
{kind=link}
Introduction
The H100, Nvidia’s newest GPU, is a powerhouse constructed for AI, boasting 80 billion transistors—six instances greater than the earlier A100. This enables it to deal with huge knowledge masses a lot sooner than another GPU available on the market.
AI or any deep studying functions want vital processing energy to coach and run successfully. The H100 comes with highly effective computing capabilities, making the GPU excellent for any deep studying duties. The GPU is constructed to coach giant language fashions (LLMs) for textual content era, language translation, develop self-driving automobiles, medical prognosis techniques, and different AI-driven functions.
H100, constructed on Hopper structure, is known as after the well-known laptop scientist and U.S. Navy Rear Admiral Grace Hopper. It builds on the Turing and Ampere architectures, introducing a brand new streaming multiprocessor and a sooner reminiscence subsystem.
💡
Paperspace now helps the NVIDIA H100 each with a single chip (NVIDIA H100x1) and with eight chips (NVIDIA H100x8), at present within the NYC2 datacenter.
Highly effective GPUs equivalent to H100 are essential {hardware} on the subject of coaching deep studying mannequin. These beefy GPUs are constructed to deal with huge quantities of knowledge and compute advanced operations simply that are very a lot vital for coaching any AI fashions.
Why is GPU required for Deep Studying?
GPUs present excessive parallel processing energy which is crucial to deal with advanced computations for neural networks. GPUs are designed to preform totally different calculations concurrently and which in flip accelerates the coaching and inference for any giant language mannequin. Moreover, GPUs can deal with giant datasets and sophisticated fashions extra effectively, enabling the event of superior AI functions.
A number of deep studying algorithms require highly effective GPUs to carry out effectively. A few of these embody:
- Convolutional Neural Networks (CNNs): Used for picture and video recognition, CNNs depend on intensive parallel processing for dealing with giant datasets and sophisticated computations.
- Recurrent Neural Networks (RNNs) and Lengthy Brief-Time period Reminiscence Networks (LSTMs): These are used for sequential knowledge like time collection and pure language processing, requiring vital computational energy to handle their intricate architectures.
- Generative Adversarial Networks (GANs): GANs include two neural networks competing in opposition to one another, demanding substantial processing energy to generate high-quality artificial knowledge.
- Transformer Networks: Utilized in pure language processing duties, equivalent to BERT and GPT fashions, these networks want appreciable computational assets for coaching resulting from their large-scale architectures and big datasets.
- Autoencoders: Employed for duties like dimensionality discount and anomaly detection, autoencoders require highly effective GPUs to effectively course of high-dimensional knowledge.
- Gradient Descent: This elementary optimization algorithm is used to reduce the loss perform in neural networks. The big-scale computations concerned in updating weights and biases throughout coaching are considerably accelerated by GPUs.
These algorithms profit vastly from the parallel processing capabilities and pace provided by GPUs.
What’s H100 GPU?
NVIDIA H100 Tensor Core GPU, is the subsequent era highest performing GPU particularly designed for superior computing duties in discipline for AI and deep studying.
The newest structure consists of 4th era tensor cores and devoted transformer engine which is answerable for considerably rising the effectivity on AI and ML computation. This specialised {hardware} accelerates the coaching and inference of transformer-based fashions, that are essential for big language fashions and different superior AI functions.
H100 GPU Structure and Options
The H100 GPU chip helps numerous precision sorts, together with FP8, FP16, FP32, and FP64, impacting the accuracy and pace of calculations. It introduces a devoted Transformer Engine to speed up coaching and inference.
Quick, scalable, and safe, the H100 can join with different H100 GPUs through the NVLink Change System, enabling them to work as a unified cluster for exascale workloads (requiring a minimum of one exaflop of computing energy). It additionally helps PCIe Gen5 and options built-in knowledge encryption for safety.
The H100 can speed up the coaching and inference of enormous language fashions by as much as 30 instances over the earlier era, facilitating the event of latest AI functions like conversational AI, recommender techniques, and imaginative and prescient AI.

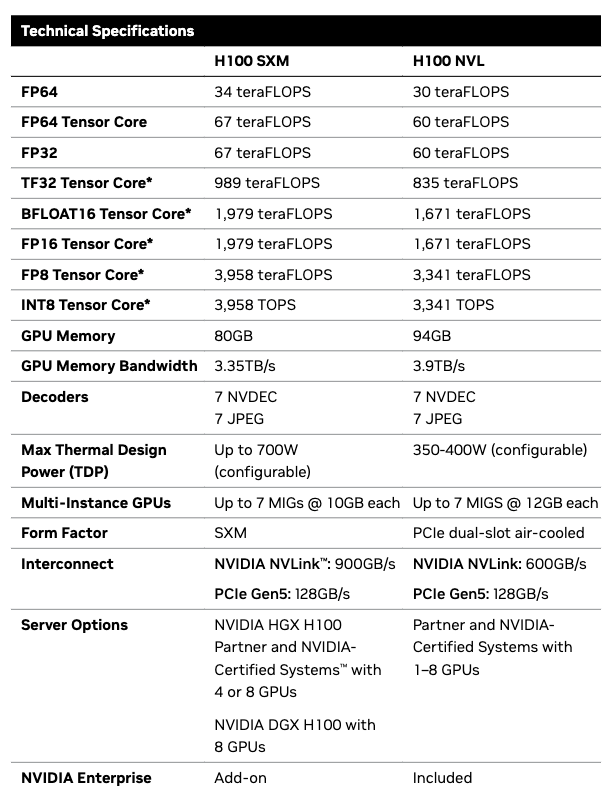
Should you check out the knowledge sheet offered for H100, the totally different columns offered under lists the efficiency and technical specification for this GPU.
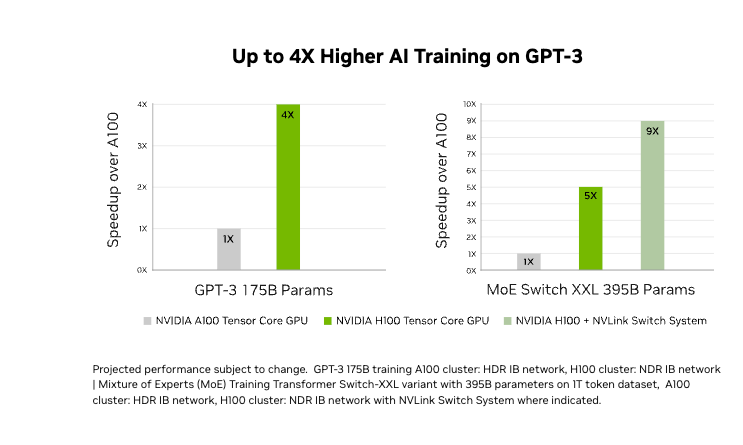
Remodel Mannequin Coaching
The 4th gen tensor cores and a transformer engine with FP8 precision making H100 to coach 4 instances sooner when coaching GPT-3 (175B) fashions in comparison with earlier generations. It combines superior applied sciences like fourth-generation NVLink, offering 900 GB/s of GPU-to-GPU communication; NDR Quantum-2 InfiniBand networking, which accelerates communication between GPUs throughout nodes; PCIe Gen5; and NVIDIA Magnum IO™ software program. These options guarantee environment friendly scaling from small setups to giant.
H100 PCIe Gen 5 GPU
The H100 PCIe Gen 5 configuration packs the identical capabilities because the H100 SXM5 GPUs however operates at simply 350 watts. It may join as much as two GPUs with an NVLink bridge, providing almost 5 instances the bandwidth of PCIe Gen 5. This setup is good for traditional racks and is nice for functions that use 1 or 2 GPUs, equivalent to AI inference and a few HPC duties. Notably, a single H100 PCIe GPU delivers 65% of the efficiency of the H100 SXM5 whereas consuming solely 50% of the facility.
Notable Options
The NVIDIA H100 NVL GPU, outfitted with a number of superior options, optimizes efficiency and scalability for big language fashions (LLMs). Right here’s a breakdown:

- Fourth-generation Tensor Cores: The H100 is as much as 6 instances sooner at chip-to-chip communication in comparison with the A100. This speedup is because of a number of components, together with elevated processing items (Streaming Multiprocessors or SMs), increased clock speeds, and improved structure. Moreover, utilizing the brand new FP8 knowledge kind, the H100 Tensor Cores obtain 4 instances the computational charge of the A100’s previous-generation 16-bit floating-point choices.
- PCIe-based NVIDIA H100 NVL with NVLink Bridge: This setup makes use of PCIe (Peripheral Part Interconnect Categorical) for quick communication between the GPU and different parts, and NVLink bridge know-how to attach a number of GPUs, enhancing knowledge switch speeds and effectivity.
- Transformer Engine: A specialised {hardware} unit throughout the H100 designed to speed up the coaching and inference of transformer-based fashions, that are generally utilized in giant language fashions. This new Transformer Engine makes use of a mixture of software program and customized Hopper Tensor
Core know-how designed particularly to speed up Transformer mannequin coaching and
inference. - 188GB HBM3 Reminiscence: Excessive-Bandwidth Reminiscence (HBM3) is used within the H100 NVL to offer giant, quick reminiscence capability, essential for dealing with the huge quantities of knowledge processed by LLMs.
- Optimum Efficiency and Simple Scaling: The mixture of those applied sciences permits for top efficiency and simple scalability, making it simpler to increase computational capabilities throughout totally different knowledge facilities.
- Bringing LLMs to the Mainstream: These capabilities make it possible to deploy giant language fashions extra extensively and effectively in numerous settings, not simply in specialised, high-resource environments.
- Efficiency Enchancment: Servers outfitted with H100 NVL GPUs can enhance the efficiency of LLMs like Llama 2 70B by as much as 5 instances in comparison with previous-generation NVIDIA A100 techniques.
- Low Latency in Energy-Constrained Environments: Regardless of the numerous efficiency increase, the H100 NVL maintains low latency, which is essential for real-time functions, even in environments the place energy consumption is a priority.
These superior options of the H100 NVL GPU improve the efficiency and scalability of enormous language fashions, making them extra accessible and environment friendly for mainstream use.

The H100 GPU is extremely versatile, suitable with a variety of AI frameworks and libraries like TensorFlow, PyTorch, CUDA, cuDNN, JAX, and lots of different. This seamless integration simplifies adoption and future-proofs investments, making it an important software for AI researchers, builders, and knowledge scientists.
How Paperspace Stands Out?
Paperspace now helps NVIDIA H100x1 with 80 and NVIDIA H100x8 with 640 GB GPU Reminiscence and can be found as on-demand compute.
Listed here are few key factors on Paperspace’s providing for NVIDIA H100 GPUs:
Efficiency Enhance:
- NVIDIA H100 GPUs ship huge efficiency enhancements in AI and machine studying (AI/ML). They’re as much as 9 instances sooner in coaching AI fashions and as much as 30 instances sooner in making predictions (inference) in comparison with the previous-generation NVIDIA A100 GPUs.
- Transformer Engine & 4th Gen Tensor Cores: These superior applied sciences within the H100 GPUs allow these dramatic speedups, particularly for big language fashions and artificial media fashions.
Paperspace’s Choices:
- Occasion Choices: Paperspace gives H100 GPUs as each on-demand (you should use them each time wanted) and reserved cases (you decide to utilizing them for a set interval, normally at a decrease price).
- Price: H100 cases begin at $2.24 per hour per GPU. Paperspace gives versatile billing choices, together with per-second billing and limitless bandwidth, serving to to handle and cut back prices.
“Coaching our next-generation text-to-video mannequin with thousands and thousands of video inputs on NVIDIA H100 GPUs on Paperspace took us simply 3 days, enabling us to get a more moderen model of our mannequin a lot sooner than earlier than. We additionally respect Paperspace’s stability and glorious buyer assist, which has enabled our enterprise to remain forward of the AI curve. – Naeem Ahmed, Founder, Moonvalley AI
Scalability:
- Multi-node Deployment: You may deploy as much as 8 H100 GPUs collectively, which may work as a unified system due to their 3.2TBps NVIDIA NVLink interconnect. This setup is good for dealing with very giant and sophisticated fashions.

Ease of Use:
- Fast Setup: You can begin utilizing an H100 GPU occasion inside seconds. Paperspace’s “ML-in-a-box” answer consists of all the things wanted: GPUs, Ubuntu Linux photographs, personal community, SSD storage, public IPs, and snapshots, offering a whole and ready-to-use setting for machine studying.
Reliability and Help:
- 24/7 Monitoring: Paperspace’s platform is constantly monitored to make sure reliability. If any points come up, their buyer assist is out there to assist, particularly throughout high-traffic durations.
Paperspace’s new H100 GPU providing offers highly effective, scalable, and cost-effective options for AI/ML duties, making it simpler and sooner to coach giant fashions and carry out advanced computations.
“As Paperspace — an Elite member of the NVIDIA Cloud Service Supplier Companion Program — launches assist for the brand new NVIDIA H100 GPU, builders constructing and scaling their AI functions on Paperspace will now have entry to unprecedented efficiency by way of the world’s strongest GPU for AI.” – Dave Salvator, Director of Accelerated Computing, NVIDIA
Conclusion
The NVIDIA H100 is a big development in hig-performance computing and units up a brand new bar within the AI discipline. With its cutting-edge structure, together with the brand new Transformer Engine and assist for numerous precision sorts, the H100 is right here to drive vital improvements in AI analysis and software.
Wanting forward, the H100’s capabilities will possible speed up the event of more and more refined fashions and applied sciences, shaping the way forward for synthetic intelligence and high-performance computing. As organizations undertake these highly effective GPUs, they’ll unlock new prospects and push the boundaries of what’s achievable in AI and knowledge science.
We hope you loved studying the article!