
{kind=link}
Deliver this venture to life
CLIP, has been a software for text-image duties, broadly identified for zero-shot classification, text-image retrieval and rather more. Nevertheless, the mannequin has sure limitations because of its brief textual content enter, which is restricted to 77. Lengthy-CLIP, launched in 22 March 2024, addresses this by supporting longer textual content inputs with out sacrificing its zero-shot efficiency. This enchancment comes with challenges like sustaining authentic capabilities and dear pretraining. Lengthy-CLIP affords environment friendly fine-tuning strategies, leading to important efficiency beneficial properties over CLIP in duties like lengthy caption retrieval and conventional text-image retrieval. Moreover, it enhances picture era from detailed textual content descriptions seamlessly.
On this article we are going to carry out zero-shot picture classification utilizing Lengthy-CLIP and perceive the underlying idea of the mannequin.
CLIP’s Limitations
Contrastive Language-Picture Pre-training or broadly referred to as CLIP is a vision-language basis mannequin, which consists of a textual content encoder and a picture encoder. CLIP aligns the imaginative and prescient and language modalities via contrastive studying, a way broadly utilized in downstream duties comparable to zero-shot classification, text-image retrieval, and text-to-image era.
CLIP is a robust software for understanding pictures and textual content, however it struggles with processing detailed textual content descriptions as a result of it is restricted to solely 77 tokens of textual content. Regardless that it is educated on temporary texts, it might successfully solely deal with round 20 tokens. This brief textual content restrict not solely restricts what CLIP can do with textual content but additionally limits how nicely it understands pictures. For instance, when the textual content it is given is only a abstract, it focuses on solely crucial components of the picture and ignores different particulars. Additionally, CLIP typically makes errors when making an attempt to grasp complicated pictures with consists of a number of attributes.
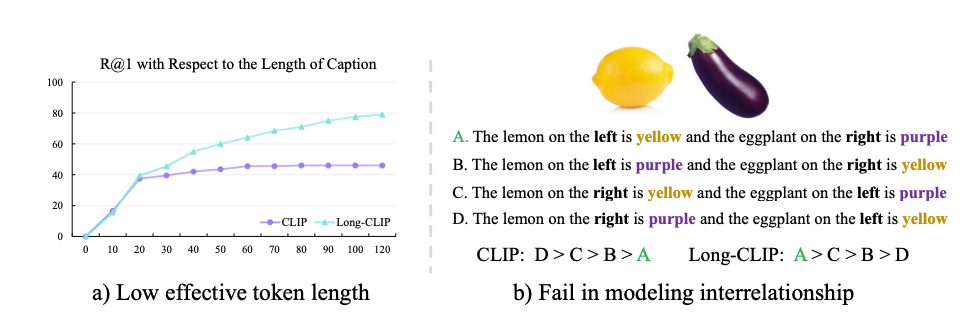
Lengthy texts have plenty of essential particulars and present how various things are related. So, it is actually essential to have the ability to use lengthy texts with CLIP. A method to do that could be to let CLIP deal with longer texts after which prepare it extra with pairs of lengthy texts and pictures. However there are some issues with this method: it messes up the illustration of brief texts, it makes the picture half too targeted on all of the little particulars, and it adjustments the best way CLIP understands issues, making it more durable to make use of in different applications.
To handle the problems of CLIP, Lengthy-CLIP is launched. The mannequin has undergone trainign with longer texts and picture pairs, and a few adjustments on to the way it works to ensure it nonetheless understands brief texts nicely. Researchers claims Lengthy-CLIP, we will use longer texts with out shedding the accuracy of CLIP on duties like classifying pictures or discovering comparable pictures. Additional, Lengthy-CLIP can be utilized in different applications with out the necessity to change something.
General, Lengthy-CLIP helps us perceive pictures and textual content higher, particularly when there are plenty of particulars to work with.
Zero-Shot Classification
Earlier than diving deep into the methodology of the mannequin, allow us to first perceive what’s zero-shot classification.
Supervised studying comes with a value of studying from the information and typically are inclined to develop into impractical when there’s a lack of information. Anotating great amount of information is time consuming, costly and incorrect too. Therefore with the rise of A.I. there the necessity for machine studying and A.I. mannequin to have the ability to work with out the necessity to prepare the mannequin explicitly on new knowledge factors. This want has include the answer of n-shot studying.
The zero-shot idea emerges from N-shot studying, have been the letter ‘N’ denotes the variety of samples required to coach the mannequin and make predictions on a brand new knowledge. The fashions which require fairly some coaching samples are referred to as ‘Many-shot’ learners. These fashions require a big quantity of compute and knowledge to fine-tune. Therefore, with a purpose to mitigate this challenge researchers got here with an answer of zero-shot.
A zero-shot mannequin requires zero coaching samples to work on new knowledge factors. Usually, in zero-shot studying exams, fashions are evaluated on new lessons they have not seen earlier than, which is useful for creating new strategies however not at all times practical. Generalized zero-shot studying offers with eventualities the place fashions should classify knowledge from each acquainted and unfamiliar lessons.
Zero-shot studying works by outputing a likelihood vector which represents the chance that the given object belongs to the precise class.
Few-shot studying, makes use of strategies comparable to switch studying (a way to reuse a educated mannequin for a brand new activity) and meta studying (a subset of ML primarily described as “studying to be taught”), which goals to coach fashions able to figuring out new lessons with a restricted variety of labeled coaching examples. Equally, in one-shot studying, the mannequin is educated to acknowledge new lessons with solely a single labeled instance.
Methodology
The mannequin adapts two novel methods:-
Information Preserving Stretching
The Lengthy-CLIP mannequin effectivity tends to extend because the variety of token will increase. This means the mannequin is ready to successfully be taught and make the most of new peice of data added within the captions.
To deal with the problem of coaching a brand new positional embedding, a well-liked approach includes interpolation. Usually, a broadly adopted method is linear interpolation of the positional embedding with a hard and fast ratio, generally known as λ1.
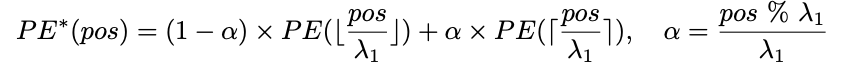
Linear interpolation for this particular activity is not your best option for adjusting place embeddings on this activity. That is as a result of most coaching texts are shorter than the 77 tokens used within the CLIP mannequin. Decrease positions within the sequence are well-trained and precisely signify their absolute positions. Nevertheless, greater positions have not been educated as completely and solely roughly estimate relative positions. So, adjusting the decrease positions an excessive amount of may mess up their correct illustration.
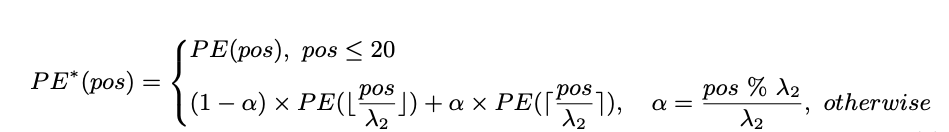
As a substitute, a unique method is used. The embeddings of the highest 20 positions are stored as they’re, as they’re already efficient. However for the remaining 57 positions, a unique methodology known as interpolation is used, the place we mix their embeddings with these of close by positions utilizing a bigger ratio, denoted as λ2. This manner, we will make changes with out disturbing the well-trained decrease positions an excessive amount of.
Nice-tuning with Major Part matching
Additional, to make the mannequin deal with each lengthy and brief captions nicely, extending the size it might deal with or just fine-tune it with lengthy captions wont be of assist. That might mess up its means to take care of brief ones. As a substitute, a technique known as Major Part matching is adopted. Here is the way it works:
- When fine-tuning with lengthy captions, detailed options of pictures are matched with their lengthy descriptions.
- On the similar time, broader options are extracted from pictures that focuses on key facets.
- These broader options are then aligned with brief abstract captions.
- By doing this, the mannequin not solely learns to seize detailed attributes but additionally understands which of them are extra essential.
- This manner, the mannequin can deal with each lengthy and brief captions successfully by studying to prioritize completely different attributes.
So, we want a approach to extract these broader picture options from detailed ones and analyze their significance.
Comparability with CLIP
The mannequin is in comparison with CLIP with three downstream duties comparable to:-
1.) zero-shot picture classification
2.) short-caption image-text retrieval
3.)long-caption image-text retrieval
The beneath tables exhibits the outcomes of the comparability.
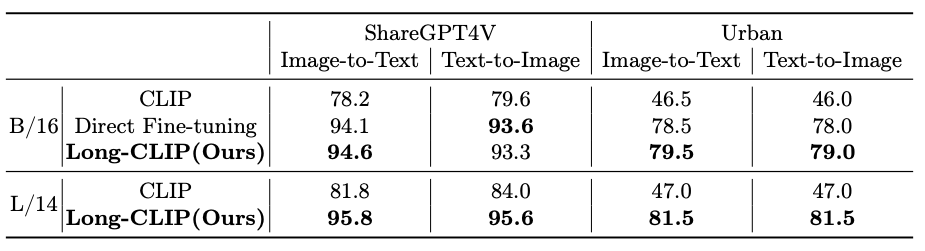
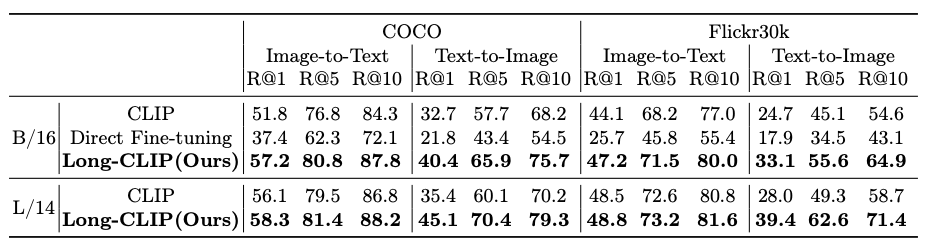
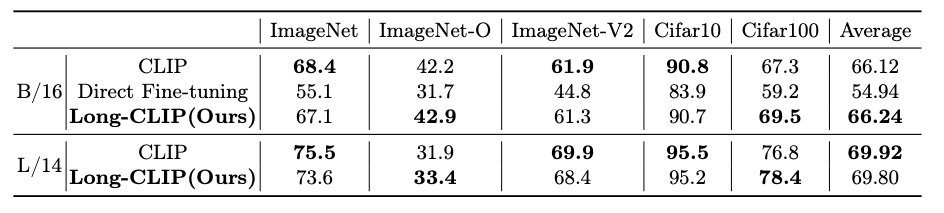
To get the detailed comparability outcomes we extremely advocate the original analysis paper.
Working with Lengthy-CLIP
Deliver this venture to life
To begin experimenting with Lengthy-CLIP, click on the hyperlink supplied with the article, this can clone the repo or comply with the steps:-
- Clone the repo and set up mandatory libraries
!git clone https://github.com/beichenzbc/Lengthy-CLIP.gitAs soon as this step is executed succesfully, transfer to the Lengthy-CLIP folder
cd Lengthy-CLIP- Import the required libraries
from mannequin import longclip
import torch
from PIL import Picture
import numpy as npObtain the checkpoints from LongCLIP-B and/or LongCLIP-L and place it below ./checkpoints
- Use the mannequin to output the expected prababilities on any picture, right here we’re utilizing the beneath picture.

system = "cuda" if torch.cuda.is_available() else "cpu"
mannequin, preprocess = longclip.load("./checkpoints/longclip-B.pt", system=system)
textual content = longclip.tokenize(["A cat jumping.", "A cat sleeping."]).to(system)
picture = preprocess(Picture.open("./img/cat.jpg")).unsqueeze(0).to(system)
with torch.no_grad():
image_features = mannequin.encode_image(picture)
text_features = mannequin.encode_text(textual content)
logits_per_image, logits_per_text = mannequin(picture, textual content)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)# Label probs: [[0.00201881 0.99798125]]The mannequin precisely conducts zero-shot classification and offers the likelihood of the picture as its output.
Conclusion
On this article, we launched Lengthy-CLIP, a robust CLIP mannequin able to dealing with longer textual content inputs as much as 248 tokens. The latest analysis exhibits that the mannequin has proven important enhancements in retrieval duties whereas sustaining efficiency in zero-shot classification. Additional, researchers claims that the mannequin can seamlessly substitute the pre-trained CLIP encoder in picture era duties. Nevertheless, it nonetheless has limitations concerning enter token size, regardless that drastically improved in comparison with earlier mannequin. By leveraging extra knowledge, notably lengthy text-image pairs, the scaling potential of Lengthy-CLIP is promising, as it might present wealthy and complicated info, enhancing its total capabilities.