{kind=link}
Introduction
After the immense success of the Mistral-7b mannequin, the workforce launched a brand new mannequin named Mixtral, a pre-trained ensemble mannequin of eight Mistral-7bs. That is also called Mixtral MoE (Combination Of Specialists). It immediately grew to become one of the best open-access mannequin, topping proprietary fashions like GPT-3.5, Claude-2.1, and Gemini Professional. This mannequin confirmed an environment friendly ensemble of small pre-trained fashions could be an efficient various to massive dense fashions.
However can we run it on shopper {hardware}? Regardless of not being a dense mannequin, operating fashions of this dimension remains to be costly (Observe: Mixtral 8x7b has 47 billion parameters.) And it’s nearly unattainable to run this mannequin on cheaper shopper {hardware} with conventional strategies. However with environment friendly quantization and MoE offloading technique, we will run a Mixtral MoE on shopper {hardware}. We are going to discover methods to run a Mixtral 8x7B on a free Colab T4 runtime.
Studying Aims
- Discover the idea of Combination of Specialists.
- Study in regards to the quantization and MoE offloading technique.
- Discover Mixtral MoE on a free Tesla T4 Colab GPU runtime.
This text was revealed as part of the Information Science Blogathon.
Combination Of Specialists
The time period has been on everybody’s lips for the reason that Mixtral 8x7b’s launch. So, what’s an MoE?
The idea of MoE is comparatively outdated. It first appeared within the paper Adaptive Combination of Native Specialists in 1991. The idea is to ensemble a number of networks referred to as specialists, every dealing with a subset of coaching circumstances. It’s primarily based on the divide and conquer algorithm. The place an issue is split into smaller sub-tasks, and specialists take care of sub-tasks primarily based on their experience. Think about a panel of specialists fixing an enormous drawback, the place every professional solely works on the issue they’ve experience in.
Historically, the specialists are a bunch of neural networks, however in observe, any mannequin can be utilized, like a regression mannequin, classification mannequin, and even different MoEs. However right here, we’re involved with LLMs. So we’ll discuss transformers.
Within the context of transformers, MoE primarily consists of two components. A sparse MoE layer and a gating community or router. So, what’s a sparse MoE and Router?
Sparse MoE
In a dense mannequin, all of the weights are used for all of the inputs, whereas in a sparse mannequin, solely a subset of the unique weights are used. In transformers, the dense feed-forward community is changed by a sparse MoE layer. It might comprise a number of specialists, like 8 for Mixtral. Every professional makes a speciality of a specific a part of a sentence. For instance, after coaching an MoE mannequin over a dataset, we might have specialists in counting and numbers, verbs, conjunctions, articles, and so on.
Gating Mannequin
So, how does the mannequin determine which specialists to choose for an enter token? The MoE structure makes use of a unique neural community referred to as Router for this. A Router or Gating mannequin is a neural community, typically smaller than an professional mannequin, that routes tokens to acceptable specialists. This mannequin is usually educated alongside specialists to be taught which specialists to belief for a given sort of token.
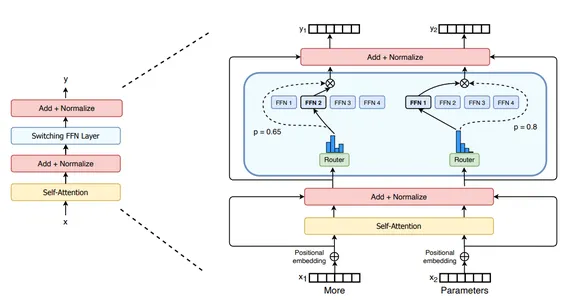
Contemplate the next picture of a swap transformer. The FFN layer is changed with an MoE layer with 4 specialists. The tokens “Extra” and “Parameters” are routed by a gating community to acceptable specialists.
Execs and Cons
The Combination of Specialists has its benefits over the dense fashions.
- Environment friendly pre-training: One of many vital advantages of MoEs over dense fashions is that it’s a lot simpler to pre-train MoEs with far much less computing than their dense counterparts. The MoEs obtain the identical high quality of a dense mannequin sooner throughout pre-training.
- Inference High quality: As a result of a number of professional fashions are concerned throughout inferencing, the standard of it will increase drastically. On account of sparsity, inferencing is quicker than the equally massive dense mannequin.
There are additionally sure shortcomings of MoEs.
- Positive-tuning: One of many bottlenecks for the widespread adoption of MoEs has been the problem in fine-tuning the fashions. There have been lively efforts to make fine-tuning simpler for MoEs.
- Excessive VRAM utilization: The MoEs require excessive VRAM to be run effectively, as all of the specialists have to be loaded into the GPU. This makes it inaccessible from consumer-grade {hardware}.
So, the query is, how can we run MoEs like Mixtral on cheaper {hardware}? You have to be interested by quantization. Sure, the quantization approach might help cut back the scale of LLMs, however an MoE mannequin with 47B parameters for a 16GB VRAM remains to be an overkill. However the good factor is a few methods could be leveraged to deduce from Mixtral MoE on a T4 GPU.
Parameter Offloading
The authors of this paper got here up with a way to run a quantized Mixtral on shopper {hardware} utilizing parameter offloading. The method includes a mixture of MoE quantization, LRU caching, and speculative professional loading to deduce from Mixtral. So, how can we do it?
Quantization
Step one is to quantize the Mixtral MoE. Quantization is about decreasing the precision of floating level numbers of the mannequin weight. Greater precision in floats signifies the next capability to carry and course of info. A 16-bit mannequin will have the ability to carry out higher than an 8-bit mannequin. Nevertheless, the next bit additionally means bigger fashions. Quantization compresses the scale of the mannequin with a slight trade-off in efficiency.
The authors noticed a greater quality-size trade-off whereas quantizing specialists to decrease bitrates. The specialists have been quantized to 2-bit, whereas the non-expert layers have been quantized to 4-bits. This lowered the complete 16-bit Mixtral mannequin of dimension ~86GB to ~17.54GB with a 5% trade-off on the MMLU benchmark (70.51 to 65.58). This, as you possibly can see, is a major enchancment.
Right here’s a chart for different quantization mixture

LRU Caching
The following step is to load the specialists. As we realized earlier, the MoE allots every token to an professional, however loading all of the specialists to a T4 VRAM is unattainable. To avoid this, the authors proposed mannequin caching. The algorithm hundreds the least just lately used professional to the GPU. This professional is available for enter tokens. Thus, inferencing will likely be quick if a token is routed to this professional. But when it misses, a unique professional is activated. On this method, there aren’t any sacrifices in mannequin performances whereas nonetheless attaining sooner inferencing. The variety of specialists(ok) within the cache is determined by the scale of the GPU. If ok is larger than the variety of lively specialists, the cache will save specialists from earlier tokens.
Skilled Loading
LRU caching of fashions hurries up inferencing. However it’s nonetheless not enough. More often than not throughout inferencing is spent on loading the following professional. For an MoE, it’s troublesome to reliably predict which specialists to load, because the specialists are chosen simply in time for computation. Nevertheless, it was noticed that it’s potential to make an informed guess of the long run professional by making use of the following layer’s gating perform to the hidden states of the earlier layer. If the guess is appropriate, we get a sooner inference. If not, the professional is loaded as normal.
The variety of specialists to be cached is 2 for 12GB GPU and 4 for 16GB GPU. As soon as the specialists are loaded for a layer, 1-2 specialists are fetched with speculative professional loading. If the speculatively loaded professional is used for consecutive tokens, it replaces the least just lately used professional within the cache. To make it extra environment friendly whereas loading specialists to the GPU cache, the system offloads the present LRU professional again to RAM.
Mixtral in Colab
Now that we all know the methods. Let’s see it in observe. Open a Colab pocket book with T4 GPU runtime.
Repair Triton and set up the required dependencies.
import numpy
from IPython.show import clear_output
# repair triton in colab
!export LC_ALL="en_US.UTF-8"
!export LD_LIBRARY_PATH="/usr/lib64-nvidia"
!export LIBRARY_PATH="/usr/native/cuda/lib64/stubs"
!ldconfig /usr/lib64-nvidia
!git clone https://github.com/dvmazur/mixtral-offloading.git --quiet
!cd mixtral-offloading && pip set up -q -r necessities.txt
!huggingface-cli obtain lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo
--quiet --local-dir
Mixtral-8x7B-Instruct-v0.1-offloading-demo
clear_output()We’re downloading a taste Mixtral Instruct mannequin, which has already been quantized. This can take some time.
Now, import all of the dependencies.
import sys
sys.path.append("mixtral-offloading")
import torch
from torch.nn import purposeful as F
from hqq.core.quantize import BaseQuantizeConfig
from huggingface_hub import snapshot_download
from IPython.show import clear_output
from tqdm.auto import trange
from transformers import AutoConfig, AutoTokenizer
from transformers.utils import logging as hf_logging
from src.build_model import OffloadConfig, QuantConfig, build_modelWe are going to outline the Offload Config, Consideration layer quantization config, and Skilled or FFN layer config and initialize the mannequin.
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1"
quantized_model_name = "lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo"
state_path = "Mixtral-8x7B-Instruct-v0.1-offloading-demo"
config = AutoConfig.from_pretrained(quantized_model_name)
system = torch.system("cuda:0")
##### Change this to five if in case you have solely 12 GB of GPU VRAM #####
offload_per_layer = 4
# offload_per_layer = 5
###############################################################
num_experts = config.num_local_experts
offload_config = OffloadConfig(
main_size=config.num_hidden_layers * (num_experts - offload_per_layer),
offload_size=config.num_hidden_layers * offload_per_layer,
buffer_size=4,
offload_per_layer=offload_per_layer,
)
attn_config = BaseQuantizeConfig(
nbits=4,
group_size=64,
quant_zero=True,
quant_scale=True,
)
attn_config["scale_quant_params"]["group_size"] = 256
ffn_config = BaseQuantizeConfig(
nbits=2,
group_size=16,
quant_zero=True,
quant_scale=True,
)
quant_config = QuantConfig(ffn_config=ffn_config, attn_config=attn_config)
mannequin = build_model(
system=system,
quant_config=quant_config,
offload_config=offload_config,
state_path=state_path,
)The mannequin is loaded, and now we will infer from it.
from transformers import TextStreamer
tokenizer = AutoTokenizer.from_pretrained(model_name)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
past_key_values = None
sequence = None
seq_len = 0
print("Consumer: ", finish="")
user_input = enter()
print("n")
user_entry = dict(function="consumer", content material=user_input)
input_ids = tokenizer.apply_chat_template([user_entry], return_tensors="pt").to(system)
if past_key_values is None:
attention_mask = torch.ones_like(input_ids)
else:
seq_len = input_ids.dimension(1) + past_key_values[0][0][0].dimension(1)
attention_mask = torch.ones([1, seq_len - 1], dtype=torch.int, system=system)
print("Mixtral: ", finish="")
consequence = mannequin.generate(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
streamer=streamer,
do_sample=True,
temperature=0.9,
top_p=0.9,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id,
return_dict_in_generate=True,
output_hidden_states=True,
)
print("n")
sequence = consequence["sequences"]
past_key_values = consequence["past_key_values"]This can ask for an enter string. As soon as the enter is entered, it’ll generate a response. Beneath is a question I requested the mannequin to reply.

The era velocity is sluggish, about 2-3 tokens per second. The mannequin is kind of heavy and hogs up nearly all of the sources. This can be a useful resource chart for Mixtral with off-loading on T4 GPU.

I consider with a 2xT4 occasion, the inference will likely be significantly better. Nonetheless, cramming up an enormous mannequin on a 16GB VRAM and making it work is an enormous feat.
Conclusion
Mixtral MoE is likely one of the hottest matters proper now for each good cause. It grew to become the primary open-access mannequin to dethrone GPT-3.5 on all benchmarks. However Mixtral with 47B parameter remains to be not accessible to indie builders. On this article, we deep dive into the strategies and methods to run a Mixtral on a free T4 Colab runtime.
So, listed below are the important thing takeaways from the article
- The Combination of Specialists is a machine studying technique the place a number of neural networks, every with its experience ensemble collectively to resolve a predictive drawback.
- In transformers, the dense feed-forward community is changed by a sparse MoE layer consisting of a number of feed-forward networks.
- The MoE system has a gating community or router for routing tokens to acceptable specialists.
- Mixtral is an open-access combination of professional fashions from MistralAI. It’s an ensemble of eight 7B fashions. It has a complete of 46.7B parameters.
- With MoE quantization, LRU caching, and speculative professional loading, it’s potential to deduce from Mixtral 8x7b.
References:
Steadily Requested Query
A. The Combination of Specialists is a machine studying technique the place a number of neural networks are ensembled to resolve a predictive modeling drawback when it comes to sub-tasks.
A. Mixtral 8x7b is a sparse Combination of Skilled fashions with state-of-the-art textual content era efficiency amongst open-access fashions.
A. Mistral 7b is a dense mannequin with 7 billion parameters, whereas Mixtral 8x7b is a sparse Combination of Skilled fashions with 46.7 billion parameters.
A. Mixtral 8x7b is an open-access mannequin beneath the Apache 2.0 license, that means it may be used for any industrial exercise. So sure, Mixtral 8x7b is an open-source mannequin.
A. With sufficient GPU, Mixtral 8x7b could be run via instruments like Ollama, LM Studio, and so on. For restricted GPU, it may be run with LRU caching, quantization, and parameter offloading
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.