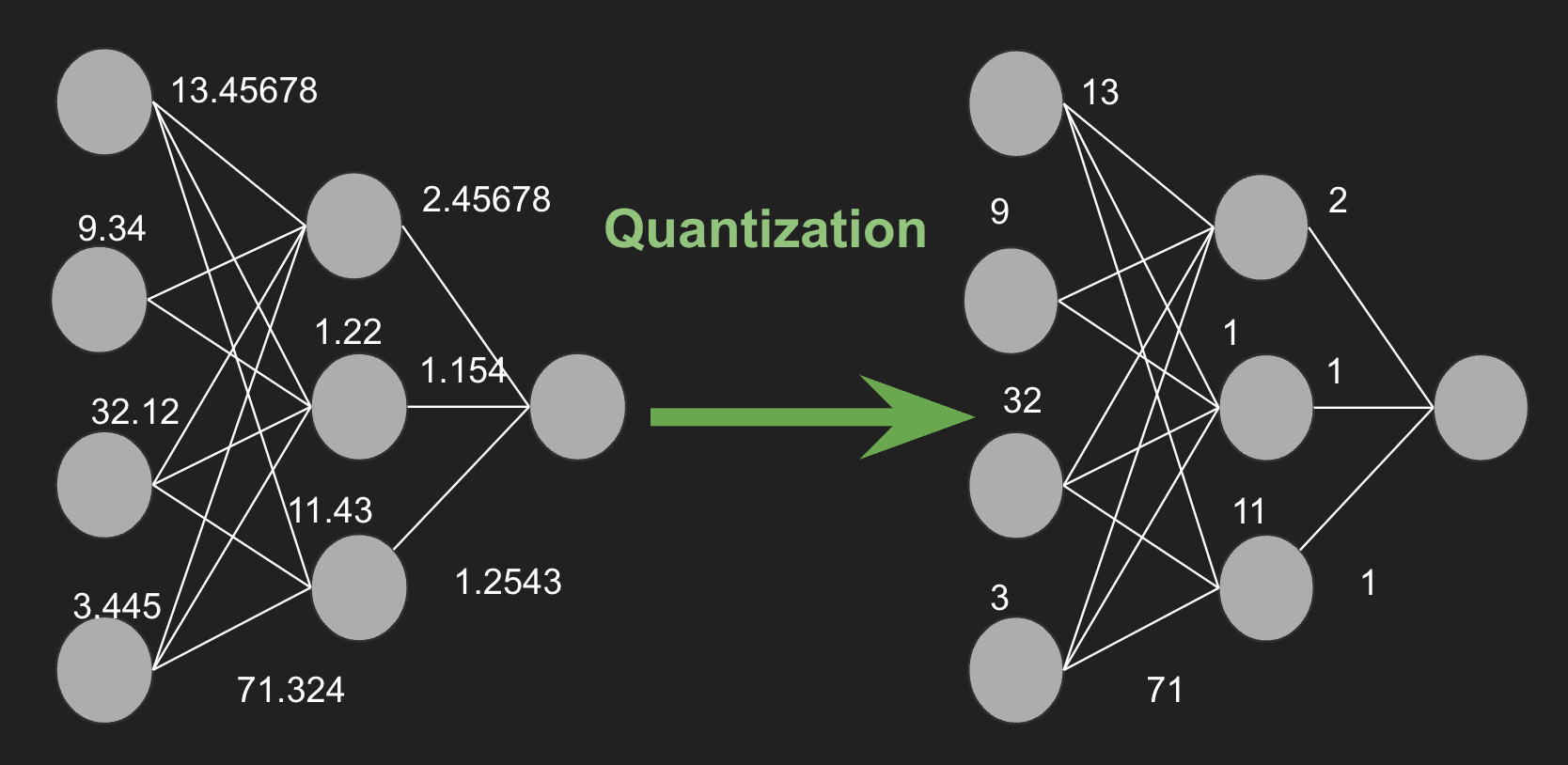
Mannequin quantization includes remodeling the parameters of a neural community, comparable to weights and activations, from high-precision (e.g., 32-bit floating level) representations to lower-precision (e.g., 8-bit integer) codecs. This discount in precision can result in substantial advantages, together with decreased reminiscence utilization, sooner inference instances, and decreased vitality consumption.
What’s Mannequin Quantization? Advantages of Mannequin Quantization
Quantization is a way that reduces the precision of mannequin parameters, thereby reducing the variety of bits wanted to retailer every parameter. As an example, contemplate a parameter with a 32-bit precision worth of seven.892345678. This worth will be approximated because the integer 8 utilizing 8-bit precision. This course of considerably reduces the mannequin dimension, enabling sooner execution on gadgets with restricted reminiscence.
Along with lowering reminiscence utilization and bettering computational effectivity, quantization also can decrease energy consumption, which is essential for battery-operated gadgets. Quantization additionally results in sooner inference by lowering the precision of mannequin parameters; quantization decreases the quantity of reminiscence required to retailer and entry these parameters.
There are numerous forms of quantization, together with uniform and non-uniform quantization, in addition to post-training quantization and quantization-aware coaching. Every methodology has its personal set of trade-offs between mannequin dimension, pace, and accuracy, making quantization a flexible and important software in deploying environment friendly AI fashions on a variety of {hardware} platforms.
Totally different Strategies for Mannequin Quantization
Mannequin quantization includes varied strategies to scale back the scale of the mannequin parameters whereas sustaining the efficiency. Listed here are some frequent strategies:
1. Put up-Coaching Quantization
Put up-training quantization (PTQ) is utilized after the mannequin has been totally skilled. PTQcan scale back a mannequin’s accuracy as a result of a few of the detailed info within the unique floating level values could be misplaced when the mannequin is compressed.
- Accuracy Loss: When PTQ compresses the mannequin, it might lose some vital particulars, which may scale back the mannequin’s accuracy.
- Balancing Act: To search out the correct stability between making the mannequin smaller and holding its accuracy excessive, cautious tuning and analysis are wanted. That is particularly vital for functions the place accuracy could be very essential.
In brief, PTQ could make the mannequin smaller however may scale back its accuracy, so it requires cautious calibration to keep up efficiency.
It is a simple and broadly used strategy, providing a number of sub-methods:
- Static Quantization: Converts the weights and activations of a mannequin to decrease precision. Calibration information is used to find out the vary of activation values, which helps in scaling them appropriately.
- Dynamic Quantization: Solely weights are quantized, whereas activations stay in greater precision throughout inference. The activations are quantized dynamically based mostly on their noticed vary throughout runtime.
2. Quantization-Conscious Coaching
Quantization-aware coaching (QAT) integrates quantization into the coaching course of itself. The mannequin is skilled with quantization simulated within the ahead go, permitting the mannequin to study to adapt to the decreased precision. This typically leads to greater accuracy in comparison with post-training quantization as a result of the mannequin can higher compensate for the quantization errors. QAT includes including additional steps throughout coaching to imitate how the mannequin will carry out when it’s compressed. This implies tweaking the mannequin to deal with this mimicry precisely. These additional steps and changes make the coaching course of extra computationally demanding. It requires extra time and computational energy. After coaching, the mannequin wants thorough testing and fine-tuning to make sure it doesn’t lose accuracy. This provides extra complexity to the general coaching course of.
3. Uniform Quantization
In uniform quantization, the worth vary is split into equally spaced intervals. That is the only type of quantization, typically utilized to each weights and activations.
4. Non-Uniform Quantization
Non-uniform quantization allocates completely different sizes to intervals, typically utilizing strategies like logarithmic or k-means clustering to find out the intervals. This strategy will be simpler for parameters with non-uniform distributions, doubtlessly preserving extra info in essential ranges.
5. Weight Sharing
Weight sharing includes clustering related weights and sharing the identical quantized worth amongst them. This system reduces the variety of distinctive weights, resulting in additional compression. Weight-sharing quantization is a way to avoid wasting vitality utilizing massive neural networks by limiting the variety of distinctive weights.
Advantages:
- Noise Resilience: The tactic is healthier at dealing with noise.
- Compressibility: The community will be made smaller with out dropping accuracy.
6. Hybrid Quantization
Hybrid quantization combines completely different quantization strategies throughout the similar mannequin. For instance, weights could also be quantized to 8-bit precision whereas activations stay at greater precision, or completely different layers would possibly use completely different ranges of precision based mostly on their sensitivity to quantization. This system reduces the scale and hastens neural networks by making use of quantization to each the weights (the mannequin’s parameters) and the activations (the intermediate outputs).
- Quantizing Each Elements: It compresses each the mannequin’s weights and the activations it calculates because it processes information. This implies each are saved and processed utilizing fewer bits, which saves reminiscence and hastens computation.
- Reminiscence and Pace Enhance: By lowering the quantity of knowledge the mannequin must deal with, hybrid quantization makes the mannequin smaller and sooner.
- Complexity: As a result of it impacts each weights and activations, it may be trickier to implement than simply quantizing one or the opposite. It wants cautious tuning to ensure the mannequin stays correct whereas being environment friendly.
7. Integer-Solely Quantization
In integer-only quantization, each weights and activations are transformed to integer format, and all computations are carried out utilizing integer arithmetic. This system is particularly helpful for {hardware} accelerators which are optimized for integer operations.
8. Per-Tensor and Per-Channel Quantization
- Per-Tensor Quantization: Applies the identical quantization scale throughout a whole tensor (e.g., all weights in a layer).
- Per-Channel Quantization: Makes use of completely different scales for various channels inside a tensor. This methodology can present higher accuracy, notably for convolutional neural networks, by permitting finer granularity in quantization.
9. Adaptive Quantization
Adaptive quantization strategies regulate the quantization parameters dynamically based mostly on the enter information distribution. These strategies can doubtlessly obtain higher accuracy by tailoring the quantization to the particular traits of the information.
Every of those strategies has its personal set of trade-offs between mannequin dimension, pace, and accuracy. Deciding on the suitable quantization methodology will depend on the particular necessities and constraints of the deployment atmosphere.
Challenges and Concerns for Mannequin Quantization
Implementing mannequin quantization in AI includes navigating a number of challenges and concerns. One of many fundamental points is the accuracy trade-off, as lowering the precision of the mannequin’s numerical information can lower its efficiency, particularly for duties requiring excessive precision. To handle this, strategies like quantization-aware coaching, hybrid approaches that blend completely different precision ranges, and iterative optimization of quantization parameters are employed to protect accuracy. Moreover, compatibility throughout varied {hardware} and software program platforms will be problematic, as not all platforms assist quantization uniformly. Addressing this requires in depth cross-platform testing, utilizing standardized frameworks like TensorFlow or PyTorch for broader compatibility, and generally growing customized options tailor-made to particular {hardware} to make sure optimum efficiency.
Actual-World Purposes
Mannequin quantization is broadly utilized in varied real-world functions the place effectivity and efficiency are essential. Listed here are just a few examples:
- Cellular Purposes: Quantized fashions are utilized in cellular apps for duties like picture recognition, speech recognition, and augmented actuality. As an example, a quantized neural community can run effectively on smartphones to acknowledge objects in images or present real-time translation of spoken language, even with restricted computational assets.
- Autonomous Automobiles: In self-driving automobiles, quantized fashions assist course of sensor information in actual time, comparable to figuring out obstacles, studying site visitors indicators, and making driving choices. The effectivity of quantized fashions permits these computations to be carried out shortly and with decrease energy consumption, which is essential for the protection and reliability of autonomous automobiles.
- Edge Units: Quantization is important for deploying AI fashions on edge gadgets like drones, IoT gadgets, and good cameras. These gadgets typically have restricted processing energy and reminiscence, so quantized fashions allow them to carry out advanced duties like surveillance, anomaly detection, and environmental monitoring effectively.
- Healthcare: In medical imaging and diagnostics, quantized fashions are used to research medical scans and detect anomalies like tumors or fractures. This helps in offering sooner and extra correct diagnoses whereas working on {hardware} with restricted computational capabilities, comparable to moveable medical gadgets.
- Voice Assistants: Digital voice assistants like Siri, Alexa, and Google Assistant use quantized fashions to course of voice instructions, perceive pure language, and supply responses. Quantization permits these fashions to run shortly and effectively on dwelling gadgets, guaranteeing clean and responsive person interactions.
- Suggestion Techniques: On-line platforms like Netflix, Amazon, and YouTube use quantized fashions to supply real-time suggestions. These fashions course of massive quantities of person information to counsel motion pictures, merchandise, or movies, and quantization helps in managing the computational load whereas delivering personalised suggestions promptly.
Quantization enhances AI fashions’ effectivity, enabling deployment in resource-constrained environments with out sacrificing efficiency considerably and bettering person expertise throughout a variety of functions.
Concluding Ideas
Quantization is a crucial approach within the area of synthetic intelligence and machine studying that addresses the problem of deploying massive fashions to edge gadgets. Quantization considerably decreases the reminiscence footprint and computational calls for of neural networks, enabling their deployment on resource-constrained gadgets and real-time functions.
A couple of of the advantages of quantization, as mentioned on this article, are decreased reminiscence utilization, sooner inference instances, and decrease energy consumption. Strategies comparable to uniform and non-uniform quantization and modern approaches.
Regardless of its benefits, quantization additionally presents challenges, notably in sustaining mannequin accuracy. Nonetheless, with latest analysis and developments in quantization strategies, researchers proceed to work on these challenges, pushing the boundaries of what’s achievable with low-precision computations. Because the deep studying group continues to innovate, quantization will play an integral position within the deployment of highly effective and environment friendly AI fashions, making refined AI capabilities accessible to a broader vary of functions and gadgets.
In conclusion, quantization is a lot greater than only a technical optimization – it performs an important position in AI developments.
We hope you loved the article!