{kind=link}
Deliver this undertaking to life
On this article we introduce Mistral 7B, a big language mannequin with 7 billion parameter identified for its efficiency and effectivity. The mannequin has surpassed the efficiency of the main 13B mannequin (Llama 2) throughout all assessed benchmarks, in addition to outperforming the perfect launched 34B mannequin (Llama 1) in reasoning, arithmetic, and code era. Mistral 7B has claimed to ship excessive efficiency whereas sustaining an environment friendly inference.
The mannequin employs grouped-query consideration (GQA) to reinforce inference pace and incorporates sliding window consideration (SWA) for environment friendly processing of sequences with arbitrary size, minimizing inference prices.
We are going to use the highly effective A6000 GPU to fine-tune the mannequin which requires lower than $2 per hour. Harness the facility of A6000 for accelerated and budget-friendly fine-tuning processes.
Fantastic-Tuning Mistral-7B
We are going to use the Paperspace’s sturdy GPUs, to seamlessly fine-tune our mannequin for producing tutorial responses. The platform provides user-friendly interface and scalable infrastructure permitting environment friendly entry to GPU sources, this enables straightforward allocation of computing energy. Our focus is on coaching the mannequin utilizing 4-bit double quantization with LoRa, particularly on the MosaicML instruct dataset. Additional, we’ll slim all the way down to the ‘dolly_hhrlhf’ subset of the dataset, which is a clear response-input pair. Whatever the dataset dimension, the method stays the identical. The method includes the conversion of precise information into prompts.
Idea
Deliver this undertaking to life
This is the idea: we offer the mannequin with a response from our dataset and problem it to generate the unique instruction that led to that response. It is like complete course of however in reverse.
Allow us to begin by importing the required packages:
!pip set up transformers trl speed up torch bitsandbytes peft datasets -qUObtain the dataset wanted to fine-tune the mannequin
from datasets import load_dataset
instruct_tune_dataset = load_dataset("mosaicml/instruct-v3")
instruct_tune_dataset
kind(instruct_tune_dataset)
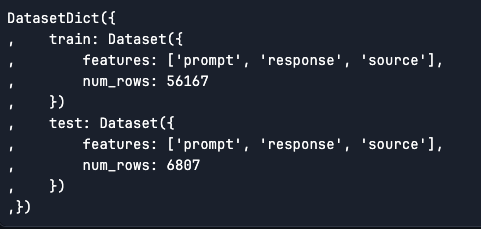
As we will see the coaching information is a pair of 56.2k rows and take a look at information is 6.8k rows and is a ‘datasets.dataset_dict.DatasetDict’ kind dataset.
Additional, we are going to slim down the dataset to acquire the subset of the info by filtering on ‘dolly_hhrlhf.’
instruct_tune_dataset = instruct_tune_dataset.filter(lambda x: x["source"] == "dolly_hhrlhf")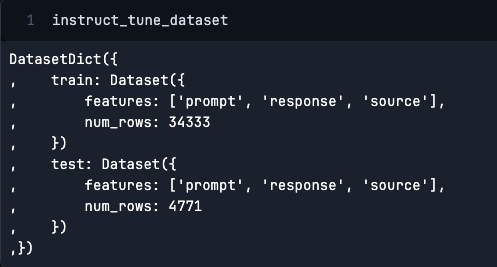
We’ll prepare and take a look at on a smaller subset of the info this would cut back the period of time spent coaching!
instruct_tune_dataset["train"] = instruct_tune_dataset["train"].choose(vary(3000))
instruct_tune_dataset["test"] = instruct_tune_dataset["test"].choose(vary(200))Subsequent, we’re going to create a operate which can soak up a pattern enter and generates a sequence. This sequence is actually the message and the immediate to get that response.
def create_prompt(pattern):
bos_token = "<s>"
original_system_message = "Beneath is an instruction that describes a process. Write a response that appropriately completes the request."
system_message = "Use the supplied enter to create an instruction that would have been used to generate the response with an LLM."
response = pattern["prompt"].exchange(original_system_message, "").exchange("nn### Instructionn", "").exchange("n### Responsen", "").strip()
enter = pattern["response"]
eos_token = "</s>"
full_prompt = ""
full_prompt += bos_token
full_prompt += "### Instruction:"
full_prompt += "n" + system_message
full_prompt += "nn### Enter:"
full_prompt += "n" + enter
full_prompt += "nn### Response:"
full_prompt += "n" + response
full_prompt += eos_token
return full_promptfor instance:-
instruct_tune_dataset["train"][0]{‘immediate’: ‘Beneath is an instruction that describes a process. Write a response that appropriately completes the request.nn### InstructionnHow can I cook dinner meals whereas tenting?nn### Responsen’,
‘response’: ‘One of the best ways to cook dinner meals is over a hearth. You’ll have to construct a hearth and lightweight it first, after which warmth meals in a pot on prime of the hearth.’,
‘supply’: ‘dolly_hhrlhf’}
create_prompt(instruct_tune_dataset["train"][0])‘<s>### Instruction:nUse the supplied enter to create an instruction that would have been used to generate the response with an LLM.nn### Enter:nThe finest method to cook dinner meals is over a hearth. You’ll have to construct a hearth and lightweight it first, after which warmth meals in a pot on prime of the hearth.nn### Response:nHow can I cook dinner meals whereas tenting?</s>’
Load and Prepare the Mannequin
that is a necessary step because the mannequin requires a good quantity of GPU area. Therefore, we are going to extremely suggest our customers to make use of a professional model to get full entry to our GPUs. We are going to nonetheless go forward with the quantized model of the mannequin from 32 bit to 4 bit.
We have determined to implement BFloat16, a 16-bit or half-precision quantization, for our compute information kind, whereas the storage information kind shall be 4 bits. Because of this we’ll retailer all weights utilizing 4 bits, however throughout coaching, we’ll quickly upcast them to 16 bits. This strategy permits us to effectively prepare whereas benefiting from the area financial savings achieved via 4-bit quantization.
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)Subsequent, load the mannequin and the tokenizer
mannequin = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.1",
device_map='auto',
quantization_config=nf4_config,
use_cache=False
)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "proper"Allow us to now transfer to the fine-tuning half!
Since we’re utilizing a quantized model of the mannequin we should always use one thing referred to as as LoRa. We have now an in depth weblog submit on LoRa authored by James Skelton. We extremely suggest to undergo the submit to get an in depth information on LoRa.
However for now we are going to perceive LoRa briefly.
LoRa
On this fine-tuning course of we’re utilizing PEFT LoRa which stands for Parameter Environment friendly Fantastic Tuning (PEFT) utilizing Low-Rank Adaptation (LoRA) technique. In easier phrases, once we educate our mannequin (prepare), we use a big set of knowledge referred to as a matrix. There are various of those matrices. LoRa is a way that helps us use a lot smaller matrices which represents the large ones. It really works by making the most of the truth that there is a bunch of repetitive stuffs within the massive matrix, particularly for what we’re attempting to do.
So, consider the total matrix like an enormous listing of all of the duties it might ever be taught, however our particular process solely wants a small a part of that listing. With LoRa, we determine the best way to focus simply on that small half. This manner, we do not have to take care of the entire listing each time we prepare our mannequin for our particular job. That is the fundamental concept behind LoRa!
This strategy additional reduces the quantity of GPU area wanted, because the mannequin would not must course of and retailer pointless info. Basically, LoRa optimizes using GPU sources and making the coaching course of extra environment friendly and saving worthwhile computing sources.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)Put together mannequin for k-bit coaching
mannequin = prepare_model_for_kbit_training(mannequin)
mannequin = get_peft_model(mannequin, peft_config)Subsequent, set the hyperparameter, that is to not make the overfit the coaching information.
args = TrainingArguments(
output_dir = "mistral_instruct_generation",
#num_train_epochs=5,
max_steps = 100,
per_device_train_batch_size = 4,
warmup_steps = 0.03,
logging_steps=10,
save_strategy="epoch",
#evaluation_strategy="epoch",
evaluation_strategy="steps",
eval_steps=20,
learning_rate=2e-4,
bf16=True,
lr_scheduler_type="fixed",
)Within the means of supervised fine-tuning (SFT), the pre-trained Language Mannequin (LLM) undergoes changes utilizing labeled information via supervised studying methods. The mannequin’s weights are modified in response to the gradients obtained from the task-specific loss, which is measured by the distinction between the predictions made by the LLM and the precise floor reality labels.
max_seq_length = 2048
coach = SFTTrainer(
mannequin=mannequin,
peft_config=peft_config,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
packing=True,
formatting_func=create_prompt,
args=args,
train_dataset=instruct_tune_dataset["train"],
eval_dataset=instruct_tune_dataset["test"]
)Subsequent, we are going to name the prepare operate, right here we prepare the mannequin for 100 steps. Please modify the code to coach utilizing variety of epochs.
import time
begin = time.time()
coach.prepare()
print(time.time()- begin)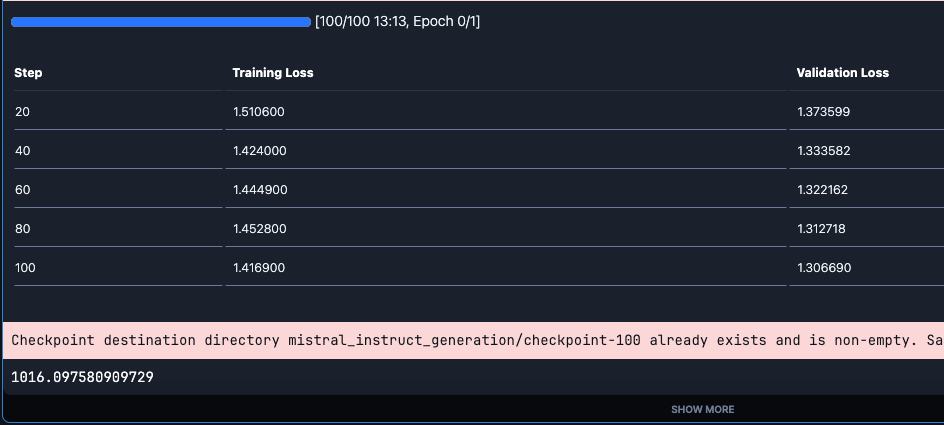
We will see that the loss step by step decreases with the steps. Additionally, word that it takes approx 16 min to coach the mannequin. Please word that it is advisable add wand credential earlier than the coaching.
We are going to save this educated mannequin domestically,
coach.save_model("mistral_instruct_generation")We will push the mannequin to hugging face hub, ensure that to authorize hugging face to push the mannequin.
On this case we push the adapter, we’re not pushing the total mannequin right here. When using LoRa for coaching, we find yourself with a element often called an adapter. This adapter serves as an extension that may be utilized to the bottom mannequin, granting it the precise capabilities acquired throughout fine-tuning.
coach.push_to_hub("shaoni/mistral-instruct-generation")View the system metrics and mannequin efficiency by checking the latest run on wandb.ai.
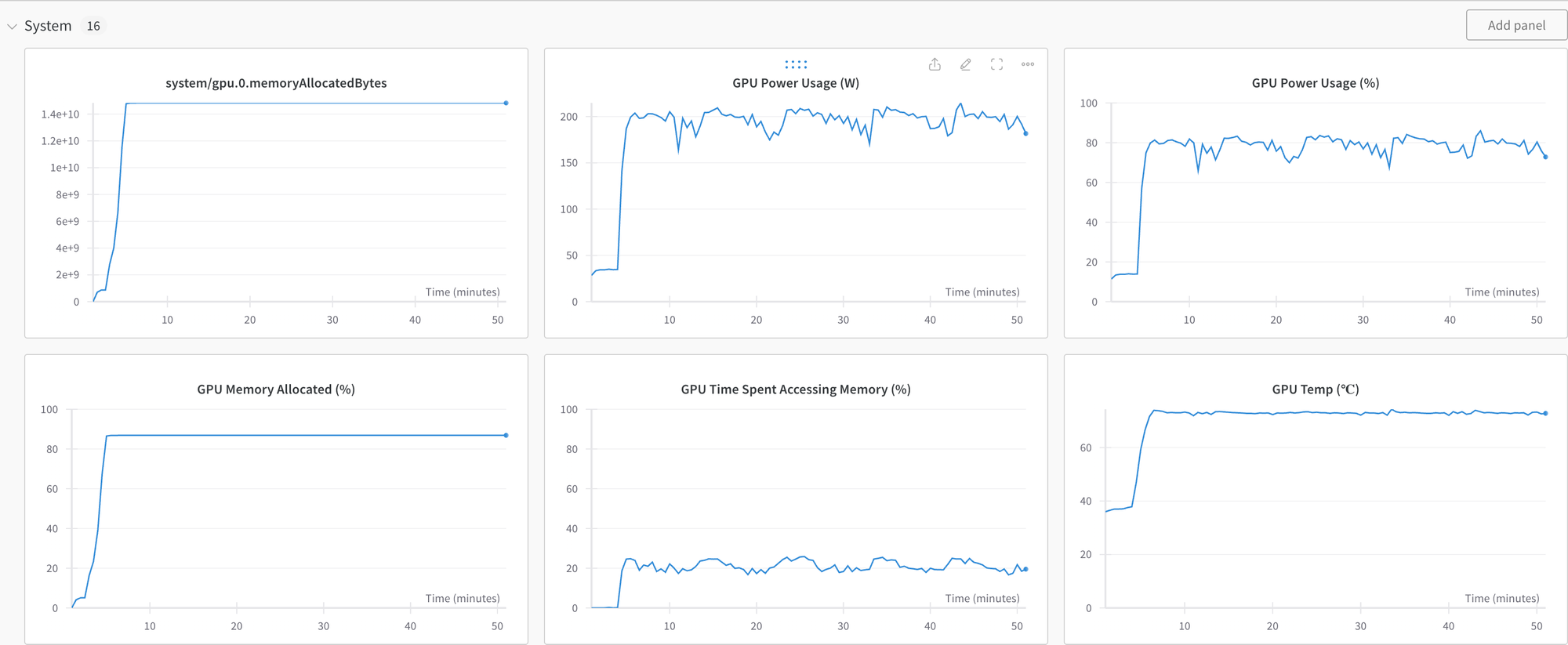
Please remember the fact that the mannequin can nonetheless underperform as it’s fine-tuned on a small pattern dataset.
generate_response("### Instruction:nUse the supplied enter to create an instruction that would have been used to generate the response with an LLM.### Enter:nThere are greater than 12,000 species of grass. The most typical is Kentucky Bluegrass, as a result of it grows shortly, simply, and is delicate to the contact. Rygrass is shiny and brilliant inexperienced coloured. Fescues are darkish inexperienced and glossy. Bermuda grass is tougher however can develop in drier soil.nn### Response:", mannequin)‘<s> ### Instruction:nUse the supplied enter to create an instruction that would have been used to generate the response with an LLM.### Enter:nThere are greater than 12,000 species of grass. The most typical is Kentucky Bluegrass, as a result of it grows shortly, simply, and is delicate to the contact. Rygrass is shiny and brilliant inexperienced coloured. Fescues are darkish inexperienced and glossy. Bermuda grass is tougher however can develop in drier soil.nn### Response:nWhich kind of grass is the commonest and why is it standard?</s>’
This response is significantly better and the mannequin isn’t just including random phrases concerning the grass.
And with this we now have come to finish of fine-tuning Mistral-7B utilizing PEFT LoRa.
To view the entire pocket book, kindly observe the hyperlink supplied within the article. Clicking on the hyperlink will redirect you to the Paperspace Platform, the place you can begin the machine to start exploring and experimenting with the code.
We additionally suggest to take a look at the references part to search out out extra. We hope you loved the article!
Thanks for studying!