
{kind=link}
Introduction
The problem of translating textual content from one language to a different is likely one of the cornerstones of pure language processing (NLP). Its main objective is to generate target-language textual content that faithfully conveys the meant that means of the enter materials. The target of this process is to take an English assertion as enter and output a French translation of it, or some other language of desire. Due to the significance of language translation to the realm of NLP, the unique transformer mannequin was created with that goal in thoughts.
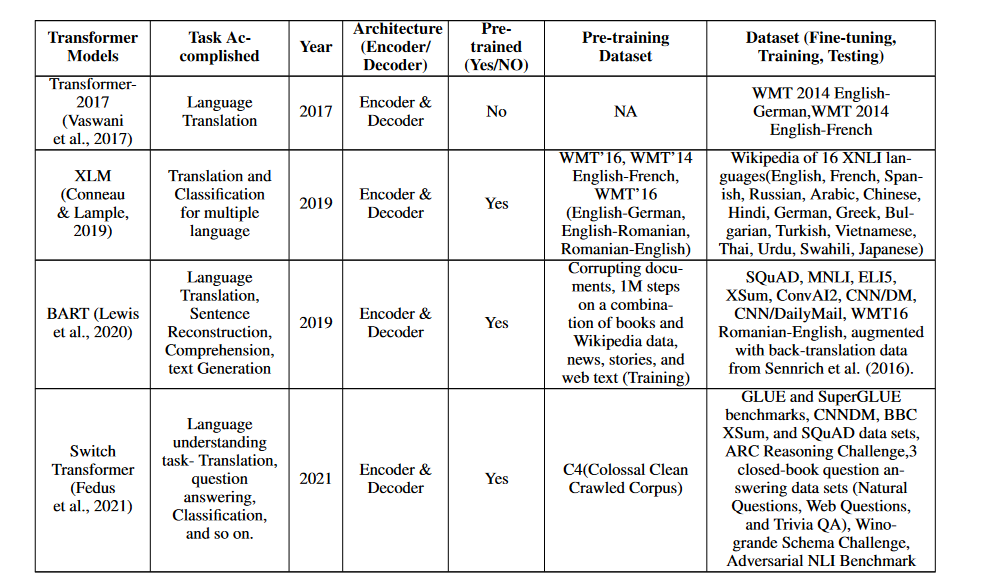
The fashions within the Desk beneath that use transformers and have carried out nicely on the Language Translation process are listed there. With a purpose to enhance the movement of knowledge and data between individuals of numerous linguistic backgrounds, these fashions play an important position. When contemplating the breadth of NLP’s potential affect in fields as diversified as enterprise, science, schooling, and social interactions, it is clear that the language translation process is an important subject of examine. The desk presents many transformer-based fashions that present promise for enhancing the state-of-the-art on this space, opening the door to novel strategies to language translation (Chowdhary & Chowdhary, 2020; Monroe; 2017; Hirschberg; & Manning; 2015).
Transformer
In 2017, Vaswani et al. (Vaswani et al., 2017) proposed the primary transformer mannequin, which has since drastically modified the panorama of pure language processing. The Vanilla transformer paradigm was developed for the specific objective of translating throughout languages. The transformer mannequin is distinct from its forerunners in that it contains an encoder and a decoder module, utilizing multi-head consideration and masked-multi-head consideration processes.
The enter language’s context is analyzed by the encoder module, whereas the decoder module generates output within the goal language by making use of the encoder’s outputs and masking multi-head consideration. The capability of the transformer mannequin to execute parallel computations, which permits the processing of phrases alongside positional info, is partly liable for its success. This permits it to handle long-range dependencies, that are important in language translation, and makes it exceptionally environment friendly at processing big portions of textual content.
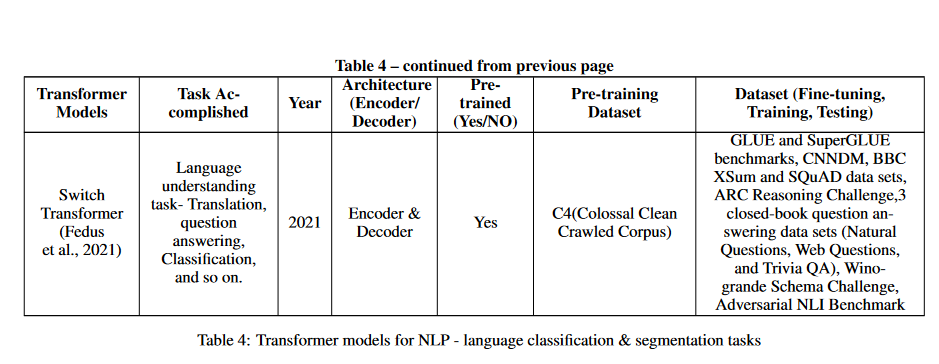
XLM
It’s a mannequin for pre-training a language that can be utilized with multiple language. Each supervised and unsupervised methods are used to construct the mannequin. The unsupervised strategy has proven to be very helpful in translating duties by way of the usage of Masked Language Modeling (MLM) and Informal Language Modeling (CLM). Nonetheless, the interpretation challenges have been additional enhanced utilizing the supervised approach (Conneau & Lample, 2019). With its capacity to execute pure language processing duties in numerous languages, the XLM mannequin has develop into a useful useful resource for cross-lingual functions. The XLM mannequin is broadly used within the space of pure language processing as a result of its effectivity in translation assignments.
BART
The pre-trained mannequin, often called BART (Bidirectional and Auto-Regressive Transformers), is basically aimed toward cleansing up corrupted textual content. It has two pre-training steps: the primary introduces noise corruption into the textual content, whereas the second focuses on recovering the unique textual content from the corrupted one. To generate, translate, and perceive textual content with exceptional accuracy, BART makes use of a transformer translation mannequin that features the encoder and decoder modules (Lewis et al., 2020). Its auto-regressive options make it nicely suited to sequentially producing output tokens, and its bidirectional strategy permits it to be taught from earlier and future tokens. These options make BART an adaptable mannequin for a variety of NLP functions.
Change Transformer
The Change Transformer mannequin is a comparatively new improvement on this planet of NLP, and it has attracted loads of curiosity as a result of its spectacular accuracy and flexibility. It has a gating mechanism and a permutation-based routing system as its two principal constructing blocks. Due to the permutation-based routing mechanism, the mannequin can develop a routing technique that decides which elements of the enter sequence to give attention to.
For the reason that mannequin can dynamically resolve which elements of the sequence to give attention to for every enter, it might deal with inputs of various lengths. The mannequin can carry out classification and segmentation due to the gating mechanism. The gating mechanism is educated to make predictions primarily based on a mixture of knowledge from the whole enter sequence. This permits the mannequin to carry out classification duties, the place it predicts a label for the whole enter sequence, in addition to segmentation duties, the place it predicts labels for every particular person a part of the enter sequence. That is defined within the following part on classification and segmentation (Fedus et al., 2021).
Classification and Segmentation
Pure language processing (NLP) depends closely on textual content classification and segmentation to automate the group and evaluation of huge quantities of textual content knowledge. Tags or labels are utilized to textual content primarily based on content material akin to emotion, subject, and objective. Functions akin to content material filtering, info retrieval, and suggestion programs can profit from this technique of classifying textual content from a number of sources. Segmenting textual content into significant chunks akin to sentences, phrases, or matters for additional processing is what textual content segmentation is all about. Essential pure language processing (NLP) functions rely closely on this course of, and it has been extensively researched and written about (Chowdhary & Chowdhary, 2020; Kuhn, 2014; Hu et al., 2016).
Charformer
This transformer-based mannequin introduce gradient-based subword tokenization (GBST) which is a light-weight technique for studying latent subwords instantly from byte-level characters. The mannequin, accessible in English and a number of other different languages, has proven distinctive efficiency in language comprehension duties, together with classification of lengthy textual content paperwork (Tay et al., 2022).
Change Transformer
Within the subject of pure language processing, pre-trained fashions akin to BERT and GPT, that are educated on massive datasets, have develop into more and more fashionable. Nonetheless, the fee and environmental burden of creating these fashions has raised eyebrows. The Change Transformer was developed as an answer to those issues; it permits for a extra complete mannequin with out considerably rising the computational value. A mannequin with trillions of parameters is achieved by changing the feed-forward neural community (FFN) with a change layer containing a number of FFNs.
The computational value of the Change transformer is in keeping with that of earlier fashions, whilst the dimensions of the mannequin will increase. In reality, the Change transformer has been examined on 11 completely different duties, with spectacular outcomes throughout the board (Fedus et al., 2021). These embrace translation, query answering, classification, and summarization.
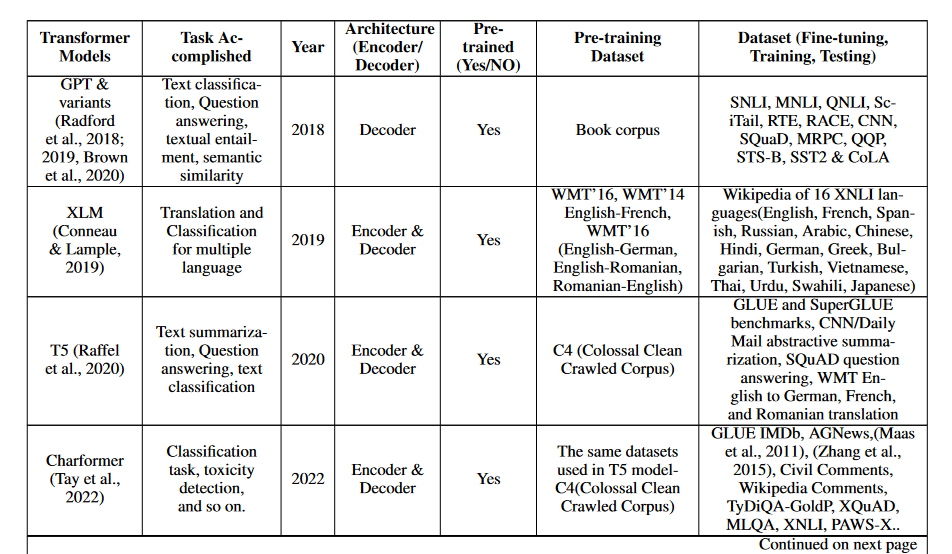
GPT & Variants
These fashions can be utilized for quite a lot of pure language processing (NLP) duties, akin to categorization, segmentation, query answering, and translation. Allow us to discuss GPT and its variants.
By focusing solely on the decoder block of transformers, Generative Pre-Educated Transformer (GPT) fashions considerably advance the usage of transformers in NLP. By combining unsupervised pre-training with supervised fine-tuning methods, GPT takes a semi-supervised strategy to language understanding (Radford et al., 2018).
Following the success of the GPT mannequin in 2019, a pre-trained transformer-based mannequin known as GPT-2 with 1.5 billion parameters was launched. This mannequin considerably improved the pre-trained model of transformers (Radford et al., 2019). Within the following years (2020), probably the most superior pre-trained model of GPT, often called GPT-3, was made accessible. It had 175 billion parameters. That is ten occasions the dimensions of any earlier non-sparse language mannequin. In contrast to pre-trained fashions akin to BERT (Brown et al., 2020), GPT-3 reveals good efficiency on quite a lot of duties with out the necessity for gradient updates or fine-tuning.
T5
To spice up its efficiency in downstream pure language processing (NLP) duties, the T5 transformer mannequin—brief for “Textual content-to-Textual content Switch Transformer”—launched a dataset known as “Colossal Clear Crawled Corpus” (C4). T5 is a general-purpose mannequin that may be educated to carry out many pure language processing (NLP) duties utilizing the identical configuration. Following pre-training, the mannequin might be custom-made for quite a lot of duties and reaches a degree of efficiency that’s equal to that of assorted task-specific fashions (Raffel et al., 2020).
Conclusion
Transformes can be utilized to course of language translation. They excel in modeling sequential knowledge, akin to pure language, and use a self-attention mechanism to convey info throughout enter sequences. This makes them particularly efficient at modeling sequential knowledge. Hugging Face, TensorFlow, PyTorch, and Huawei are simply among the examples of libraries and fashions which might be accessible for utilizing transformers for the aim of language translation. These libraries embrace pre-trained transformer fashions for quite a lot of language translation functions, along with instruments for fine-tuning and assessing the efficiency of fashions.
Reference
A Survey of Transformers: https://arxiv.org/abs/2106.04554