
{kind=link}
Introduction
In my earlier weblog put up, Constructing Multi-Doc Agentic RAG utilizing LLamaIndex, I demonstrated methods to create a retrieval-augmented technology (RAG) system that would deal with and question throughout three paperwork utilizing LLamaIndex. Whereas that was a robust begin, real-world purposes typically require the flexibility to deal with a bigger corpus of paperwork.
This weblog will give attention to scaling that system from three paperwork to eleven and past. We’ll dive into the code, challenges of scaling, and methods to construct an environment friendly agent that may dynamically retrieve info from a bigger set of sources.
Studying Targets
- Perceive scaling Multi-Doc Agentic RAG system from dealing with a couple of paperwork to over 10+ paperwork utilizing LLamaIndex.
- Learn to construct and combine tool-based question mechanisms to reinforce RAG fashions.
- Perceive using VectorStoreIndex and ObjectIndex in effectively retrieving related paperwork and instruments.
- Implement a dynamic agent able to answering complicated queries by retrieving related papers from a big set of paperwork.
- Establish the challenges and finest practices when scaling RAG methods to a number of paperwork.
This text was printed as part of the Knowledge Science Blogathon.
Key Steps Concerned
Within the earlier weblog, I launched the idea of Agentic RAG—an method the place we mix info retrieval with generative fashions to reply consumer queries utilizing related exterior paperwork. We used LLamaIndex to construct a easy, multi-document agentic RAG, which may question throughout three paperwork.
The important thing steps concerned:
- Doc Ingestion: Utilizing SimpleDirectoryReader to load and cut up paperwork into chunks.
- Index Creation: Leveraging VectorStoreIndex for semantic search and SummaryIndex for summarization.
- Agent Setup: Integrating OpenAI’s API to reply queries by retrieving related chunks of knowledge from the paperwork.
Whereas this setup labored properly for a small variety of paperwork, we encountered challenges in scalability. As we expanded past three paperwork, points like instrument administration, efficiency overhead, and slower question responses arose. This put up addresses these challenges.
Key Challenges in Scaling to 10+ Paperwork
Scaling to 11 or extra paperwork introduces a number of complexities:
Efficiency Issues
Querying throughout a number of paperwork will increase the computational load, particularly by way of reminiscence utilization and response occasions. When the system processes a bigger variety of paperwork, guaranteeing fast and correct responses turns into a major problem.
Device Administration
Every doc is paired with its personal retrieval and summarization instrument, which means the system wants a sturdy mechanism to handle these instruments effectively.
Index Effectivity
With 11 paperwork, utilizing the VectorStoreIndex turns into extra complicated. The bigger the index, the extra the system must sift via to search out related info, probably rising question occasions. We’ll focus on how LLamaIndex effectively handles these challenges with its indexing strategies.
Implementing the Code to Deal with 10+ Paperwork
Let’s dive into the implementation to scale our Agentic RAG from three to 11 paperwork.
Doc Assortment
Listed below are the 11 papers we’ll be working with:
- MetaGPT
- LongLoRA
- LoFT-Q
- SWE-Bench
- SelfRAG
- Zipformer
- Values
- Finetune Honest Diffusion
- Information Card
- Metra
- VR-MCL
Step one is to obtain the papers. Right here’s the Python code to automate this:
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=LzPWWPAdY4",
"https://openreview.net/pdf?id=VTF8yNQM66",
"https://openreview.net/pdf?id=hSyW5go0v8",
"https://openreview.net/pdf?id=9WD9KwssyT",
"https://openreview.net/pdf?id=yV6fD7LYkF",
"https://openreview.net/pdf?id=hnrB5YHoYu",
"https://openreview.net/pdf?id=WbWtOYIzIK",
"https://openreview.net/pdf?id=c5pwL0Soay",
"https://openreview.net/pdf?id=TpD2aG1h0D"
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"loftq.pdf",
"swebench.pdf",
"selfrag.pdf",
"zipformer.pdf",
"values.pdf",
"finetune_fair_diffusion.pdf",
"knowledge_card.pdf",
"metra.pdf",
"vr_mcl.pdf"
]
# Downloading the papers
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"Device Setup
As soon as the paperwork are downloaded, the subsequent step is to create the instruments required for querying and summarizing every doc.
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, SummaryIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.instruments import FunctionTool, QueryEngineTool
from llama_index.core.vector_stores import MetadataFilters, FilterCondition
from typing import Checklist, Optionally available
def get_doc_tools(
file_path: str,
title: str,
) -> str:
"""Get vector question and abstract question instruments from a doc."""
# load paperwork
paperwork = SimpleDirectoryReader(input_files=[file_path]).load_data()
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(paperwork)
vector_index = VectorStoreIndex(nodes)
def vector_query(
question: str,
page_numbers: Optionally available[List[str]] = None
) -> str:
"""Use to reply questions over a given paper.
Helpful when you've got particular questions over the paper.
At all times depart page_numbers as None UNLESS there's a particular web page you wish to seek for.
Args:
question (str): the string question to be embedded.
page_numbers (Optionally available[List[str]]): Filter by set of pages. Go away as NONE
if we wish to carry out a vector search
over all pages. In any other case, filter by the set of specified pages.
"""
page_numbers = page_numbers or []
metadata_dicts = [
{"key": "page_label", "value": p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
situation=FilterCondition.OR
)
)
response = query_engine.question(question)
return response
vector_query_tool = FunctionTool.from_defaults(
title=f"vector_tool_{title}",
fn=vector_query
)
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
title=f"summary_tool_{title}",
query_engine=summary_query_engine,
description=(
f"Helpful for summarization questions associated to {title}"
),
)
return vector_query_tool, summary_toolThis operate generates vector and abstract question instruments for every doc, permitting the system to deal with queries and generate summaries effectively.
Now we’ll improve agentic RAG with instrument retrieval.
Constructing the Agent
Subsequent, we have to prolong the agent with the flexibility to retrieve and handle instruments from all 11 paperwork.
from utils import get_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
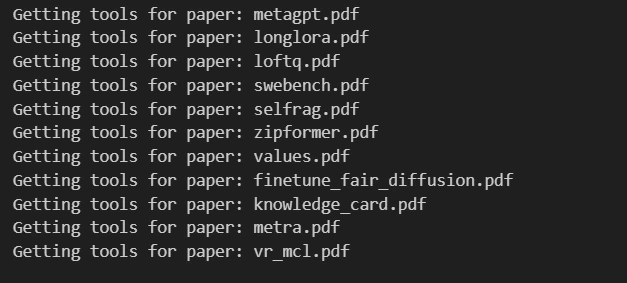
for paper in papers:
print(f"Getting instruments for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
paper_to_tools_dict[paper] = [vector_tool, summary_tool]
all_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]Output will appear like under:
Device Retrieval
The following step is to create an “object” index over these instruments and construct a retrieval system that may dynamically pull the related instruments for a given question.
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)Now, the system can retrieve essentially the most related instruments primarily based on the question.
Let’s see an instance:
instruments = obj_retriever.retrieve(
"Inform me in regards to the eval dataset utilized in MetaGPT and SWE-Bench"
)
#retrieves 3 objects, lets see the third one
print(instruments[2].metadata)
Agent Setup
Now, we combine the instrument retriever into the agent runner, guaranteeing it dynamically selects the most effective instruments to answer every question.
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt="""
You might be an agent designed to reply queries over a set of given papers.
Please at all times use the instruments supplied to reply a query. Don't depend on prior information.
""",
verbose=True
)
agent = AgentRunner(agent_worker)Querying Throughout 11 Paperwork
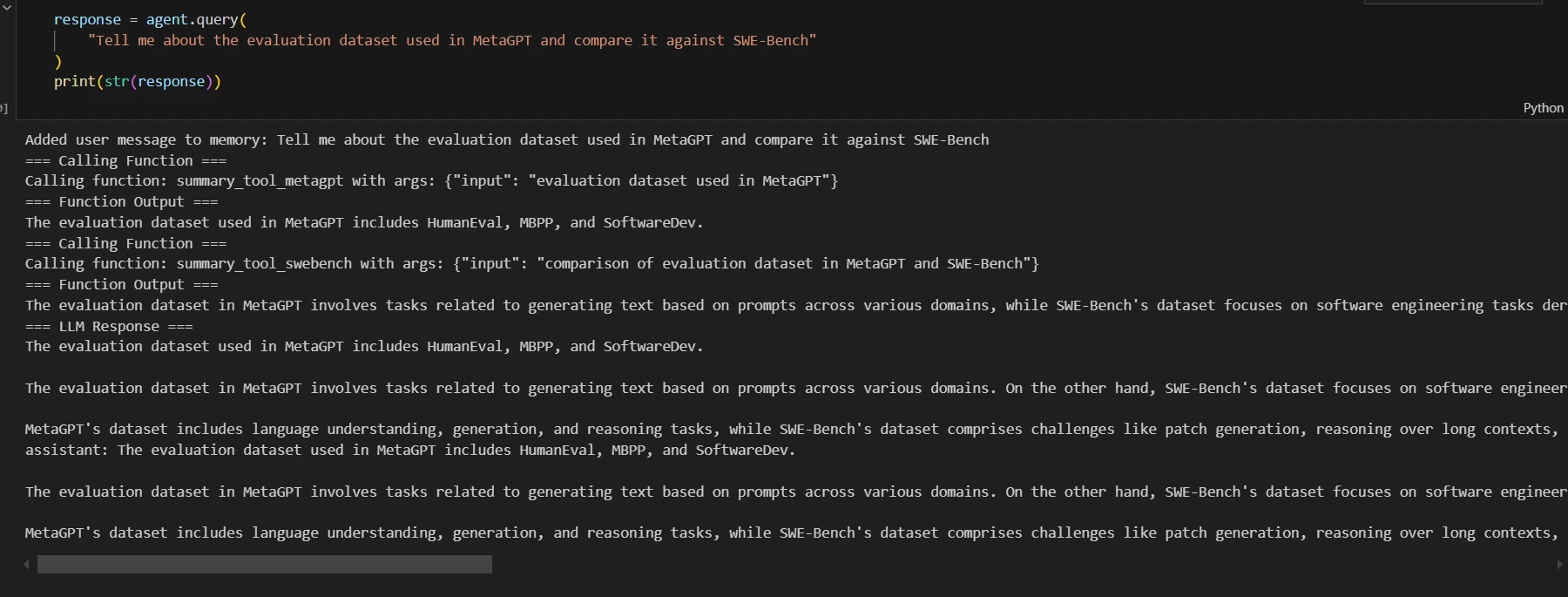
Let’s see how the system performs when querying throughout a number of paperwork. We’ll question each the MetaGPT and SWE-Bench papers to match their analysis datasets.
response = agent.question("Inform me in regards to the analysis dataset utilized in MetaGPT and examine it towards SWE-Bench")
print(str(response))
Output:
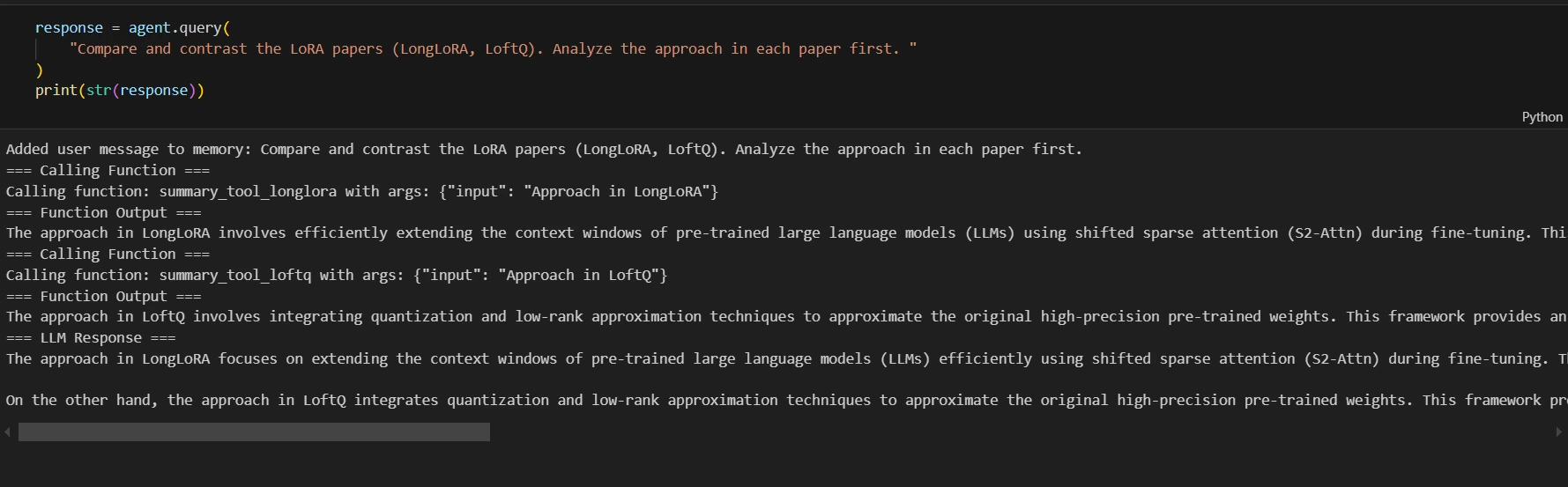
Let’s see different instance
response = agent.question(
"Evaluate and distinction the LoRA papers (LongLoRA, LoftQ). Analyze the method in every paper first. "
)
print(str(response))
Output:
Outcomes and Efficiency Insights
We’ll now discover the outcomes and efficiency insights under:
Efficiency Metrics
When scaling to 11 paperwork, the efficiency remained strong, however we noticed a rise in question occasions by roughly 15-20% in comparison with the 3-document setup. The general retrieval accuracy, nonetheless, stayed constant.
Scalability Evaluation
The system is extremely scalable due to LLamaIndex’s environment friendly chunking and indexing. By fastidiously managing the instruments, we have been in a position to deal with 11 paperwork with minimal overhead. This method might be expanded to help much more paperwork, permitting additional development in real-world purposes.
Conclusion
Scaling from three to 11+ paperwork is a big milestone in constructing a sturdy RAG system. This method leverages LLamaIndex to handle giant units of paperwork whereas sustaining the system’s efficiency and responsiveness.
I encourage you to strive scaling your personal retrieval-augmented technology methods utilizing LLamaIndex and share your outcomes. Be at liberty to take a look at my earlier weblog right here to get began!
Key Takeaways
- It’s attainable to scale a Retrieval-Augmented Era (RAG) system to deal with extra paperwork utilizing environment friendly indexing strategies like VectorStoreIndex and ObjectIndex.
- By assigning particular instruments to paperwork (vector search, abstract instruments), brokers can leverage specialised strategies for retrieving info, bettering response accuracy.
- Utilizing the AgentRunner with instrument retrieval permits brokers to intelligently choose and apply the correct instruments primarily based on the question, making the system extra versatile and adaptive.
- Even when coping with a lot of paperwork, RAG methods can keep responsiveness and accuracy by retrieving and making use of instruments dynamically, somewhat than brute-force looking all content material.
- Optimizing chunking, instrument task, and indexing methods are essential when scaling RAG methods to make sure efficiency and accuracy.
Often Requested Questions
A. Dealing with 3 paperwork requires easier indexing and retrieval processes. Because the variety of paperwork will increase (e.g., to 10+), you want extra subtle retrieval mechanisms like ObjectIndex and power retrieval to take care of efficiency and accuracy.
A. VectorStoreIndex helps in environment friendly retrieval of doc chunks primarily based on similarity, whereas ObjectIndex lets you retailer and retrieve instruments related to completely different paperwork. Collectively, they assist in managing large-scale doc units successfully.
A. Device-based retrieval permits the system to use specialised instruments (e.g., vector search or summarization) to every doc, bettering the accuracy of solutions and lowering computation time in comparison with treating all paperwork the identical approach.
A. To deal with extra paperwork, you possibly can optimize the retrieval course of by fine-tuning the indexing, utilizing distributed computing strategies, and probably introducing extra superior filtering mechanisms to slender down the doc set earlier than making use of instruments.
A. Scaling Multi-Doc Agentic RAG methods successfully entails optimizing information retrieval strategies, implementing environment friendly indexing methods, and leveraging superior language fashions to reinforce question accuracy. Using instruments like LLamaIndex can considerably enhance the system’s efficiency by facilitating higher administration of a number of paperwork and guaranteeing well timed entry to related info.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Writer’s discretion.
Hey everybody, Ketan right here! I am a Knowledge Scientist at Syngene Worldwide Restricted. I’ve accomplished my Grasp’s in Knowledge Science from VIT AP and I’ve a burning ardour for Generative AI. My experience lies in crafting machine studying fashions and wielding Pure Language Processing for modern tasks. At the moment, I am placing this data to work in drug discovery analysis at Syngene, exploring the potential of LLMs. At all times keen to attach and delve deeper into the ever-evolving world of knowledge science!