
{kind=link}
Carry this mission to life
Information is more and more turning into a premium for everybody on the web, and turning data into information is turning into ever more and more important for all types of enterprise issues. Whereas information is obtained often from web sites corresponding to Kaggle.com and numerous sources by net scraping on web sites, this information steadily comprises lacking information. Nonetheless, can that information be used to assemble machine-learning algorithms?
The reply is NO. It is because the information is uncooked and unprocessed. So, information preprocessing is required right here earlier than constructing the mannequin. Information preprocessing contains dealing with lacking information and changing categorical information to numerical information utilizing strategies like One-hot encoding.
This text will discover various kinds of lacking information and examine the explanations behind lacking values and their implications on information evaluation. Moreover, we are going to talk about completely different strategies to deal with lacking values.
So, let’s discover tips on how to deal with them effectively in machine studying.
What are lacking values? Why do they exist?
Information that’s not current in a dataset.
Lacking values are lacking data in a dataset. It’s just like the lacking piece in a zigzag puzzle, leaving gaps within the panorama. In the identical method, lacking values in information end in incomplete data. This makes it difficult to know or precisely analyze the information and, consequently, leads to inaccurate outcomes or could result in overfitting.
In datasets, these lacking entries would possibly seem because the letter “0”, “NA”, “NaN”, “NULL”, “Not Relevant”, or “None”.
However you may deal with these lacking values simply with the strategies defined beneath. The subsequent query is, why are lacking values within the information?
Lacking values can happen resulting from numerous components like
- Failure to report information,
- Information corruption,
- Lack of awareness as some folks have hesitation in sharing the data,
- System or tools failures,
- Intentional omission.
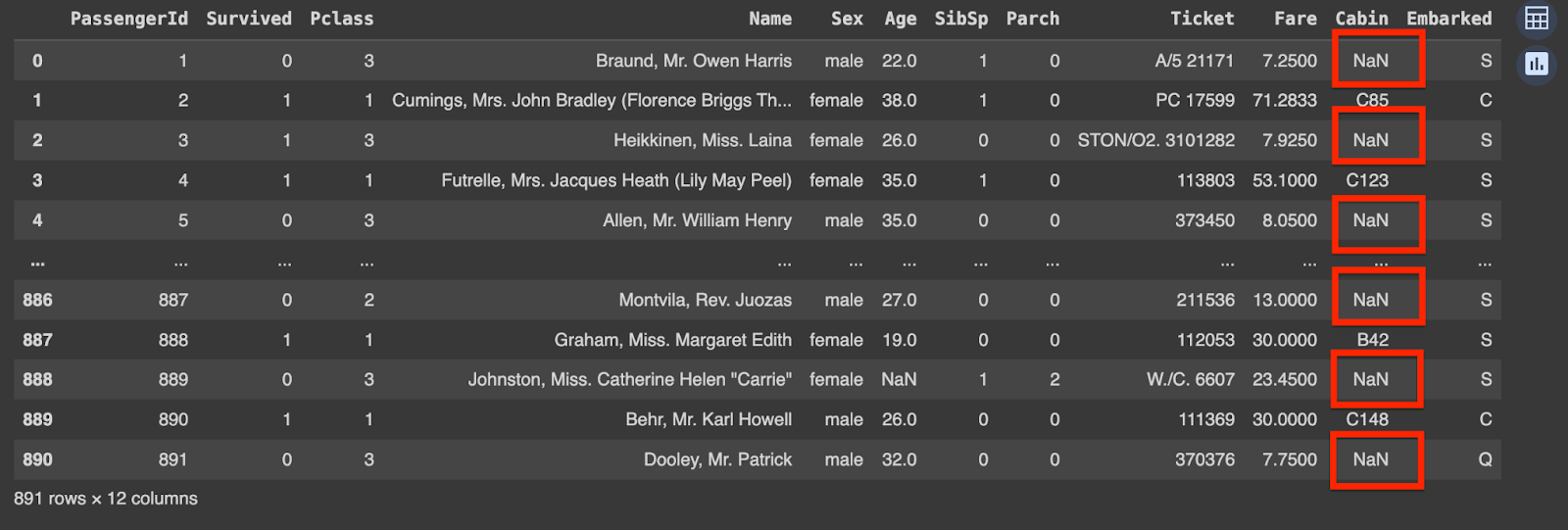
You may see that there are lacking values within the ‘Cabin’ column. Lacking values are represented by ‘NaN’ right here.
Completely different Forms of Lacking Information
1) MCAR – “utterly randomly lacking”
This happens when all variables and observations are lacking with equal likelihood. As an example, a survey’s responses are lacking resulting from technical glitches corresponding to a pc malfunction. Eradicating MCAR information is secure because it doesn’t introduce bias into the evaluation.
2) MAR – “I missed it accidentally”
In MAR, the likelihood of lacking worth is dependent upon the worth of the variable or different variables within the information set. Because of this not all variables and observations have the identical likelihood of being lacking. As an example, if information scientists do not improve their expertise steadily and skip sure questions as a result of they lack data of cutting-edge algorithms and applied sciences. On this case, the lacking information pertains to how typically information scientists proceed their coaching.
3) MNAR – “I didn’t lose it accidentally”
MNAR is taken into account probably the most tough situation among the many three forms of lacking information. On this case, the explanations for lacking information could also be unknown. An instance of MNAR is a survey of married {couples}. {Couples} with unhealthy relationships could not need to reply sure questions as a result of they’re embarrassed to take action.
Strategies to Deal with Lacking Values
We are going to talk about three major strategies:
1. Deleting Rows with Lacking Values
The best and best strategy to deal with lacking values is to take away the rows or columns containing lacking values within the dataset. The query that involves thoughts is whether or not we are going to lose data if we delete the information. The reply is YES. Eradicating too many observations can reduce the statistical energy of the evaluation and result in biased outcomes.
When to make use of this system:
- You may delete the whole column if a selected column is lacking many values.
- If in case you have an enormous dataset. Then, eradicating 2-3 rows/columns will not make a lot distinction.
- The output outcomes don’t depend upon deleted information.
- Low variability in information or repetitive values.
- When datasets have extremely skewed distributions, eradicating rows with lacking values would be the most suitable option in comparison with imputation.
Be aware: This strategy needs to be used within the above eventualities solely and isn’t really helpful a lot.
Let’s check out an instance of deletion utilizing Python:
information.dropna(inplace=True)dropna(how = ‘all’) #the rows the place all of the column values are lacking.
2. Imputation Strategies
Substituting affordable estimates or guesses for lacking values.
Imputation strategies are significantly helpful when:
- The share of lacking information is low.
- Deleting rows would end in a major lack of data.
Let’s discover a few of the generally used imputation strategies:
Imply, Median, or Mode Imputation
This strategy replaces the lacking values with the imply, median, or mode of the non-missing values within the respective variable.
- Imply: It’s the common worth.
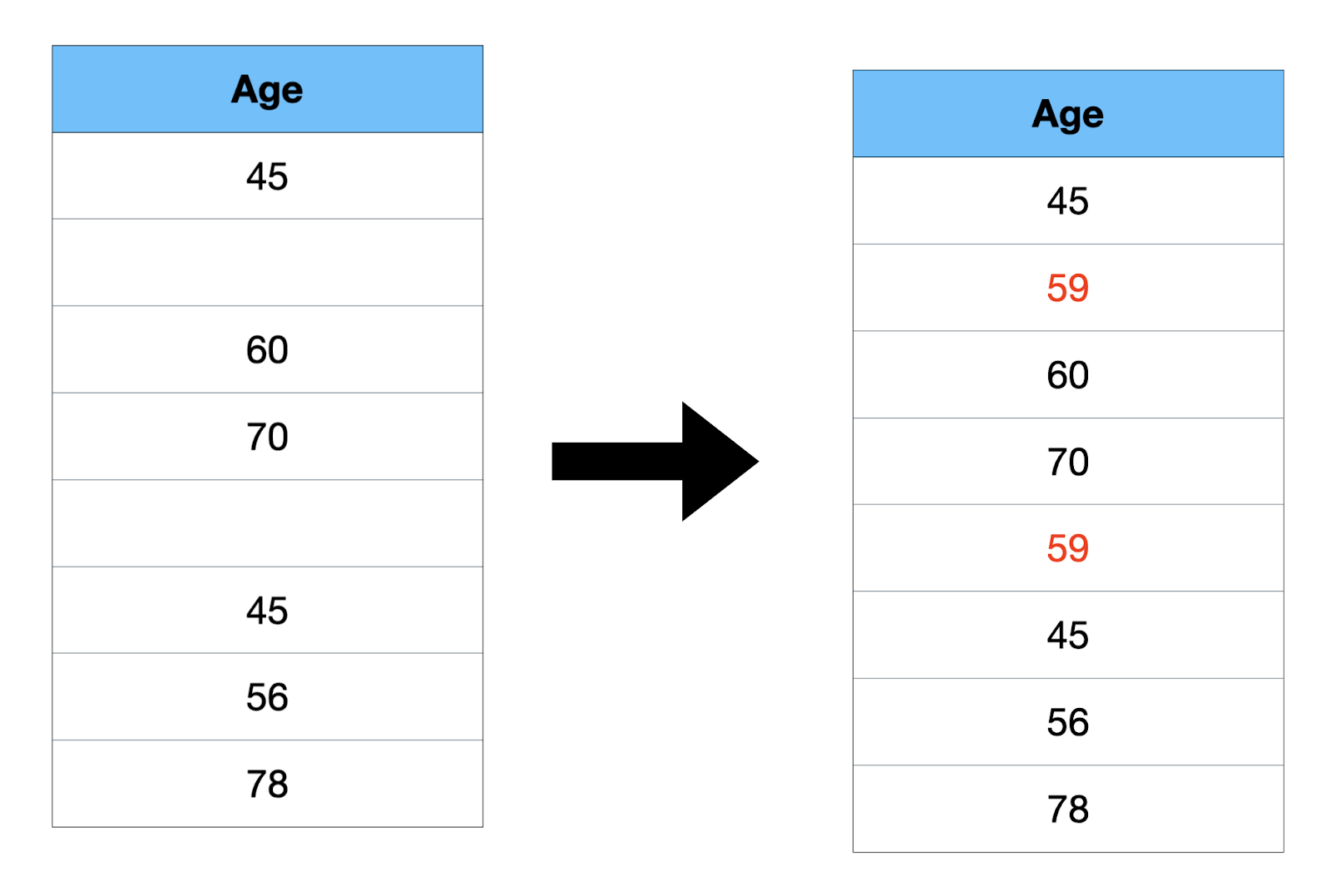
Imply = (Sum of all values) / Variety of values= 354/6
💡
Outliers would disproportionately affect the common, resulting in a probably deceptive illustration. Don’t use this system if outliers are current within the information.
- Median: It’s the midpoint worth.
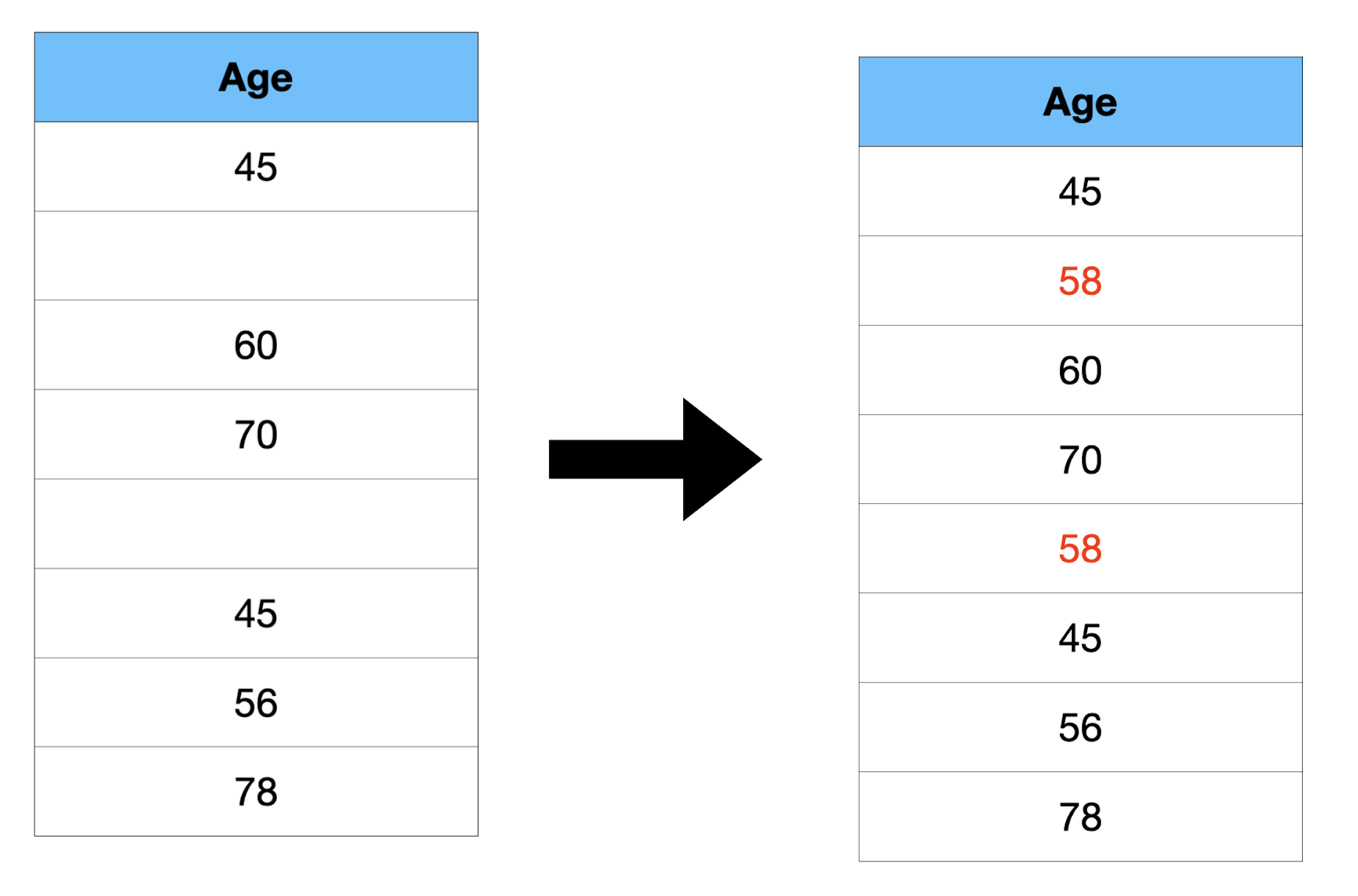
Organize all of the numbers in ascending order: 45, 45, 56, 60, 70, 78. The median is calculated as (56 + 60) / 2 = 116 / 2 = 58. If the variety of information factors is even, the median is the common of the 2 center numbers.
💡
If the dataset comprises outliers, this system is appropriate, as the center worth from the information is picked to get replaced and unaffected by outliers.
- Mode: It’s the most typical worth within the information.
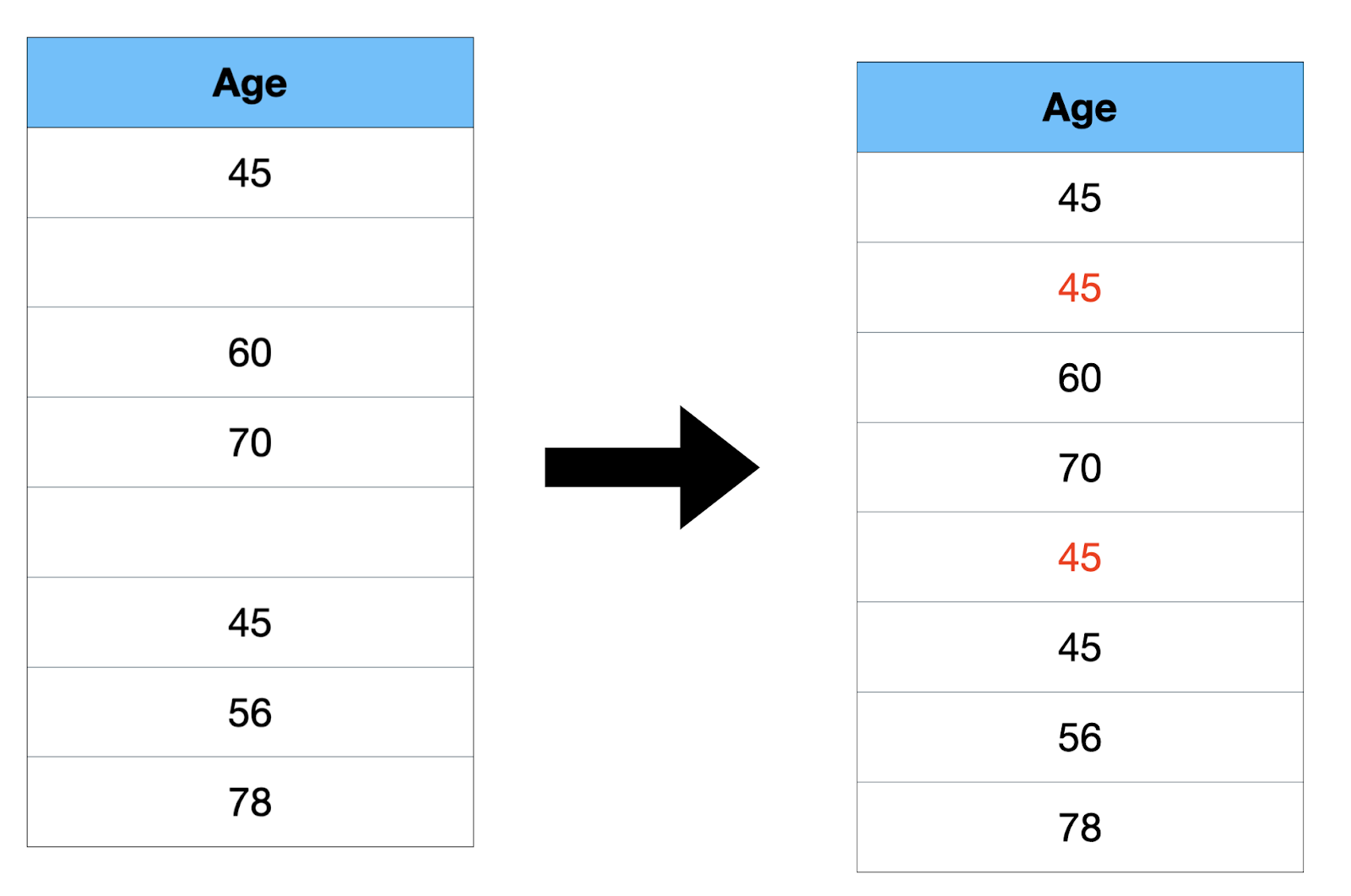
Right here, 45 is repeated twice, so the mode worth is 45.
💡
Appropriate for changing lacking values in categorical variables.
Utilizing Python, we are able to impute lacking values with the imply or median as follows:
# Importing the required libraries
import pandas as pd
from sklearn.impute import SimpleImputer
# Loading the dataset
information = pd.read_csv('dataset.csv')
# Imputing lacking values with imply
imputer = SimpleImputer(technique='imply')
information['column_name'] = imputer.fit_transform(information[['column_name']])```Within the above instance, the SimpleImputer class is used from the Scikit-learn library to impute lacking values with the imply. The technique parameter might be set to ‘imply’, ‘median’, or ‘most_frequent’. The fit_transform() perform replaces lacking values with imputed ones.
3. Ahead Fill and Backward Fill
Ahead fill (ffill) and backward fill (bfill) are imputation strategies that use the values from earlier or subsequent observations to fill within the lacking values.
Ahead Fill
Ahead fill replaces lacking values with the earlier non-missing worth. As an example, if there are lacking values within the inventory dataset for a weekend, you may ahead fill the lacking values with the final noticed worth from Friday.
Let’s perceive with an instance.
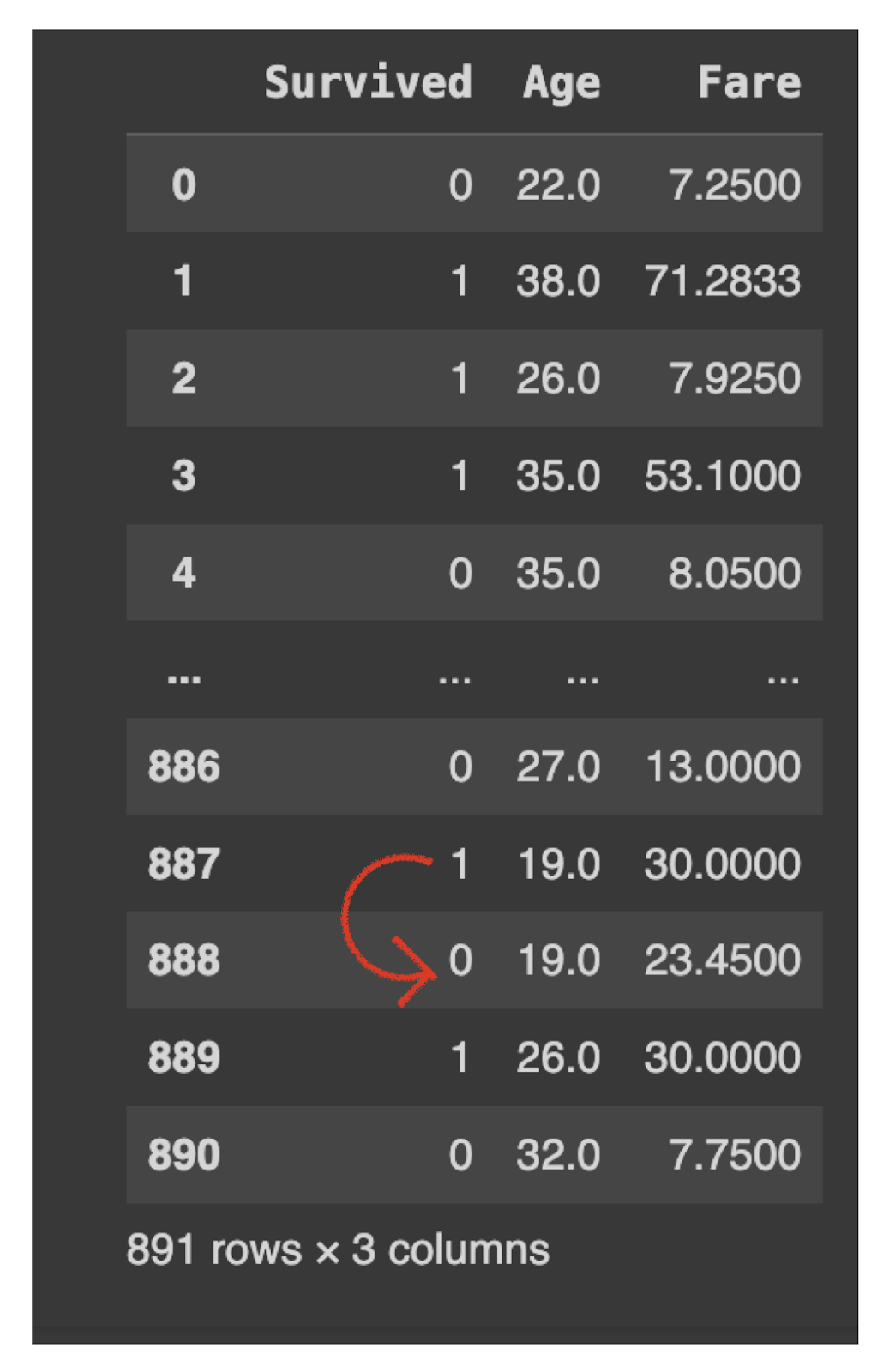
On this row, 888 had a lacking worth for the ‘Age’ column. So after working information[‘column_name’].fillna(technique=’ffill’, inplace=True). So, the worth ‘19’(earlier worth) is copied rather than the lacking cell beneath.
Backward Fill
Backward fill replaces lacking values with the following obtainable non-missing worth. As an example, if there are lacking values in a temperature dataset, the following recorded worth shall be appropriate and is taken into account the higher estimate for the lacking interval, particularly if the temperature is steady or modifications predictably.
Let’s perceive with an instance.
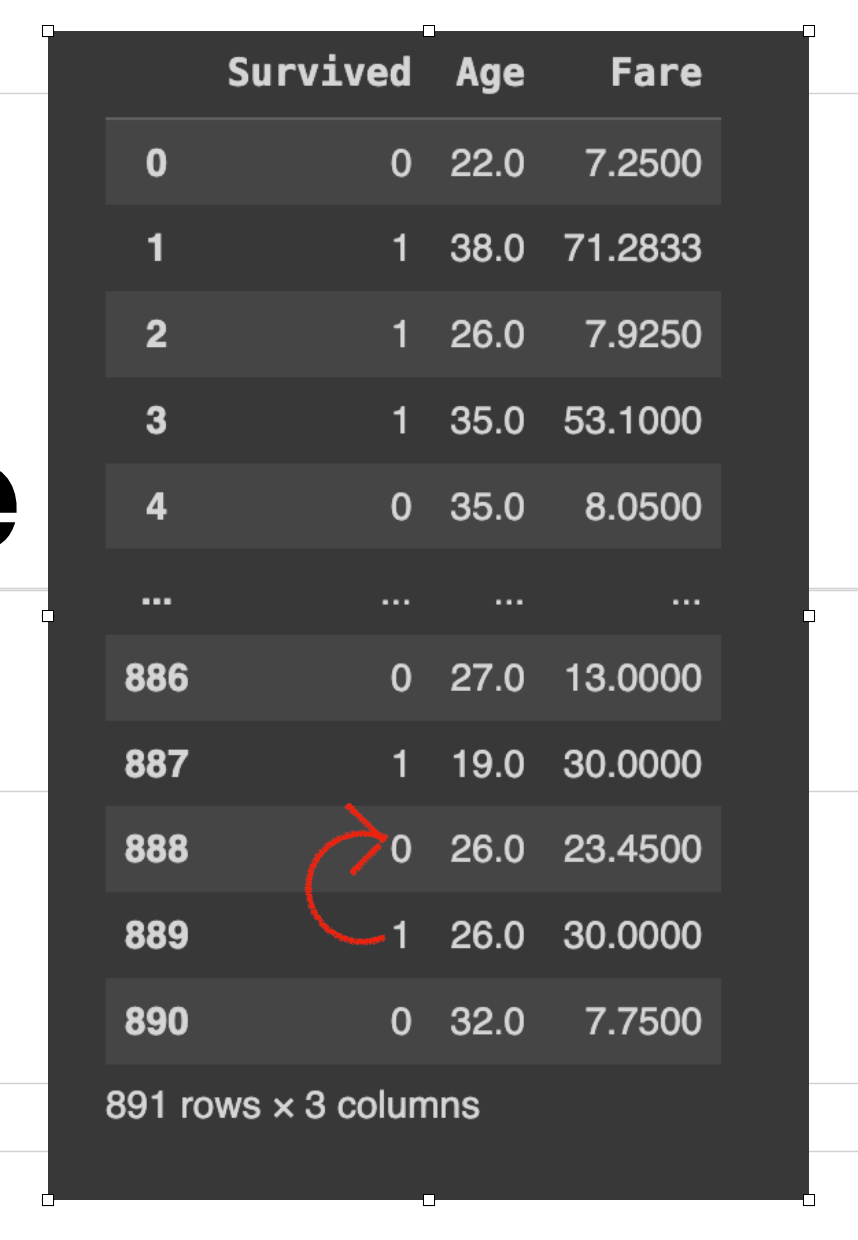
On this row, 888 had a lacking worth for the ‘Age’ column. So after working information[‘column_name’].fillna(technique=’bfill’, inplace=True). So, the worth ‘26’(subsequent worth) is copied rather than the lacking cell above.
💡
These strategies are most fitted for time-series information. Nonetheless, they might not be appropriate for information with sturdy seasonality patterns or information with vital variations between observations.
Utilizing Pandas, we are able to carry out ahead fill and backward fill as follows:
4. Changing with Arbitrary Worth
One other strategy to impute lacking values is to switch them with an arbitrary worth. Lacking values (NA) are changed with a pre-selected arbitrary quantity. The selection of this quantity can range; frequent examples embody 999, 9999, or -1. Select the worth rigorously. This may be accomplished by information[‘column_name’].fillna(-999, inplace=True)
we use the fillna() perform to switch lacking values within the ‘column_name’ column with the arbitrary worth -999.
💡
Use this technique when deleting or imputing with imply/median/mode could introduce bias and when the missingness just isn’t utterly random (MCAR).
First, Understanding the foundation explanation for lacking values is essential for choosing applicable strategies to deal with them successfully. Secondly, the tactic for dealing with lacking values is dependent upon the
Demo
Carry this mission to life
This mission could be very simple to arrange. Simply load ‘titanic.csv’ into Paperspace. Simply click on ‘begin machine’ and let’s get began. Let’s check out an instance utilizing Python:
# Importing the required libraries
import pandas as pd
import numpy as np
# Loading the dataset
# Right here, we're studying a CSV file named 'titanic.csv' and deciding on solely the
'Age', 'Fare', and 'Survived' columns.
df = pd.read_csv("titanic.csv", usecols=['Age','Fare','Survived'])
# Displaying the DataFrame
df
# Checking for lacking values in every column
df.isnull().sum()
# Filling lacking 'Age' values with the imply age
# This line replaces all NaN (Not a Quantity) values within the 'Age' column with the imply (common) age.
df['Age'].fillna(df['Age'].imply(), inplace = True)
# Filling lacking 'Age' values with the median age
# This line is redundant after the earlier fillna, as there needs to be no NaN values left to switch.
# If there have been, it could substitute them with the median age.
df['Age'].fillna(df['Age'].median(), inplace = True)
# Filling lacking 'Age' values with the mode
# This line can be redundant after the primary fillna. It could substitute NaN values with the mode (most frequent worth).
df['Age'].fillna(df['Age'].mode(), inplace = True)
# Ahead filling of lacking values
# This replaces NaN values within the DataFrame with the earlier non-null worth alongside the column.
# If the primary worth is NaN, it stays NaN.
df.ffill(inplace=True)
# Backward filling of lacking values
# This replaces NaN values with the following non-null worth alongside the column.
# If the final worth is NaN, it stays NaN.
df.bfill(inplace=True)We have now used the dataset ‘titanic.csv’. This dataset is obtainable on Kaggle. We concentrate on particular columns (‘Age’, ‘Fare’, ‘Survived’). You may test for lacking values within the dataset utilizing isnull().sum(). This step is non-obligatory. Subsequently, it demonstrates numerous strategies to impute these lacking values within the ‘Age’ column: first by changing them with the column’s imply, then the median and mode. Then ahead filling (ffill) and backward filling (bfill) strategies had been utilized, propagating subsequent or earlier legitimate values to fill gaps. Lastly, the remaining lacking values are changed with an arbitrary worth (-999).To use these modifications on to the DataFrame, inplace=True is used.
Be aware: Every subsequent technique is redundant because the earlier line already replaces all lacking values. So select one technique out of those, checking the kind of information and in addition checking how a lot information is lacking.
Conclusion
Keep in mind, lacking values are usually not an impediment; they’re a possibility to implement sturdy and modern strategies to reinforce the standard of your machine-learning fashions. So, embrace the problem of lacking values and make use of the suitable strategies to unlock the true potential of your information.
We mentioned the significance of understanding the explanations behind lacking values and distinguishing between various kinds of lacking information. We explored strategies corresponding to deleting rows with lacking values, imputation strategies like imply/median/mode imputation, ahead fill, backward fill, changing arbitrary values, and utilizing predictive fashions.