
{kind=link}
Imaginative and prescient-language fashions are among the many superior synthetic intelligence AI programs designed to know and course of visible and textual knowledge collectively. These fashions are identified to mix the capabilities of laptop imaginative and prescient and pure language processing duties. The fashions are educated to interpret photographs and generate descriptions concerning the picture, enabling a variety of functions akin to picture captioning, visible query answering, and text-to-image synthesis. These fashions are educated on giant datasets and highly effective neural community architectures, which helps the fashions to be taught advanced relationships. This, in flip, permits the fashions to carry out the specified duties. This superior system opens up prospects for human-computer interplay and the event of clever programs that may talk equally to people.
Giant Multimodal Fashions (LMMs) are fairly highly effective nevertheless they wrestle with the high-resolution enter and scene understanding. To deal with these challenges Monkey was just lately launched. Monkey, a vision-language mannequin, processes enter photographs by dividing the enter photographs into uniform patches, with every patch matching the scale utilized in its unique imaginative and prescient encoder coaching (e.g., 448×448 pixels).
This design permits the mannequin to deal with high-resolution photographs. Monkey employs a two-part technique: first, it enhances visible seize by larger decision; second, it makes use of a multi-level description era technique to counterpoint scene-object associations, making a extra complete understanding of the visible knowledge. This method improves studying from the information by capturing detailed visuals, enhancing descriptive textual content era’s effectiveness.
Monkey Structure Overview
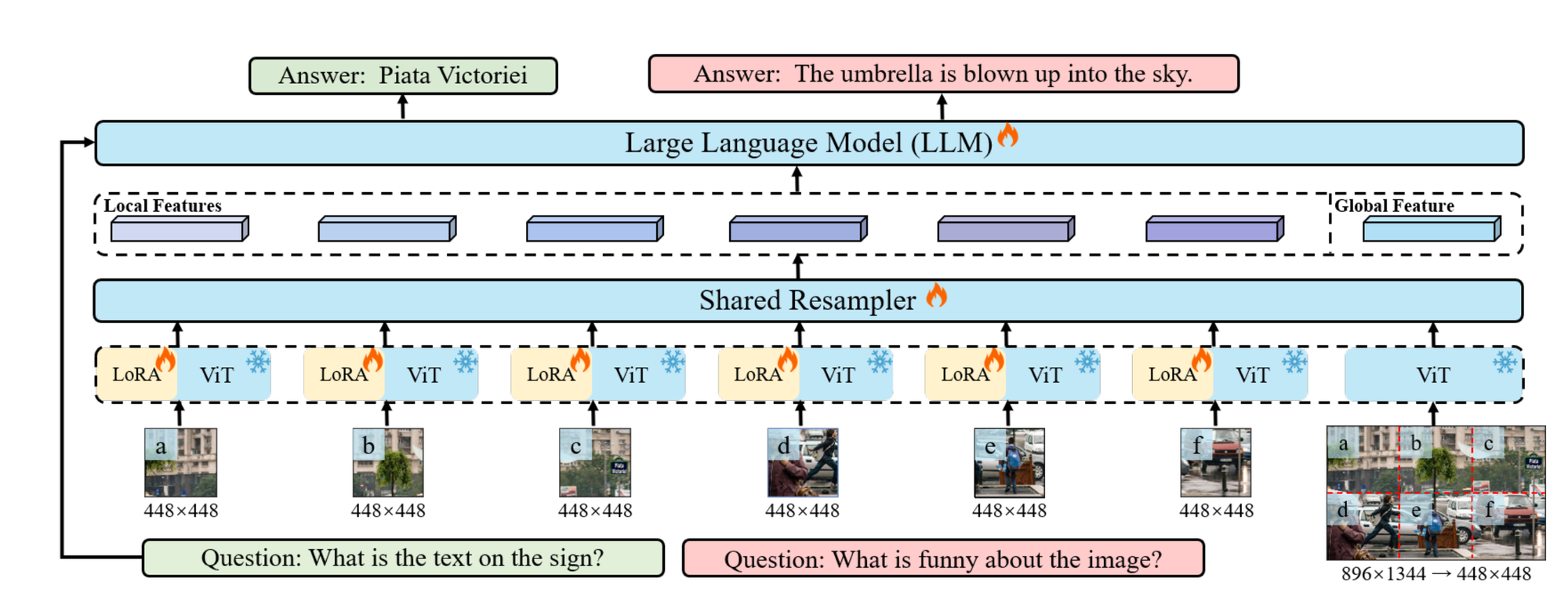
Let’s break down this method step-by-step.
Picture Processing with Sliding Window
- Enter Picture: A picture (I) with dimensions (H X W X 3), the place (H) and (W) are the peak and width of the picture, and three represents the colour channels (RGB).
- Sliding Window: The picture is split into smaller sections utilizing a sliding window (W) with dimensions (H_v X W_v). This course of partitions the picture into native sections, which permits the mannequin to deal with particular components of the picture.
LoRA Integration
- LoRA (Low-Rank Adaptation): LoRA is employed inside every shared encoder to deal with the various visible components current in numerous components of the picture. LoRA helps the encoders seize detail-sensitive options extra successfully with out considerably rising the mannequin’s parameters or computational load.
Sustaining Structural Info
- World Picture Resizing: To protect the general structural info of the enter picture, the unique picture is resized to dimensions ((H_v, W_v)), creating a world picture. This world picture maintains a holistic view whereas the patches present detailed views.
Processing with Visible Encoder and Resampler
- Concurrent Processing: Each the person patches and the worldwide picture are processed by the visible encoder and resampler concurrently.
- Visible Resampler: Impressed by the Flamingo mannequin, the visible resampler performs two important features:
- Summarizing Visible Info: It condenses the visible info from the picture sections.
- Acquiring Increased Semantic Representations: It transforms visible info right into a language characteristic area for higher semantic understanding.
Cross-Consideration Module
- Cross-Consideration Mechanism: The resampler makes use of a cross-attention module the place trainable vectors (embeddings) act as question vectors. Picture options from the visible encoder function keys within the cross-attention operation. This enables the mannequin to deal with essential picture components whereas incorporating contextual info.
Balancing Element and Holistic Understanding
- Balanced Method: This technique balances the necessity for detailed native evaluation and a holistic world picture perspective. This steadiness enhances the mannequin’s efficiency by capturing detailed options and general construction with out considerably rising computational assets.
This method improves the mannequin’s capability to know advanced photographs by combining native element evaluation with a world overview, leveraging superior methods like LoRA and cross-attention.
Few Key Factors
- Useful resource-Environment friendly Enter Decision Improve: Monkey enhances enter decision in LMMs with out requiring in depth pre-training. As a substitute of straight interpolating Imaginative and prescient Transformer (ViT) fashions to deal with larger resolutions, it employs a sliding window technique to divide high-resolution photographs into smaller patches. Every patch is processed by a static visible encoder with LoRA changes and a trainable visible resampler.
- Sustaining Coaching Knowledge Distribution: Monkey capitalizes on encoders educated on smaller resolutions (e.g., 448×448) by resizing every patch to the supported decision. This method maintains the unique knowledge distribution, avoiding pricey coaching from scratch.
- Trainable Patches Benefit: The tactic makes use of varied trainable patches, enhancing decision extra successfully than conventional interpolation methods for positional embedding.
- Automated Multi-Degree Description Era: Monkey incorporates a number of superior programs (e.g., BLIP2, PPOCR, GRIT, SAM, ChatGPT) to generate high-quality captions by combining insights from these mills. This method captures a large spectrum of visible particulars by layered and contextual understanding.
- Benefits of Monkey:
- Excessive-Decision Assist: Helps resolutions as much as 1344×896 with out pre-training, aiding in figuring out small or densely packed objects and textual content.
- Improved Contextual Associations: Enhances understanding of relationships amongst a number of targets and leverages frequent information for higher textual content description era.
- Efficiency Enhancements: Exhibits aggressive efficiency throughout varied duties, together with Picture Captioning and Visible Query Answering, demonstrating promising outcomes in comparison with fashions like GPT-4V, particularly in dense textual content query answering.
Total, Monkey affords a complicated approach to enhance decision and outline era in LMMs through the use of current fashions extra effectively.
How can I do visible Q&A with Monkey?
To run the Monkey Mannequin and experiment with it, we first login to Paperspace and begin a pocket book, or you can begin up a terminal. We extremely suggest utilizing an A4000 GPU to run the mannequin.
The NVIDIA A6000 GPU is a strong graphics card that’s identified for its distinctive efficiency in varied AI and machine studying functions, together with visible query answering (VQA). With its reminiscence and superior Ampere structure, the A4000 affords excessive throughput and effectivity, making it supreme for dealing with the advanced computations required in VQA duties.
!nvidia-smi
Setup
Carry this mission to life
We are going to run the under code cells. It will clone the repository, and set up the necessities.txt file.
git clone https://github.com/Yuliang-Liu/Monkey.git
cd ./Monkey
pip set up -r necessities.txtWe will run the gradio demo which is quick and straightforward to make use of.
python demo.pyor comply with the code alongside.
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "echo840/Monkey-Chat"
mannequin = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
tokenizer.padding_side="left"
tokenizer.pad_token_id = tokenizer.eod_idThe code above masses the pre-trained mannequin and tokenizer from the Hugging Face Transformers library.
“echo840/Monkey-Chat” is the identify of the mannequin checkpoint we’ll load. Subsequent, we’ll load the mannequin weights and configurations and map the system to CUDA-enabled GPU for quicker computation.
img_path="/notebooks/quick_start_pytorch_images/picture 2.png"
query = "present an in depth caption for the picture"
question = f'<img>{img_path}</img> {query} Reply: '
input_ids = tokenizer(question, return_tensors="pt", padding='longest')
attention_mask = input_ids.attention_mask
input_ids = input_ids.input_ids
pred = mannequin.generate(
input_ids=input_ids.cuda(),
attention_mask=attention_mask.cuda(),
do_sample=False,
num_beams=1,
max_new_tokens=512,
min_new_tokens=1,
length_penalty = 1,
num_return_sequences=1,
output_hidden_states=True,
use_cache=True,
pad_token_id=tokenizer.eod_id,
eos_token_id=tokenizer.eod_id,
)
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip()
print(response)This code will generate the detailed caption or description or another output primarily based on the immediate question utilizing Monkey. We are going to specify the trail the place we have now saved our picture and formulating a question string that features the picture reference and the query asking for a caption. Subsequent, the question is tokenised utilizing the ‘tokenizer’ which converts the enter texts into token IDs.
Parameters akin to do_sample=False and num_beams=1 guarantee deterministic output by disabling sampling. Different parameters like max_new_tokens, min_new_tokens, and length_penalty management the size and nature of the generated sequence. After era, the output tokens are decoded again into human-readable textual content, skipping any particular tokens, to kind the ultimate response, which is a caption describing the picture. Lastly, we print the generated caption.
Outcomes
We tried the mannequin with a particularly primary picture of only a screenshot, and it does pretty properly in recognizing what the picture is.
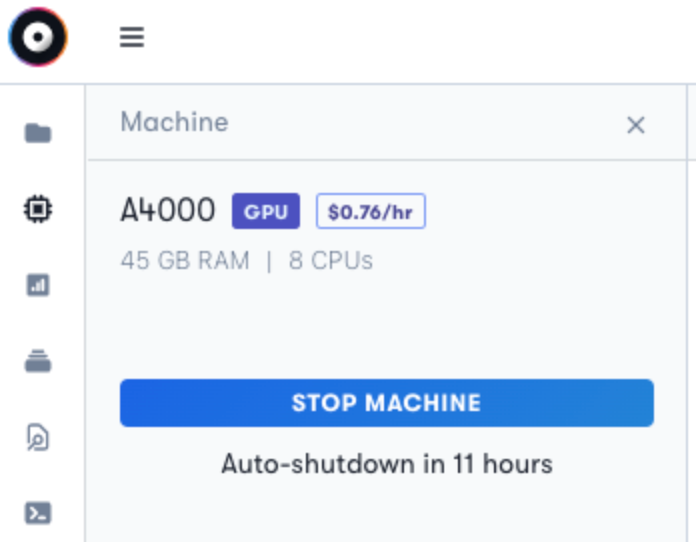
Monkey Output:- The picture shows a pc interface with a blue background. The principle focus is on a machine with the label “A4000” and the worth “$0.76/hr”. The machine is provided with 45 GB RAM and eight CPUs. There are additionally a number of buttons and icons on the interface, together with a blue “STOP MACHINE” button and a white “Auto-shutdown in 11 hours” button. The textual content “45 GB RAM” and “8 CPUs” are additionally seen. The general structure suggests a user-friendly interface for managing digital machines.

Monkey Output:- Within the picture, a golden retriever is captured in mid-air, leaping in the direction of a yellow tennis ball that’s suspended within the air. The canine’s physique is stretched out, with its entrance paws reaching for the ball, and its tail is raised excessive in pleasure. The background is a lush inexperienced garden, offering a stark distinction to the canine’s white fur. The picture is taken from a low angle, making the canine seem bigger and extra imposing. The canine’s centered expression and the dynamic pose recommend a second of intense playfulness.

Immediate:- Present an in depth caption for the picture
Monkey Output:- This picture is a portray of a metropolis skyline at night time. The sky is crammed with swirling yellow and blue colours, making a starry impact. Within the foreground, there’s a tall constructing with a clock on prime. The portray additionally options a big tree with a yellow gentle shining on it. The general impact is one among tranquility and sweetness, harking back to the well-known “Starry Night time” portray by Vincent van Gogh.
We’re fairly impressed by the detailed descriptions and captions that present even the minutest particulars of the picture. The AI-generated caption is actually exceptional!
The under picture highlights Monkey’s capabilities in varied VQA duties. Monkey analyzes questions, identifies key picture components, perceives minute textual content, and causes about objects, and understands visible charts. The determine additionally demonstrates Monkey’s spectacular captioning capability, precisely describing objects and offering summaries.

Comparability Outcomes
In qualitative evaluation, Monkey was in contrast with GPT4V and different LMMs on the duty of producing detailed captions.

Monkey and GPT-4V recognized an “Emporio Armani” retailer within the background, with Monkey offering extra particulars, akin to a lady in a crimson coat and black pants carrying a black purse. (Picture Supply)
Additional experiments have proven that in lots of circumstances, Monkey has demonstrated spectacular efficiency in comparison with GPT4V with regards to understanding advanced text-based inquiries.

The VQA activity comparability ends in the under determine present that by scaling up the mannequin dimension, Monkey achieves vital efficiency benefits in duties involving dense textual content. It not solely outperforms QwenVL-Chat [3], LLaVA-1.5 [29], and mPLUG-Owl2 [56] but in addition achieves promising outcomes in comparison with GPT-4V [42]. This demonstrates the significance of scaling up mannequin dimension for efficiency enchancment in multimodal giant fashions and validates our technique’s effectiveness in enhancing their efficiency.

Sensible Software
- Automated Picture Captioning: Generate detailed descriptions for photographs in varied domains, akin to e-commerce, social media, and digital archives.
- Assistive Applied sciences: Assist visually impaired people by producing descriptive captions for photographs in real-time functions, akin to display screen readers and navigation aids.
- Interactive Chatbots: Combine with chatbots to offer detailed visible explanations and context in buyer help and digital assistants, enhancing consumer expertise in varied providers.
- Picture-Based mostly Search Engines: Enhance picture search capabilities by offering wealthy, context-aware descriptions that improve search accuracy and relevance.
Conclusion
On this article, we talk about the Monkey chat imaginative and prescient mannequin, the mannequin achieved good outcomes when tried with totally different photographs to generate captions and even to know what’s within the picture. The analysis claims that the mannequin outperforms varied LMMs together with GPT-4v. Its enhanced enter decision additionally considerably improves efficiency on doc photographs with dense textual content. Leveraging superior methods akin to sliding home windows and cross-attention successfully balances native and world picture views. Nonetheless, this technique can be restricted to processing the enter photographs as a most of six patches as a result of language mannequin’s enter size constraints, limiting additional enter decision enlargement.
Regardless of these limitations, the mannequin exhibits vital promise in capturing effective particulars and offering insightful descriptions, significantly for doc photographs with dense textual content.
We hope you loved studying the article!