{kind=link}

Introduction
Depth Notion is a means of understanding 3D objects and judging how far these objects are. It helps in duties like navigation, object manipulation, and scene understanding. Regardless of its significance, estimating depth from a single picture, often called monocular depth estimation, is a difficult drawback for Synthetic Intelligence (AI) to unravel.
Nevertheless, developments in machine studying, notably deep studying or AI, have considerably improved the accuracy and reliability of monocular depth estimation. Convolutional Neural Networks (CNNs) and different deep studying architectures have proven nice promise in studying to foretell depth from 2D photos by leveraging giant datasets and highly effective computational assets. These fashions are skilled on numerous photos with recognized depth info, permitting them to generalize to new, unseen scenes.
These methods require numerous and in depth coaching information to be efficient throughout varied eventualities. Nevertheless, gathering such information takes numerous work. Sensors that present detailed depth info, like structured gentle or time-of-flight sensors, have limitations in vary and situations. Laser scanners are costly and solely provide sparse depth measurements when transferring objects are to be captured. Alternatively, stereo cameras present promise, however amassing sufficient stereo photos in several environments remains to be a problem.
In consequence, researchers are exploring various approaches, comparable to utilizing artificial information, augmenting current datasets, and using methods like structure-from-motion to create complete coaching units.
Construction-from-motion (SfM) strategies have been used to create coaching information, however they should seize transferring objects, and there are gaps as a result of limitations of multi-view matching. At present, a couple of dataset is required in an effort to prepare a mannequin that may deal with the range present in real-world photos. We now have a number of datasets, every helpful ultimately however individually biased and incomplete. This highlights the necessity for extra complete datasets to enhance monocular depth estimation fashions.
Depth Something mannequin is predicated on the DPT structure and has been skilled on greater than 62 million photos. The spine of the DPT mannequin leverages a Imaginative and prescient Transformer(ViT) instead of CNN for dense prediction duties, that means predicting issues per pixel.
DPT (Dense Prediction Transformer) is a novel structure that estimates depth from a single picture. It makes use of an encoder-decoder method, the place the encoder is predicated on the Imaginative and prescient Transformer (ViT), a major development in pc imaginative and prescient. The encoder, additionally referred to as the community’s spine, is pre-trained on a big corpus comparable to ImageNet.
The decoder aggregates options from the encoder and converts them to the ultimate dense predictions.
This is the way it works: ViT uniquely processes the picture, sustaining the identical degree of element all through and having a large discipline of view. This helps DPT make detailed and globally constant predictions. As an alternative of conventional strategies that lose some element by means of downsampling, DPT retains the picture high quality excessive in any respect levels.
When monocular depth estimation and semantic segmentation had been examined, DPT outperformed the main convolutional networks by over 28%. It was particularly efficient on giant datasets and even set new efficiency information on smaller ones like NYUv2 and KITTI. DPT excelled in semantic segmentation duties, reaching high outcomes on difficult datasets like ADE20K and Pascal Context.
The important thing to DPT’s success is its potential to provide finer and extra coherent predictions than conventional convolutional networks, making it a major development in pc imaginative and prescient.
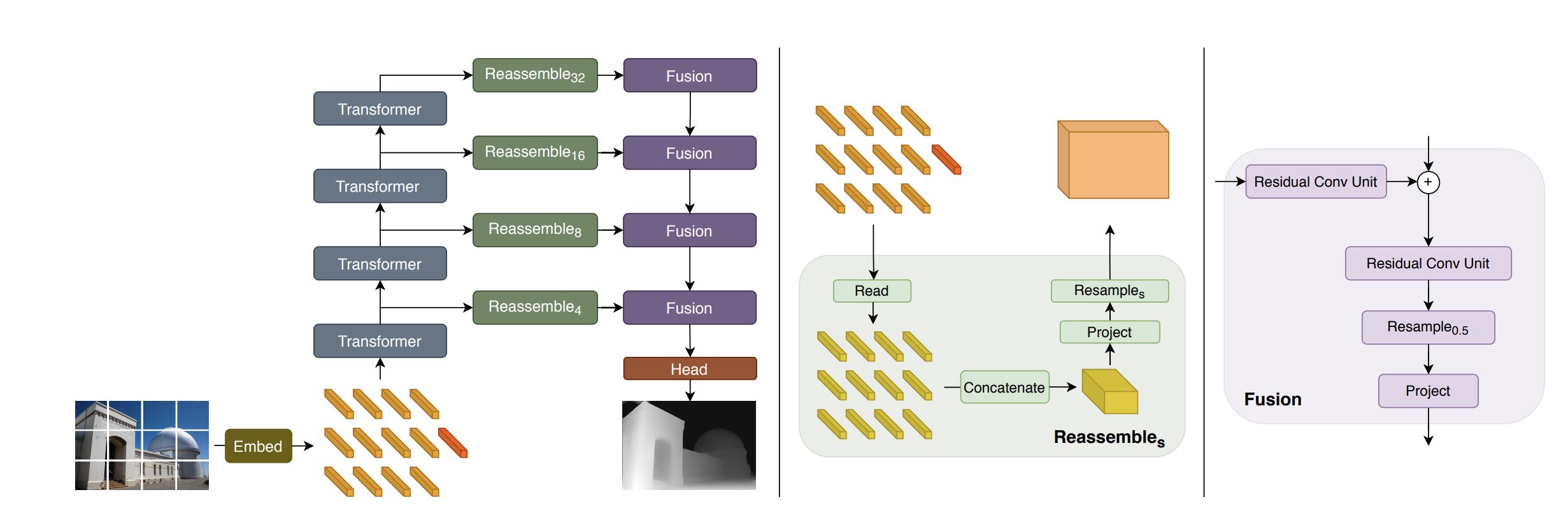
DPT Structure
- Tokenization: The enter picture is transformed into tokens both by:
- Extracting non-overlapping patches and projecting them linearly (DPT-Base and DPT-Massive), or
- Utilizing a ResNet-50 characteristic extractor (DPT-Hybrid).
- Embedding: The picture tokens are augmented with positional embeddings and a readout token.
- Transformer Levels: The tokens cross by means of a number of transformer levels.
- Reassembly: Tokens from completely different levels are reassembled into image-like representations at a number of resolutions.
- Fusion and Upsampling: Fusion modules progressively mix and upsample these representations to create a fine-grained prediction. Fusion blocks use residual convolutional models to merge options and improve the decision.
Carry this challenge to life
To strive the DPT mannequin, undergo the under steps:-
- Set the surroundings
!pip set up -q git+https://github.com/huggingface/transformers.git- Outline the characteristic extractor and the mannequin
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large")
mannequin = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")- Get the picture
from PIL import Picture
import requests
url="http://photos.cocodataset.org/val2017/000000039769.jpg"
picture = Picture.open(requests.get(url, stream=True).uncooked)
picture
- Put together the picture
pixel_values = feature_extractor(picture, return_tensors="pt").pixel_values
pixel_valuestensor([[[[ 0.1137, 0.1373, 0.1529, ..., -0.1686, -0.2078, -0.1843],
[ 0.0980, 0.1294, 0.2000, ..., -0.2078, -0.1843, -0.2000],
[ 0.1216, 0.1529, 0.1765, ..., -0.1922, -0.1922, -0.2157],
...,
[ 0.8275, 0.8353, 0.7882, ..., 0.5059, 0.4510, 0.4196],
[ 0.8039, 0.8196, 0.7490, ..., 0.1843, 0.0745, -0.0353],
[ 0.8667, 0.8196, 0.7098, ..., -0.2471, -0.3333, -0.3804]],
[[-0.8039, -0.8196, -0.8353, ..., -0.9137, -0.8902, -0.9059],
[-0.8039, -0.8039, -0.7804, ..., -0.8824, -0.8980, -0.8824],
[-0.7804, -0.7804, -0.7882, ..., -0.8588, -0.8824, -0.8824],
...,
[-0.2706, -0.2549, -0.2941, ..., -0.5216, -0.5608, -0.5608],
[-0.3176, -0.2863, -0.3333, ..., -0.7020, -0.7490, -0.8275],
[-0.2235, -0.2784, -0.3882, ..., -0.8431, -0.8667, -0.8667]],
[[-0.5373, -0.4824, -0.4510, ..., -0.6941, -0.6941, -0.7176],
[-0.5922, -0.5686, -0.4510, ..., -0.6941, -0.7098, -0.7333],
[-0.5922, -0.5373, -0.5373, ..., -0.6941, -0.7176, -0.7569],
...,
[ 0.5451, 0.5373, 0.4745, ..., 0.2392, 0.2000, 0.1843],
[ 0.6314, 0.5843, 0.5294, ..., -0.1765, -0.2941, -0.3882],
[ 0.4980, 0.5922, 0.5608, ..., -0.6392, -0.6941, -0.6549]]]])import torch
with torch.no_grad():
outputs = mannequin(pixel_values)
predicted_depth = outputs.predicted_depth- Visualize the Picture
import numpy as np
# interpolate to authentic measurement
prediction = torch.nn.useful.interpolate(
predicted_depth.unsqueeze(1),
measurement=picture.measurement[::-1],
mode="bicubic",
align_corners=False,
).squeeze()
output = prediction.cpu().numpy()
formatted = (output * 255 / np.max(output)).astype('uint8')
depth = Picture.fromarray(formatted)
depth
Depth Something V2: A Look Again on the MIDAS Paper
Depth Something V2 has achieved exceptional success in in-depth estimation, surpassing many different fashions and dealing with difficult photos with spectacular accuracy. To completely perceive the capabilities of Depth Something V2, it’s important to revisit the foundational ideas launched within the MIDAS paper from 2020.
MIDAS (Monocular Depth Estimation by way of a Multi-Scale Community) superior the sector by coaching a neural community to estimate depth from single photos. It achieved this by leveraging numerous datasets, every contributing distinctive forms of depth info. For instance:
- KITTI Dataset: Targeted on autonomous driving, this dataset gives photos captured in out of doors environments utilizing stereo cameras. These cameras are positioned at a hard and fast distance aside, permitting the extraction of depth info by means of post-processing methods.
- NYU Depth V2 Dataset: Makes a speciality of indoor scenes, capturing depth information by means of stereo imaging methods in varied family and workplace settings.
The MIDAS community was skilled on these datasets to reinforce its generalization potential throughout completely different scenes and situations. By combining varied sources of depth information, MIDAS realized to foretell depth from a single picture extra precisely.
MiDaS
Monocular depth estimation, which determines the depth of objects from a single picture, advantages from coaching on giant and numerous datasets. Nevertheless, amassing correct depth info for a lot of completely different environments is an not possible activity, main to numerous datasets with distinctive options and biases. To deal with this, we developed instruments to mix a number of datasets throughout coaching, even when their depth annotations differ.
This paper launched a novel loss perform that we mentioned later within the tutorial. This progressive loss perform handles inconsistencies between datasets, comparable to unknown and ranging scales and baselines. These losses enable coaching with information from completely different sensors, together with stereo cameras (even with unknown calibration), laser scanners, and structured gentle sensors.
The in depth experiments show {that a} mannequin skilled on a various set of photos with the correct coaching process achieves state-of-the-art outcomes throughout varied environments. The paper additionally focussed on zero-shot cross-dataset switch to show this, the place the mannequin is skilled on particular datasets and examined on unseen ones. This technique gives a extra correct measure of “actual world” efficiency than coaching and testing on subsets of a single, biased dataset.
Developments in Depth Something V2
Constructing on the rules of MIDAS, Depth Something has launched a number of key enhancements:
- Enhanced Mannequin Structure: Depth Something V2 makes use of a extra superior neural community structure than MIDAS, incorporating latest developments in deep studying to enhance depth prediction accuracy and deal with extra advanced scenes.
- Excessive-Decision Processing: Not like earlier fashions that struggled with high-resolution inputs, Depth Something V2 effectively processes detailed photos, enabling it to seize fine-grained depth info and deal with intricate visible particulars.
- Prolonged Coaching Datasets: Moreover datasets like KITTI and NYU Depth V2, Depth Something V2 makes use of further datasets and artificial information to additional enhance its robustness and accuracy throughout numerous environments.
- Revolutionary Strategies: The mannequin integrates novel methods for dealing with occlusions, various lighting situations, and sophisticated textures, which had been difficult for earlier depth estimation fashions.
- Actual-World Functions: The developments in Depth Something V2 make it appropriate for a variety of functions, together with autonomous driving, robotics, augmented actuality (AR), and digital actuality (VR), the place exact depth info is essential.
Depth Something
Depth Something is a sensible resolution for strong monocular depth estimation. Depth Something is a straightforward but highly effective foundational mannequin able to dealing with any picture in any situation. The dataset is created utilizing a knowledge engine that collects and mechanically annotates many unlabeled information (~62M), considerably rising information protection and decreasing generalization errors.
Two efficient methods had been used: making a tougher optimization goal by means of information augmentation and growing auxiliary supervision to inherit wealthy semantic priors from pre-trained encoders. The fashions are evaluated on zero-shot capabilities utilizing six public datasets and random photographs, demonstrating spectacular generalization. High-quality-tuning with metric depth info from NYUv2 and KITTI information units new state-of-the-art benchmarks.
Monocular depth estimation leverages large-scale unlabeled photos as a substitute of relying solely on expensive and time-consuming strategies like depth sensors, stereo matching, or Construction-from-Movement (SfM). The authors suggest utilizing monocular photos, that are cheap and extensively out there, to construct a sturdy MDE basis mannequin able to producing high-quality depth info beneath varied situations.
They deal with the problem of annotating these unlabeled photos by designing a knowledge engine that mechanically generates depth labels utilizing a pre-trained MDE mannequin. This engine processes 62 million numerous, unlabeled photos from large-scale datasets and enhances them with depth annotations by means of self-training.


💡
The v2 mannequin’s excellent efficiency is obvious in its profitable seize of buildings situated at better distances.
Regardless of the benefits, the authors discover that instantly combining labeled and pseudo-labeled photos initially yields restricted enhancements. To beat this, they introduce a tougher optimization technique for studying pseudo labels and incorporate auxiliary semantic segmentation duties to enhance scene understanding. Moreover, they use DINOv2’s sturdy semantic capabilities to align options and enhance MDE efficiency, leading to a mannequin that excels in each depth estimation and multi-task notion.
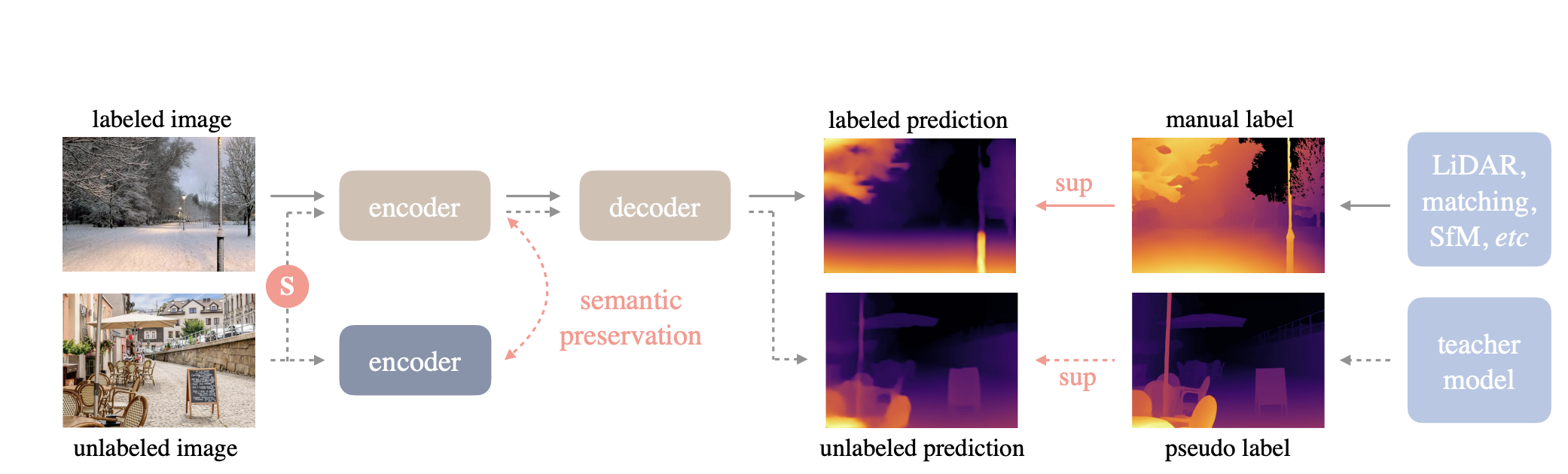
On this work, the authors enhance monocular depth estimation (MDE) by leveraging each labeled and unlabeled photos. They begin by coaching a trainer mannequin utilizing a labeled dataset, the place every picture has a corresponding depth label. This trainer mannequin is then used to generate pseudo depth labels for an unlabeled dataset. By doing so, the unlabeled photos are successfully remodeled into pseudo-labeled information. The subsequent step entails coaching a pupil mannequin on a mixture of the unique labeled dataset and the newly created pseudo-labeled dataset. This mixed coaching method permits the coed mannequin to study from a a lot bigger and extra numerous set of information, enhancing its generalization capabilities and general efficiency in depth estimation duties.
The pipeline permits to make use of the mannequin in just a few strains of code:
from transformers import pipeline
from PIL import Picture
import requests
# load pipe
pipe = pipeline(activity="depth-estimation", mannequin="LiheYoung/depth-anything-small-hf")
# load picture
url="http://photos.cocodataset.org/val2017/000000039769.jpg"
picture = Picture.open(requests.get(url, stream=True).uncooked)
# inference
depth = pipe(picture)["depth"]
Depth Something v2
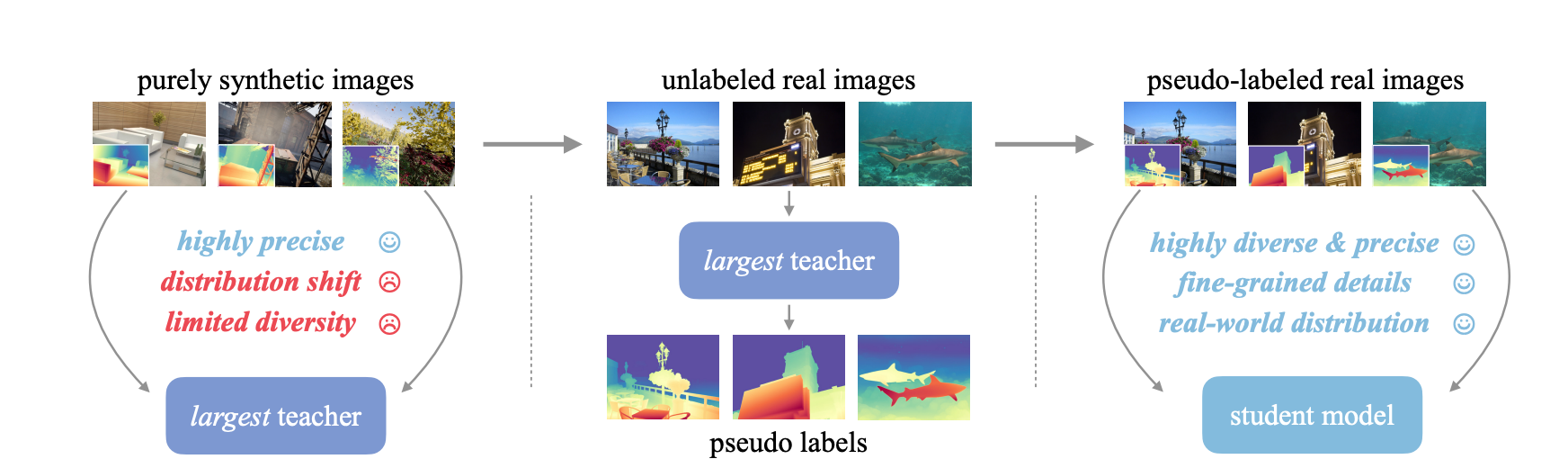
Depth Something V2, a major improve from V1, aimed to reinforce the monocular depth estimation mannequin. The principle focus of this method goals on bettering three key factors: utilizing artificial photos as a substitute of labeled actual ones, rising the capability of our trainer mannequin, and coaching pupil fashions with large-scale pseudo-labeled actual photos. These modifications make the fashions not solely quicker—over ten instances extra environment friendly—than the newest Steady Diffusion-based fashions but additionally extra correct.
We now have detailed weblog on this mannequin. Please click on on the hyperlink to take a look at the weblog!

The coaching pipeline for Depth Something V2 is simple and entails three steps:
- Practice a dependable trainer mannequin utilizing DINOv2-G solely on high-quality artificial photos.
- Generate correct pseudo-depth labels for large-scale unlabeled actual photos.
- Practice the ultimate pupil fashions on these pseudo-labeled actual photos to make sure strong generalization (demonstrating that artificial photos usually are not wanted at this stage).
Loss Features
Coaching fashions for monocular depth estimation on numerous datasets is difficult attributable to various types of floor fact (absolute depth, scaled depth, or disparity maps). An appropriate coaching scheme should function in a suitable output area and use a versatile loss perform to deal with numerous information sources. The important thing challenges are: 1) Differing depth representations (direct vs. inverse), 2) Scale ambiguity (depth given as much as an unknown scale), and three) Shift ambiguity (disparity affected by unknown baseline and post-processing shifts).
Scale- and shift-invariant losses:- Scale- and shift-invariant losses for monocular depth estimation are strategies designed to precisely measure the efficiency of a mannequin, even when the depth information offered has uncertainties associated to scale and shift. Right here’s a simplified clarification:
- Scale Invariance: In some datasets, the depth info is simply offered as much as an unknown scale, that means we do not know the precise distances however fairly the relative distances. A scale-invariant loss ensures that the mannequin can nonetheless study to estimate depth precisely while not having to know the precise scale. It focuses on the relative distances between objects, fairly than their absolute distances.
- Shift Invariance: Some datasets present depth info (disparity maps) that is likely to be shifted attributable to calibration points or processing steps. A shift-invariant loss accounts for these shifts, permitting the mannequin to study the proper depth relationships with out being thrown off by these unknown shifts.
These losses assist the mannequin deal with studying the true depth relationships within the scene, no matter unknown scales or shifts within the enter information, making it extra strong and efficient throughout numerous datasets.
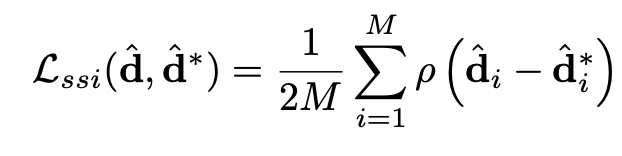
Functions of Monocular Depth Estimation
Monocular depth estimation finds usefulness in numerous functions.
Listed here are some notable use instances:-
- Autonomous Automobiles: Depth estimation helps in figuring out and avoiding obstacles for autonomous automobiles by offering a 3D understanding of the surroundings.
- Augmented Actuality (AR) and Digital Actuality (VR): This mannequin can serve properly to create reasonable 3D fashions for gaming or AR and VR experiences.
- Medical Imaging: Could be helpful to assists in diagnosing situations by analyzing depth-related modifications in medical scans.
- Surveillance and Safety: The power to acknowledge and analyze actions by understanding the depth and motion of individuals.
Conclusions
Monocular depth estimation, using only a single digital camera picture to deduce depth, has emerged as a transformative know-how throughout numerous fields. Its potential to offer useful info from 2D photos enhances functions comparable to autonomous autos, the place it helps in impediment detection and navigation. As know-how advances, monocular depth estimation is a robust algorithm to drive innovation and effectivity, making it a key element in the way forward for varied industries.