
{kind=link}
Understanding the way to finetune PaliGemma utilizing Paperspace GPU is essential for builders, information scientists, and AI fanatics. This text will dive into the method, specializing in utilizing the A100-80G GPU for our job. This information will present a complete understanding of the way to finetune this imaginative and prescient mannequin.
The evolution of vision-language fashions has been outstanding. They’ve turn out to be extremely versatile from their early phases of understanding and producing pictures and textual content individually. As we speak, these fashions can describe the content material of a photograph, reply questions on a picture, and even create detailed footage from a textual content description, marking a major development within the subject.
Fantastic-tuning these fashions is essential as a result of it suits the mannequin to particular duties or datasets, enhancing their accuracy and efficiency. By coaching them on related information, they higher perceive context and nuances, which is crucial for real-world functions.
So, PaliGemma is an open-source imaginative and prescient language mannequin launched by Google. The mannequin can soak up pictures and textual content and output textual content. We’ve got already created an in depth weblog on PaliGemma, the place we explored the mannequin with numerous enter pictures, discussing its structure, coaching course of, and efficiency on completely different duties.
PaliGemma represents a major development in vision-language fashions, providing a strong instrument for understanding and producing content material based mostly on pictures.
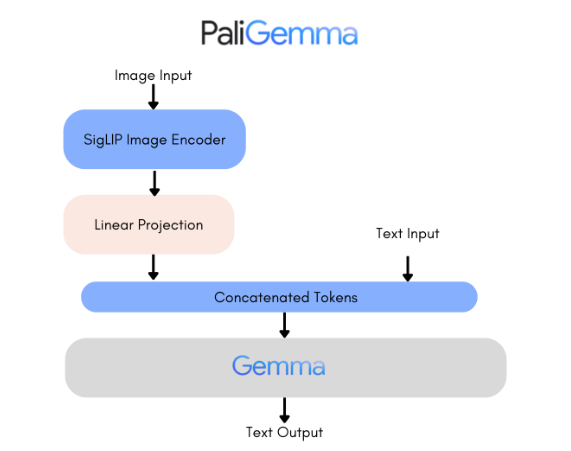
PaliGemma is a household of superior vision-language fashions. It combines SigLIP-So400m because the picture encoder and Gemma-2B because the textual content decoder. SigLIP, like CLIP, understands pictures and textual content with its joint coaching strategy. The PaliGemma mannequin, much like PaLI-3, is pre-trained on image-text information and may be fine-tuned for duties like captioning or segmentation. Gemma is explicitly designed for textual content era. By connecting SigLIP’s picture encoder to Gemma by means of a easy linear adapter, PaliGemma turns into a reliable vision-language mannequin.
Why A100-80G?
Utilizing the NVIDIA A100-80G from Paperspace for fine-tuning vision-language fashions like PaliGemma affords vital benefits. Its excessive efficiency and 80GB reminiscence capability guarantee environment friendly dealing with of enormous datasets and complicated fashions, lowering coaching occasions.
The A100 80GB debuts the world’s quickest reminiscence bandwidth at over 2 terabytes per second (TB/s) to run the biggest fashions and datasets—NVIDIA.
AI fashions have gotten extra advanced, particularly conversational AI, demanding vital computing energy and scalability. NVIDIA A100 Tensor Cores with Tensor Float (TF32) provide as much as 20 occasions larger efficiency than earlier fashions like NVIDIA Volta.
The NVIDIA A100-80G GPU out there on Paperspace represents a cutting-edge resolution for intensive computing duties, notably in AI and machine studying. With its 80GB of reminiscence and Tensor Cores optimized for AI workloads, the A100-80G delivers distinctive efficiency and scalability—Paperspace’s cloud infrastructure leverages these capabilities, providing customers versatile entry to high-performance computing assets.
This mix permits researchers, builders, and information scientists to sort out advanced AI fashions and large-scale information processing duties effectively, accelerating innovation and lowering time to options in numerous fields.
Finetuning the Imaginative and prescient Language Mannequin
Convey this undertaking to life
Set up the Packages
We are going to first set up all the most recent variations of the required packages required for fine-tuning.
# Set up the required packages
!pip set up -q -U speed up bitsandbytes git+https://github.com/huggingface/transformers.git
!pip set up datasets -q
!pip set up peft -qEntry Token
As soon as the 1st step is efficiently executed, we are going to export the cuddling face entry token.
from huggingface_hub import login
login("hf_yOuRtoKenGOeSHerE")
Import Libraries
Subsequent, we are going to import all the required libraries.
import os
from datasets import load_dataset, load_from_disk
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration, BitsAndBytesConfig, TrainingArguments, Coach
import torch
from peft import get_peft_model, LoraConfigLoad Information
Let’s load the dataset! We are going to make the most of the visible question-and-answer dataset from Hugging Face for the mannequin finetuning. Additionally, we’re solely contemplating a small chunk of the information for this tutorial, however please be happy to vary this.
ds = load_dataset('HuggingFaceM4/VQAv2', break up="practice[:10%]") For the preprocessing steps, we are going to take away a number of columns from the information that aren’t required. As soon as executed, we are going to break up the information for coaching and validation.
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]{'multiple_choice_answer': 'sure', 'query': 'Is the aircraft at cruising altitude?', 'picture': <PIL.JpegImagePlugin.JpegImageFile picture mode=RGB dimension=640x480 at 0x7FC3DFEDB110>}Load Processor
Load the processor containing the picture processing and tokenization half and preprocess our dataset.
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor.from_pretrained(model_id)
There are completely different variations of the mannequin comparable to paligemma-3b-pt-224, paligemma-3b-pt-448, and paligemma-3b-pt-896. In our case, we are going to use the 224×224 model because the high-resolution fashions (448×448, 896×896) require considerably extra reminiscence. Nevertheless, these fashions are helpful for extra accuracy and fine-grained duties like OCR. However the 224×224 variations are appropriate for many functions.
Set the machine to ‘cuda’ to make use of the GPU and cargo the mannequin. We are going to Specify that the mannequin ought to use bfloat16 (Mind Float 16) precision for its parameters. bfloat16 is a 16-bit floating level format that helps pace up computation and reduces reminiscence utilization whereas sustaining the same vary to float32.
machine = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<picture>")
mannequin = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(machine)
Mannequin Coaching
The next steps are used to arrange the mannequin for conditional era, particularly configuring which elements of the mannequin ought to be trainable and stay mounted (frozen).
We are going to set the requires_grad attribute of every parameter to False, indicating that these parameters shouldn’t be up to date throughout backpropagation. This successfully “freezes” the imaginative and prescient tower, stopping its weights from being modified throughout coaching. This assumes that the picture encoder has already discovered helpful normal options from a big dataset.
Moreover, we are going to set the requires_grad attribute of every parameter to True, guaranteeing that these parameters shall be up to date throughout backpropagation. This makes the multi-modal projector trainable, permitting its weights to be optimized throughout coaching.
We are going to load the mannequin, and freeze the picture encoder and the projector, and solely fine-tune the decoder. In case your pictures are inside a specific area, which could not be within the dataset the mannequin was pre-trained with, you would possibly need to skip freezing the picture encoder—Hugging Face Weblog.
# Freeze Imaginative and prescient Tower Parameters (Picture Encoder)
for param in mannequin.vision_tower.parameters():
param.requires_grad = False
# Allow Coaching for Multi-Modal Projector Parameters (Fantastic-Tuning the Decoder)
for param in mannequin.multi_modal_projector.parameters():
param.requires_grad = TrueWhy Freeze the Picture Encoder and Projector?
- Normal Options: The picture encoder (imaginative and prescient tower) has sometimes been pre-trained on a big and various dataset (e.g., ImageNet). It has discovered to extract normal options helpful for a variety of pictures.
- Pre-Skilled Integration: The multi-modal projector has additionally been pre-trained to combine options from completely different modalities successfully. It’s anticipated to carry out properly with out additional fine-tuning.
- Useful resource Effectivity: Freezing these elements of the mannequin reduces the variety of trainable parameters, making the coaching course of sooner and requiring much less computational assets.
Why Fantastic-Tune the Decoder?
- Activity Specificity: The decoder should be fine-tuned for the precise job. Fantastic-tuning permits it to learn to generate the suitable output based mostly on the actual kinds of enter it should obtain in your software.
Outline a ‘collate_fn’ operate. The operate returns the ultimate batch of tokens containing the tokenized textual content, pictures, and labels, all transformed to the suitable format and moved to the proper machine for environment friendly computation.
def collate_fn(examples):
texts = ["answer " + example["question"] for instance in examples]
labels= [example['multiple_choice_answer'] for instance in examples]
pictures = [example["image"].convert("RGB") for instance in examples]
tokens = processor(textual content=texts, pictures=pictures, suffix=labels,
return_tensors="pt", padding="longest")
tokens = tokens.to(torch.bfloat16).to(machine)
return tokensThe Quantized Mannequin
Load the mannequin in 4-bit for QLoRA. This may cut back reminiscence utilization and pace up inference and coaching whereas sustaining efficiency.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
mannequin = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
mannequin = get_peft_model(mannequin, lora_config)
mannequin.print_trainable_parameters()trainable params: 11,298,816 || all params: 2,934,765,296 || trainable%: 0.3849989644964099
Configure Optimizer
We are going to now configure the optimizer, variety of epochs, studying fee, and so forth., for coaching. These settings are adjustable as wanted.
args=TrainingArguments(
num_train_epochs=2,
remove_unused_columns=False,
output_dir="output",
logging_dir="logs",
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)Lastly, we are going to start the coaching by initializing the coach. Cross the coaching dataset, information collating operate (collate_fn), and the coaching arguments outlined within the earlier step. Then, name the practice operate to start out the coaching.
coach = Coach(
mannequin=mannequin,
train_dataset=train_ds,
# eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
coach.practice()
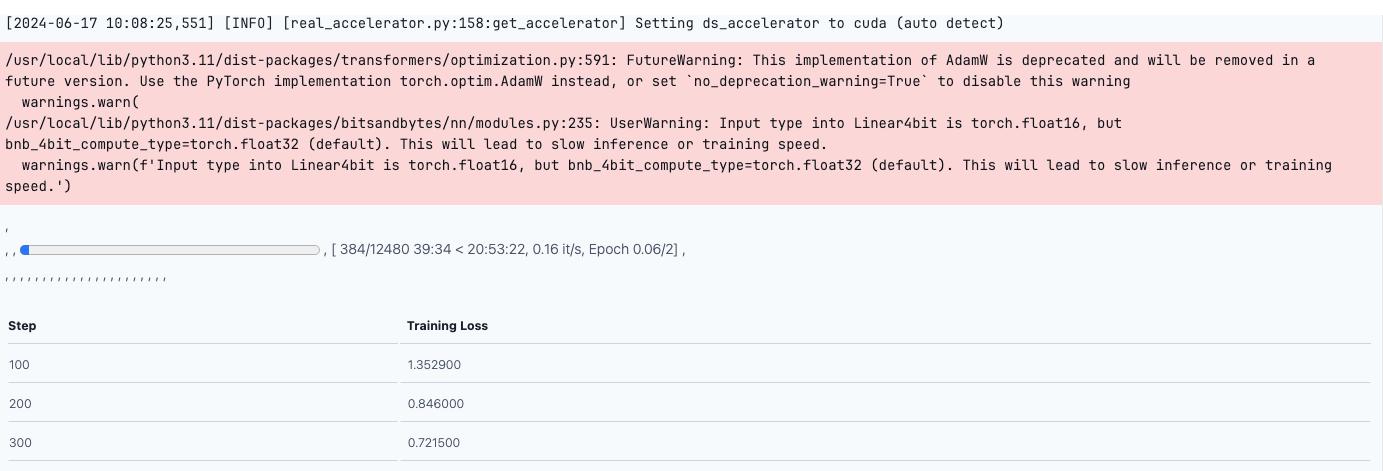
This may begin the coaching, and the coaching loss will lower with each epoch. As soon as the mannequin is prepared, we will add it to Hugging Face for inferencing.
# Save the mannequin in HuggingFace
coach.push_to_hub('shaoni/paligemma_VQAv2')And you’ve got efficiently fine-tuned a VLM!!
Convey this undertaking to life
Conclusion
The mannequin PaliGemma exhibits unimaginable developments in vision-language fashions. The mannequin demonstrates the potential of AI in understanding and interacting with visible information. PaliGemma’s potential to precisely determine object areas and segmentation masks in pictures highlights its versatility and energy. Fantastic-tuning PaliGemma utilizing a customized dataset can improve the mannequin’s efficiency for particular duties, guaranteeing larger accuracy and relevance in real-world functions.
Imaginative and prescient-language fashions (VLMs) have quite a few real-world functions which are remodeling numerous industries. In healthcare, they’ll help medical doctors by analyzing medical pictures and offering detailed descriptions, aiding in sooner and extra correct diagnoses. In e-commerce, VLMs improve the purchasing expertise by permitting customers to seek for merchandise utilizing pictures or generate detailed descriptions of things. These fashions create interactive studying supplies for training that mix visible and textual data, making advanced ideas simpler to grasp. Moreover, VLMs enhance accessibility by describing visible content material to visually impaired people, serving to them navigate their environments extra successfully.
These functions showcase the potential of VLMs to make expertise extra intuitive, accessible, and impactful in our each day lives.