
{kind=link}
Introduction
GPUs are described as parallel processors for his or her means to execute work in parallel. Duties are divided into smaller sub-tasks, executed concurrently by a number of processing models, and mixed to provide the ultimate end result. These processing models (threads, warps, thread blocks, cores, multiprocessors) share sources, akin to reminiscence, facilitating collaboration between them and enhancing general GPU effectivity.
One unit particularly, warps, are a cornerstone of parallel processing. By grouping threads collectively right into a single execution unit, warps permit for the simplification of thread administration, the sharing of information and sources amongst threads, in addition to the masking of reminiscence latency with efficient scheduling.

On this article, we are going to define how warps are helpful for optimizing the efficiency of GPU-accelerated purposes. By constructing an instinct round warps, builders can obtain important beneficial properties in computational pace and effectivity.
Warps Unraveled
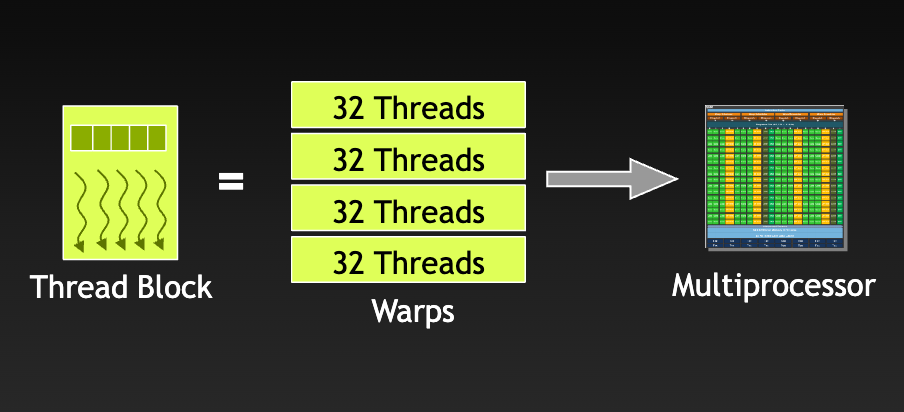
When a Streaming Multiprocessor (SM) is assigned thread blocks for execution, it subdivides the threads into warps. Trendy GPU architectures sometimes have a warp measurement of 32 threads.
The variety of warps in a thread block relies on the thread block measurement configured by the CUDA programmer. For instance, if the thread block measurement is 96 threads and the warp measurement is 32 threads, the variety of warps per thread block can be: 96 threads/ 32 threads per warp = 3 warps per thread block.
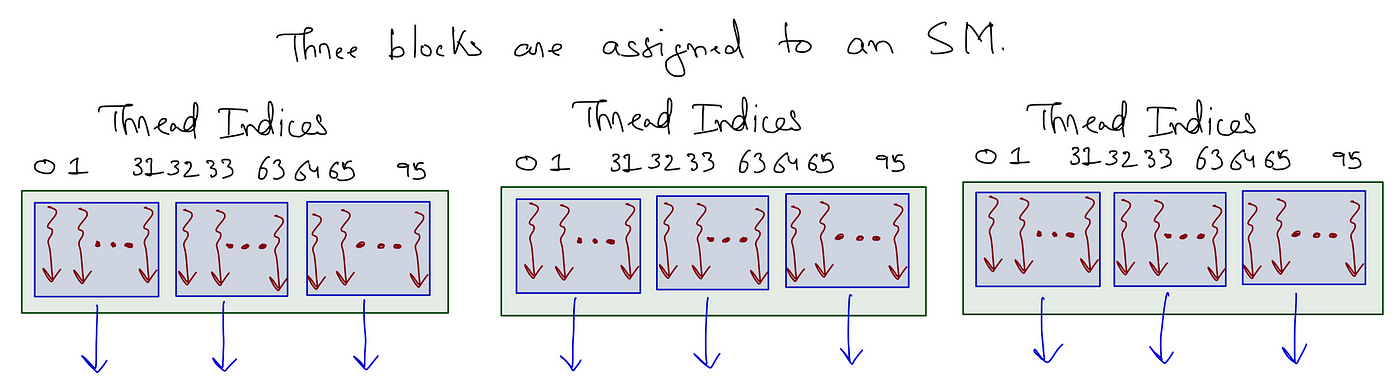
Word how, within the determine, the threads are listed, beginning at 0 and persevering with between the warps within the thread block. The primary warp is fabricated from the primary 32 threads (0-31), the next warp has the following 32 threads (32-63), and so forth.
Now that we have outlined warps, let’s take a step again and have a look at Flynn’s Taxonomy, specializing in how this categorization scheme applies to GPUs and warp-level thread administration.
GPUs: SIMD or SIMT?
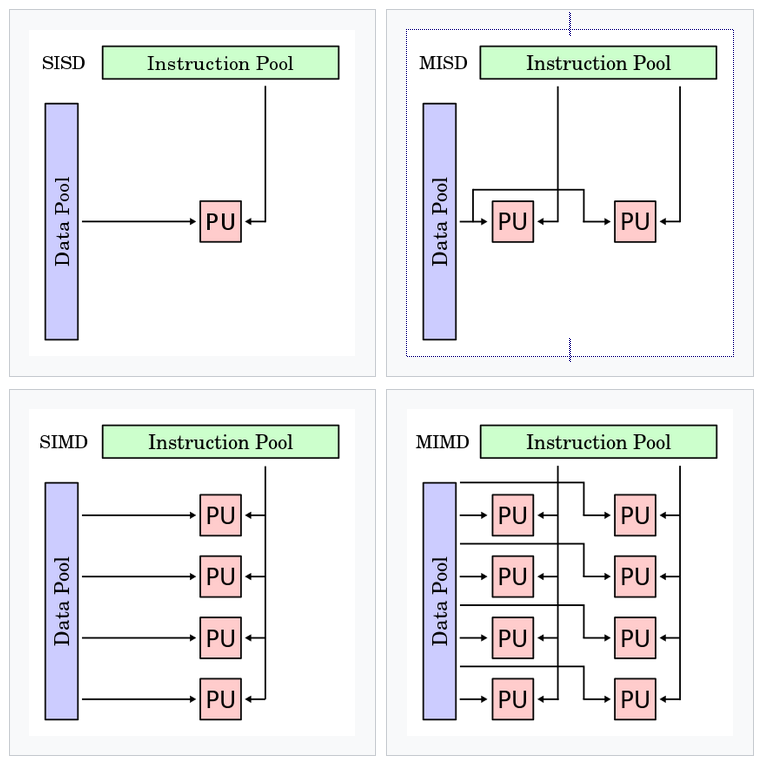
Flynn’s Taxonomy is a classification system based mostly on a pc structure’s variety of directions and information streams. GPUs are sometimes described as Single Instruction A number of Information (SIMD), that means they concurrently carry out the identical operation on a number of information operands. Single Instruction A number of Thread (SIMT), a time period coined by NVIDIA, extends upon Flynn’s Taxonomy to higher describe the thread-level parallelism NVIDIA GPUs exhibit. In an SIMT structure, a number of threads problem the identical directions to information. The mixed effort of the CUDA compiler and GPU permit for threads of a warp to synchronize and execute an identical directions in unison as incessantly as potential, optimizing efficiency.
Whereas each SIMD and SIMT exploit data-level parallelism, they’re differentiated of their strategy. SIMD excels at uniform information processing, whereas SIMT presents elevated flexibility on account of its dynamic thread administration and conditional execution.
Warp Scheduling Hides Latency
Within the context of warps, latency is the variety of clock cycles for a warp to complete executing an instruction and change into out there to course of the following one.
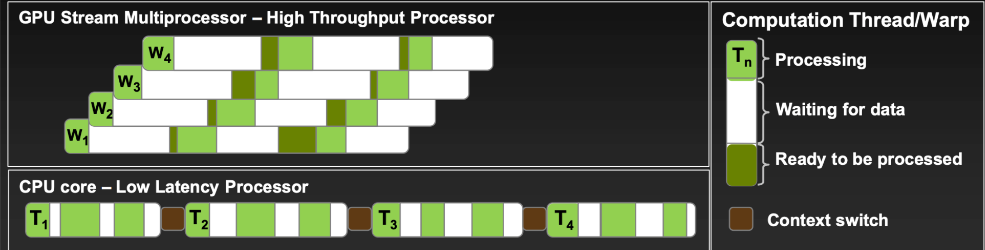
Most utilization is attained when all warp schedulers all the time have directions to problem at each clock cycle. Thus, the variety of resident warps, warps which can be being executed on the SM at a given second, instantly have an effect on utilization. In different phrases, there must be warps for warp schedulers to problem directions to. A number of resident warps allow the SM to modify between them, hiding latency and maximizing throughput.
Program Counters
Program counters increment every instruction cycle to retrieve this system sequence from reminiscence, guiding the stream of this system’s execution. Notably, whereas threads in a warp share a typical beginning program handle, they keep separate program counters, permitting for autonomous execution and branching of the person threads.
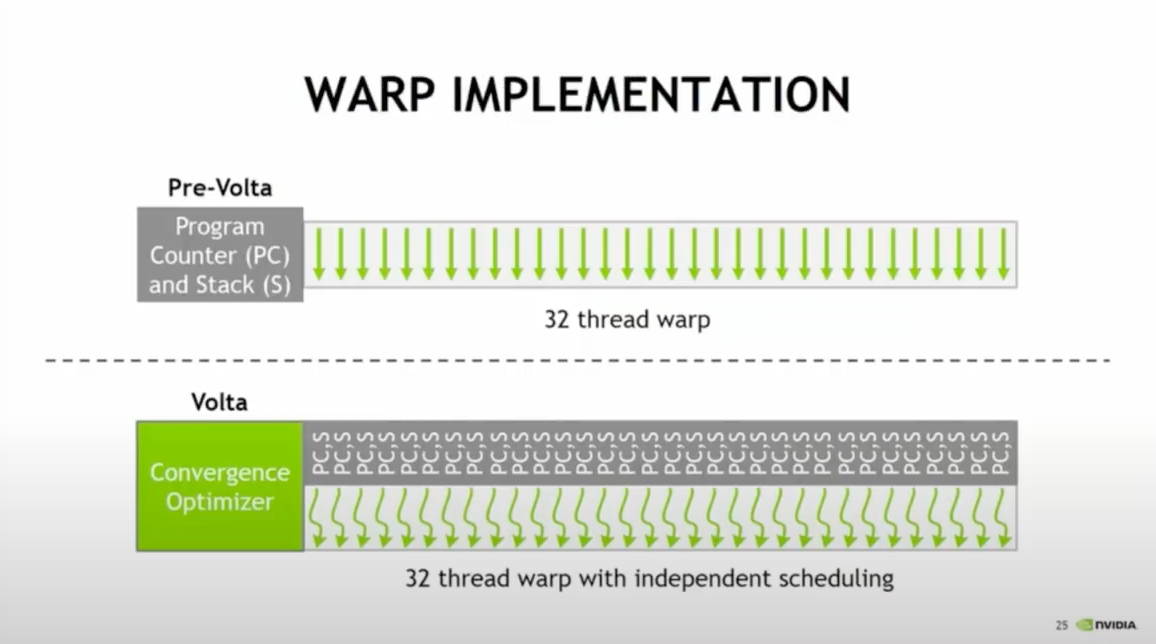
Branching
Separate program counters permit for branching, an if-then-else programming construction, the place directions are processed provided that threads are energetic. Since optimum efficiency is attained when a warp’s 32 threads converge on one instruction, it’s suggested for programmers to write down code that minimizes situations the place threads inside a warp take a divergent path.
Conclusion : Tying Up Unfastened Threads
Warps play an necessary function in GPU programming. This 32-thread unit leverages SIMT to extend the effectivity of parallel processing. Efficient warp scheduling hides latency and maximizes throughput, permitting for the streamlined execution of complicated workloads. Moreover, program counters and branching facilitate versatile thread administration. Regardless of this flexibility, programmers are suggested to keep away from lengthy sequences of diverged execution for threads in the identical warp.
References
Utilizing CUDA Warp-Stage Primitives | NVIDIA Technical Weblog
NVIDIA GPUs execute teams of threads often known as warps in SIMT (Single Instruction, A number of Thread) vogue. Many CUDA packages obtain excessive efficiency by making the most of warp execution.

CUDA C++ Programming Information
The programming information to the CUDA mannequin and interface.