
{kind=link}

Introduction
IDEFICS (Picture-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access model of Deepmind‘s visible language mannequin, Flamingo. It processes sequences of photographs and textual content, producing textual content outputs, and might reply questions on photographs, describe visible content material, and create tales primarily based on photographs.
Constructed with publicly accessible knowledge and fashions, IDEFICS matches the unique Flamingo on varied benchmarks like visible query answering, picture captioning, and picture classification. Obtainable in two sizes, 80 billion and 9 billion parameters, it additionally is available in fine-tuned variations, idefics-80b-instruct and idefics-9b-instruct, which improve efficiency and value in conversational contexts.
Key distinction between IDEFICS1 and IDEFICS2
- Idefics2 surpasses Idefics1 with 8 billion parameters and the flexibleness of an Apache 2.0 open license.
- The pictures are manipulated at their native resolutions (as much as 980 x 980) and side ratios utilizing the NaViT technique, avoiding the necessity to resize them to fastened squares. Moreover, extra superior strategies from SPHINX are integrated to permit sub-image splitting and processing of high-resolution photographs.
- The OCR capabilities have been significantly enhanced with knowledge for transcribing textual content from photographs and paperwork. Additionally, the mannequin’s skill to reply questions on charts, figures, and paperwork has improved in IDEFICS2.
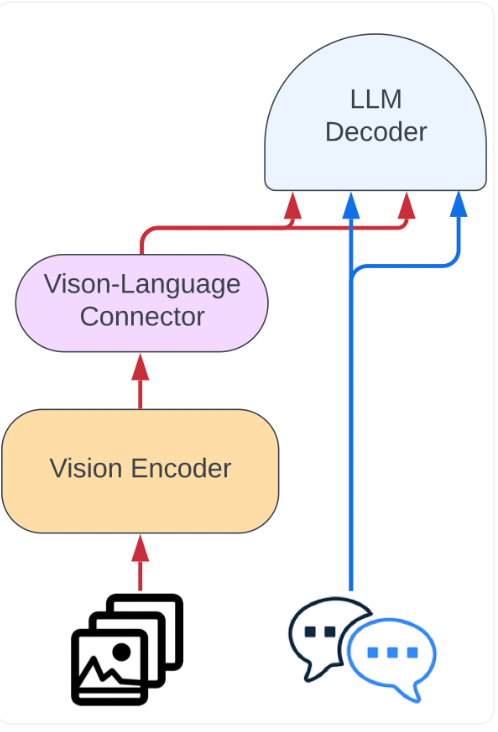
- Not like Idefics1, the structure is simplified by feeding photographs to the imaginative and prescient encoder, adopted by Perceiver pooling and an MLP modality projection. This pooled sequence is mixed with textual content embeddings to seamlessly combine photographs and textual content.
These enhancements and higher pre-trained backbones end in a big efficiency increase over Idefics1, regardless that the brand new mannequin is 10 occasions smaller.
On this article, we’ll use Paperspace, a cloud computing platform that provides a variety of highly effective GPUs designed to deal with intensive computational duties resembling machine studying, deep studying, and high-performance computing.
The GPUs supplied by Paperspace allow researchers and builders to effectively scale their fashions effectively, making certain quicker coaching occasions and extra correct outcomes. With Paperspace, customers can seamlessly entry these high-powered GPUs within the cloud, offering the flexibleness and scalability wanted for demanding computational duties.
Picture duties with IDEFICS
Whereas specialised fashions might be fine-tuned for particular duties, this new and standard method makes use of massive fashions to deal with various duties with out fine-tuning. Giant language fashions, for instance, can carry out summarization, translation, and classification. This technique now extends past textual content to multimodal duties.
On this article, we’ll present you find out how to use the IDEFICS mannequin for image-text duties.
IDEFICS processes sequences of photographs and textual content to generate coherent textual content outputs, resembling answering questions on photographs, describing visible content material, and creating tales from a number of photographs. IDEFICS is available in two variations: 80 billion and 9 billion parameters, with fine-tuned variations for conversational use.
Paperspace Demo
Convey this mission to life
This mannequin’s distinctive versatility permits it to deal with varied picture and multimodal duties. Nonetheless, its massive measurement necessitates substantial computational sources and infrastructure.
On this demo, we’ll use the mannequin to reply visible questions.
Allow us to begin by putting in the mandatory packages and loading the mannequin’s 9 billion parameters mannequin checkpoint:
%pip set up -U transformers
datasets==2.14.4
diffusers==0.20.0
speed up==0.21.0
torch==2.0.1
torchvision==0.15.2
sentencepiece==0.1.99As soon as the set up is completed, we’ll transfer to the subsequent steps to arrange the mannequin and processor for performing vision-text duties utilizing the IdeficsForVisionText2Text mannequin from Hugging Face.
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
system = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "HuggingFaceM4/idefics-9b-instruct"
mannequin = IdeficsForVisionText2Text.from_pretrained(model_name, torch_dtype=torch.bfloat16).to(system)
processor = AutoProcessor.from_pretrained(model_name)
# Era args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
We’ll set the info kind for the mannequin to bfloat16, a lower-precision format to save lots of reminiscence and doubtlessly enhance pace.
Subsequent, we’ll use a picture for our job,
from PIL import Picture
img = Picture.open("canine.jpg")
img
immediate = [
"User:",
img,
"Describe this image."
"Assistant:",
]
inputs = processor(immediate, return_tensors="pt").to("cuda")
generated_ids = mannequin.generate(**inputs, eos_token_id = exit_condition, max_new_tokens=100, bad_words_ids=bad_words_ids)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
Output:-
‘Consumer: Describe this picture. Assistant: The picture reveals two golden retriever puppies sitting in a area of flowers. They’re sitting subsequent to one another, trying on the digital camera, and seem like very completely satisfied. The puppies are lovely, and their fur is a fantastic golden colour. The flowers surrounding them are yellow and add a vibrant contact to the scene.’
It’s a good suggestion to incorporate the bad_words_ids within the name to generate to keep away from errors arising when rising the max_new_tokens: the mannequin will need to generate a brand new
or <fake_token_around_image> token when there isn’t any picture being generated by the mannequin. You possibly can set it on-the-fly as on this information, or retailer within the GenerationConfig as described within the Textual content technology methods information. -Supply Hugging Face
IDEFICS Coaching Information
Idefics2 was skilled on a mixture of publicly accessible datasets, together with net paperwork (like Wikipedia and OBELICS), image-caption pairs (from LAION-COCO), OCR knowledge, and image-to-code knowledge.
To boost the bottom mannequin, the mannequin is additional skilled on task-oriented knowledge, which is usually scattered and in varied codecs, posing a problem for the group.
Conclusion
On this article we explored IDEFICS2, a flexible multimodal mannequin that handles sequences of textual content and pictures, producing textual content responses. It will possibly reply image-related questions and describe visuals.
Idefics2 is a serious improve from Idefics1, boasting 8 billion parameters, an Apache 2.0 open license. It is a highly effective instrument for these engaged on multimodal tasks. With Idefics2 already built-in into Transformers, it is simple to fine-tune for varied multimodal functions. You possibly can strive it out with Paperspace at the moment!
We explored the mannequin efficiency with visible query answering, and the mannequin carried out fairly decently.
We hope you loved studying the article and exploring the mannequin additional with Paperspace.
References
To additional perceive the mannequin, we now have supplied the sources beneath:-