{kind=link}
Introduction
The GPU reminiscence hierarchy is more and more turning into an space of curiosity for deep studying researchers and practitioners alike. By constructing an instinct round reminiscence hierarchy, builders can decrease reminiscence entry latency, maximize reminiscence bandwidth, and cut back energy consumption resulting in shorter processing instances, accelerated information switch, and cost-effective compute utilization. An intensive understanding of reminiscence structure will allow builders to attain peak GPU capabilities at scale.
Paperspace by DigitalOcean provides GPU-powered digital machines and Jupyter IDE notebooks for coaching and working complicated fashions.
CUDA Refresher
CUDA (Compute Unified System Structure) is a parallel computing platform developed by NVIDIA for configuring GPUs.
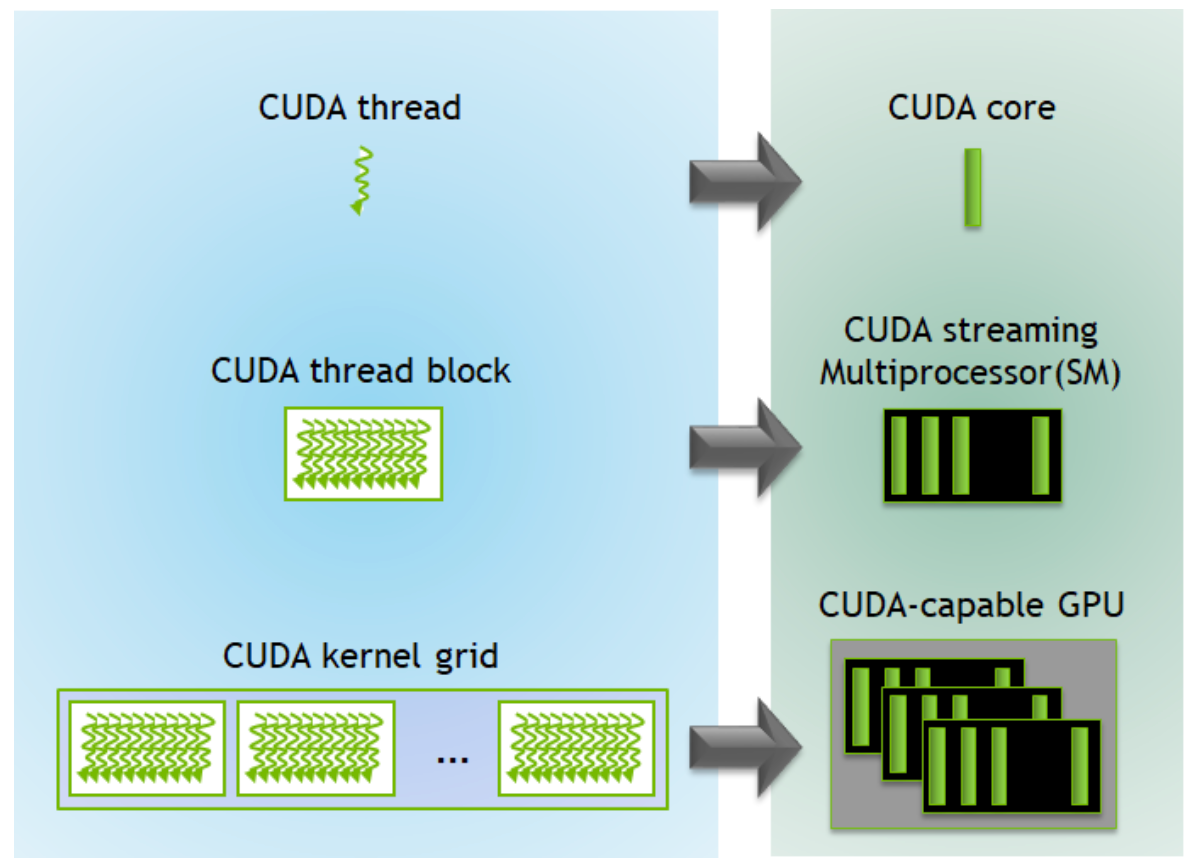
The execution of a CUDA program begins when the host code (CPU serial code) calls a kernel operate. This operate name launches a grid of threads on a tool (GPU) to course of completely different information elements in parallel.
A thread is comprised of this system’s code, the present execution level within the code, in addition to the values of its variables and information buildings. A bunch of threads kind a thread block and a gaggle of thread blocks compose the CUDA kernel grid. The software program elements, threads and thread blocks, correspond on to their {hardware} analogs, the CUDA core and the CUDA Streaming Multiprocessor (SM).
All collectively, these make up the constituent components of the GPU.
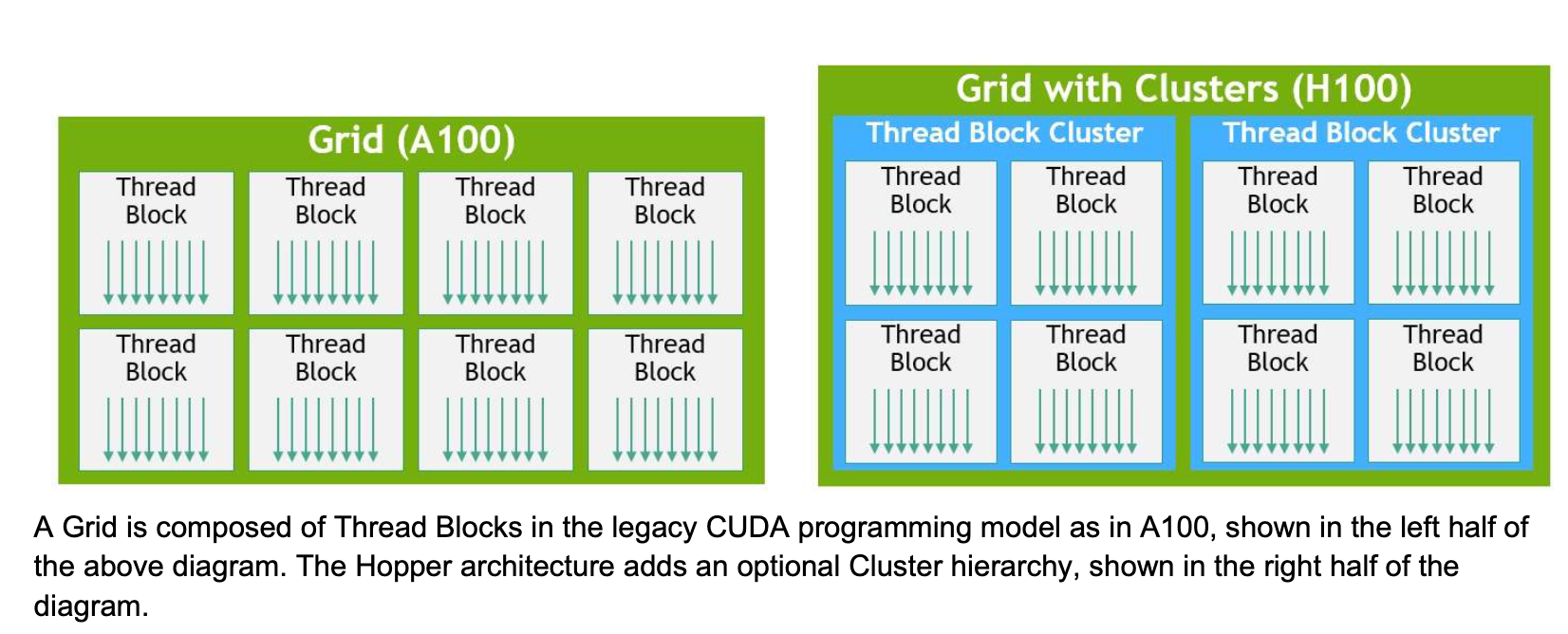
H100s introduce a brand new Thread Block Cluster structure, extending GPU’s bodily programming structure to now embody Threads, Thread Blocks, Thread Block Clusters, and Grids.
CUDA Reminiscence Sorts
There are various levels of accessibility and length for reminiscence storage sorts utilized by a CUDA gadget. When a CUDA programmer assigns a variable to a particular CUDA reminiscence sort, they dictate how the variable is accessed, the velocity at which it is accessed, and the extent of its visibility.
Here is a fast overview of the completely different reminiscence sorts:
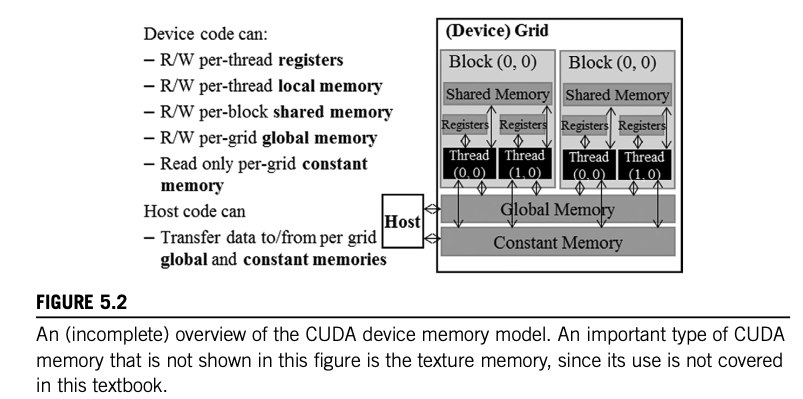
Register reminiscence is personal to every thread. Because of this when that individual thread ends, the information for that register is misplaced.
Native reminiscence can also be personal to every thread, nevertheless it’s slower than register reminiscence.
Shared reminiscence is accessible to all threads in the identical block and lasts for the block’s lifetime.
World reminiscence holds information that lasts throughout the grid/host. All threads and the host have entry to international reminiscence.
Fixed reminiscence is read-only and designed for information that doesn’t change throughout the kernel’s execution.
Texture reminiscence is one other read-only reminiscence sort superb for bodily adjoining information entry. Its use can mitigate reminiscence visitors and improve efficiency in comparison with international reminiscence.
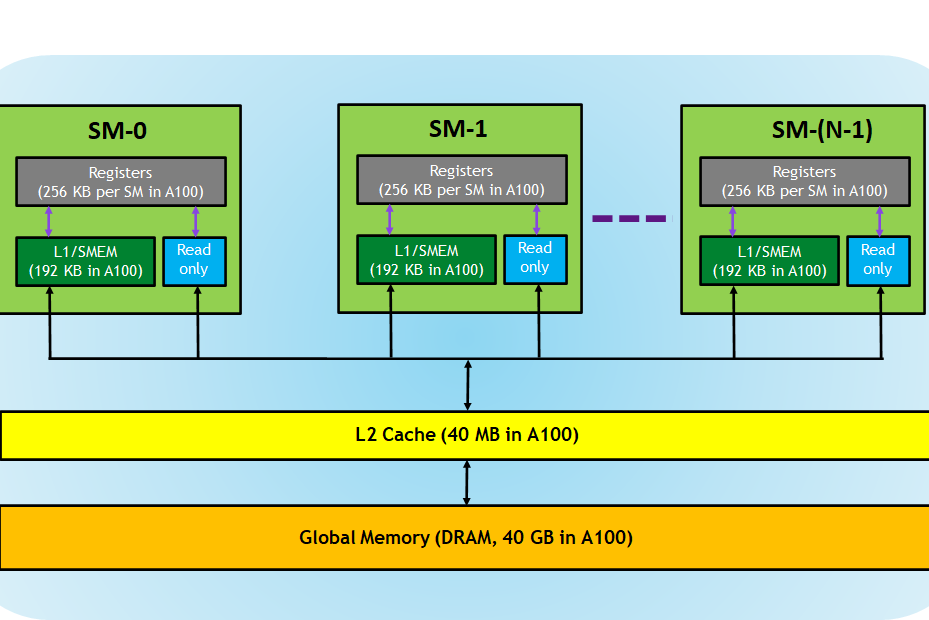
GPU Reminiscence Hierarchy
The Pace-Capability Tradeoff
You will need to perceive that with respect to reminiscence entry effectivity, there may be a tradeoff between bandwidth and reminiscence capability. Larger velocity is correlated with decrease capability.
Registers
Registers are the quickest reminiscence elements on a GPU, comprising the register file that provides information immediately into the CUDA cores. A kernel operate makes use of registers to retailer variables personal to the thread and accessed incessantly.
Each registers and shared reminiscence are on-chip reminiscences the place variables residing in these reminiscences could be accessed at very excessive speeds in a parallel method.
By leveraging registers successfully, information reuse could be maximized and efficiency could be optimized.
Cache Ranges
A number of ranges of caches exist in fashionable processors. The space to the processor is mirrored in the best way these caches are numbered.
L1 Cache
L1 or stage 1 cache is hooked up to the processor core immediately. It features as a backup storage space when the quantity of lively information exceeds the capability of a SM’s register file.
L2 Cache
L2 or stage 2 cache is bigger and infrequently shared throughout SMs. Not like the L1 cache(s), there is just one L2 cache.
Fixed Cache
Fixed cache captures incessantly used variables for every kernel resulting in improved efficiency.
When designing reminiscence techniques for massively parallel processors, there can be fixed reminiscence variables. Rewriting these variables can be redundant and pointless. Thus, a specialised reminiscence system just like the fixed cache eliminates the necessity for computationally pricey {hardware} logic.
New Reminiscence Options with H100s

Hopper, by its H100 line of GPUs, launched new options to reinforce its efficiency in comparison with earlier NVIDIA micro-architectures.
Thread Block Clusters
As talked about earlier within the article, Thread Block Clusters debuted with H100s, increasing the CUDA programming hierarchy. A Thread Block Cluster permits for better programmatic management for a bigger group of threads than permissible by a Thread Block on a single SM.
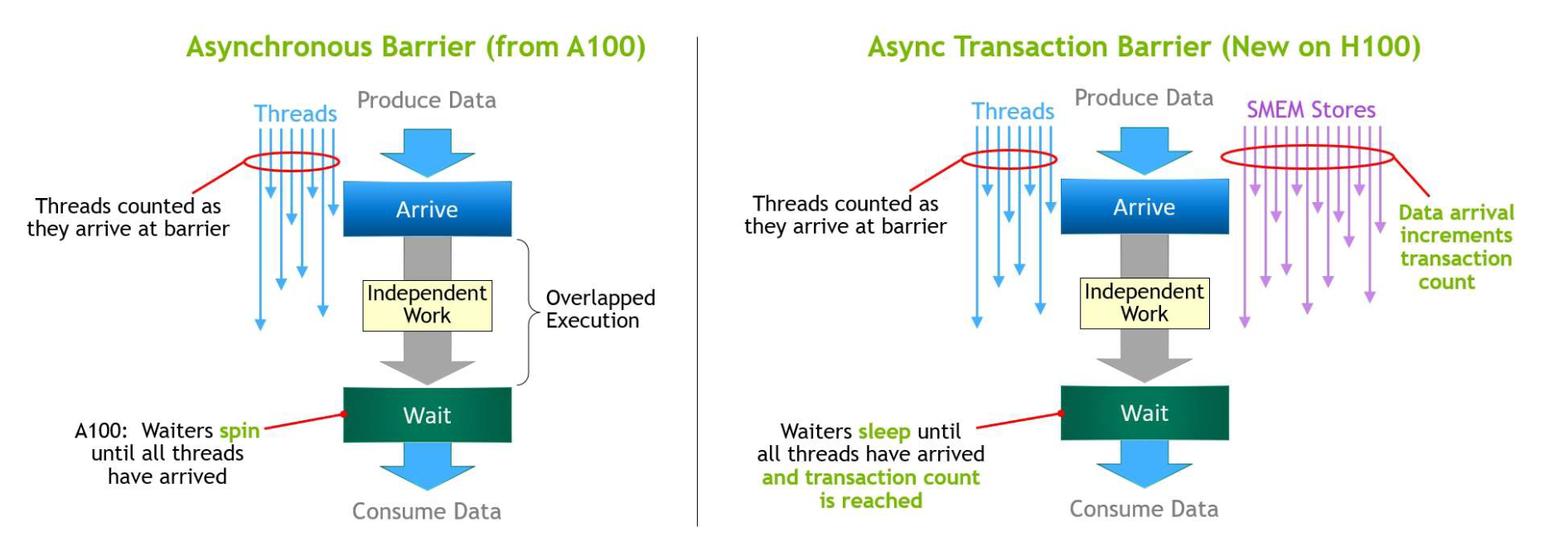
Asynchronous Execution
The most recent developments in asynchronous execution introduce a Tensor Reminiscence Accelerator (TMA) and an Asynchronous Transaction Barrier into the Hopper structure.
The Tensor Reminiscence Accelerator (TMA) unit permits for the environment friendly information switch of enormous blocks between international and shared reminiscence.
The Asynchronous Transaction Barrier permits for synchronization of CUDA threads and on-chip accelerators, no matter whether or not they’re bodily positioned on separate SMs.
Conclusion
Assigning variables to particular CUDA reminiscence sorts permits a programmer to train exact management over its behaviour. This designation not solely determines how the variable is accessed, but additionally the velocity at which this entry happens. Variables saved in reminiscence sorts with quicker entry instances, reminiscent of registers or shared reminiscence, could be rapidly retrieved, accelerating computation. In distinction, variables in slower reminiscence sorts, reminiscent of international reminiscence, are accessed at a slower charge. Moreover, reminiscence sort project influences scope of the variable’s utilization and interplay with different threads; its assigned reminiscence sort governs whether or not the variable is accessible to a single thread, a block of threads or all threads inside a grid. Lastly, H100s, the present SOTA GPU for AI workflows, launched a number of new options that affect reminiscence entry reminiscent of Thread Block Clusters, the Tensor Reminiscence Accelerator (TMA) unit, and Asynchronous Transaction Obstacles.
References
Programming Massively Parallel Processors (4th version)
NVIDIA H100 Tensor Core GPU Structure Overview
A high-level overview of NVIDIA H100, new H100-based DGX, DGX SuperPOD, and HGX techniques, and a H100-based Converged Accelerator. That is adopted by a deep dive into the H100 {hardware} structure, effectivity enhancements, and new programming options.

CUDA Refresher: The CUDA Programming Mannequin | NVIDIA Technical Weblog
That is the fourth publish within the CUDA Refresher sequence, which has the aim of refreshing key ideas in CUDA, instruments, and optimization for starting or intermediate builders.