{kind=link}
Deliver this challenge to life
On this article we are going to discover the massive language mannequin TinyLlama, a compact 1.1B language mannequin pre-trained on round 1 trillion tokens for 3 epochs (approx.). TinyLlama is constructed on the structure and tokenizer of Llama 2 (Touvron et al., 2023b), a brand new addition to the developments from the open-source group. TinyLlama not solely enhances computational effectivity however this mannequin outperforms different comparable-sized language fashions in numerous downstream duties, showcasing its exceptional efficiency.
Latest developments in pure language processing (NLP) have primarily resulted from the scaling up of language mannequin sizes. Massive Language Fashions (LLMs), pre-trained on intensive textual content corpora, have confirmed extremely efficient throughout various duties reminiscent of textual content summarization, content material creation, sentence structuring and lots of extra. An enormous variety of research spotlight emergent capabilities in LLMs, reminiscent of few-shot prompting and chain-of-thought reasoning, that are extra distinguished in fashions with a considerable variety of parameters. Moreover, these analysis efforts emphasize the significance of scaling each mannequin dimension and coaching knowledge collectively for optimum computational effectivity. This perception guides the collection of mannequin dimension and knowledge allocation, particularly when confronted with a set compute finances.
Lots of occasions massive fashions are most popular; this typically results in overlooking the smaller mannequin.
Language fashions when designed for optimum inference function to realize peak efficiency inside outlined inference limitations. That is completed by coaching fashions with the next variety of tokens than advisable by the scaling regulation. Curiously, smaller fashions, when uncovered to extra coaching knowledge, can attain or surpass the efficiency of bigger counterparts.
The TinyLlama mannequin is extra targeted in coaching the mannequin with a lot of tokens as an alternative of utilizing the scaling regulation.
That is the primary try to coach a mannequin with 1B parameters utilizing such a lot of knowledge.-Authentic Analysis Paper
TinyLlama demonstrates robust efficiency when in comparison with different open-source language fashions of comparable sizes, outperforming each OPT-1.3B and Pythia1.4B throughout numerous downstream duties. This mannequin is open sourced, contributing to elevated accessibility for language mannequin researchers. Its spectacular efficiency and compact dimension place it as an interesting choice for each researchers and practitioners within the A.I. discipline.
This text supplies a concise introduction to TinyLlama, that includes an illustration by a Gradio app. Gradio facilitates an environment friendly approach to showcase fashions by changing them into user-friendly internet interfaces, accessible to a broader viewers. The article features a sensible demonstration of the TinyLlama mannequin utilizing Paperspace.
Paperspace, a cloud computing platform, is highlighted for its provision of digital machines and GPU situations recognized for the various computing duties, notably within the discipline of machine studying and deep studying. The platform presents a variety of GPU choices, together with common NVIDIA GPUs just like the A6000, A4000, P4000, P6000, and the newly launched H100. With a pay-as-you-go pricing mannequin, Paperspace permits customers to effectively make the most of sources, making it an economical resolution for these needing momentary entry to sturdy GPUs with out important upfront investments.
# Import essential libraries
import torch
# Test accessible GPUs
machine = torch.machine("cuda" if use_cuda else "cpu")
print("Gadget: ",machine)
use_cuda = torch.cuda.is_available()
if use_cuda:
print('__CUDA VERSION:', torch.backends.cudnn.model())
print('__Number CUDA Units:', torch.cuda.device_count())
print('__CUDA Gadget Identify:',torch.cuda.get_device_name(0))
print('__CUDA Gadget Complete Reminiscence [GB]:',torch.cuda.get_device_properties(0).total_memory/1e9)
__CUDNN VERSION: 8401
__Number CUDA Units: 1
__CUDA Gadget Identify: NVIDIA RTX A4000
__CUDA Gadget Complete Reminiscence [GB]: 16.89124864
# Your machine studying code right here, using Paperspace GPU
# For instance, coaching a easy mannequin on GPU
# mannequin = tf.keras.Sequential([...]) # Outline your mannequin
# mannequin.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=['accuracy'])
# mannequin.match(train_data, train_labels, epochs=5, validation_data=(val_data, val_labels))
Please discuss with Paperspace documentation for any particular configurations or necessities associated to their platform.
Please be at liberty to click on the hyperlink supplied with this text to clone the repo. The repository consists of important information such together with app.py, necessities.txt, and a .ipynb file. Customers can effortlessly execute the pocket book to assemble the Gradio internet interface and discover the mannequin.
The mannequin has been pre-trained utilizing the pure language knowledge from SlimPajama and the code knowledge from Starcoderdata.
TinyLlama has the same transformer primarily based architectural strategy to Llama 2.

The mannequin consists of RoPE (Rotary Positional Embedding) for positional embedding, a method utilized in latest massive language fashions like PaLM, Llama, and Qwen. Pre-normalization is employed with RMSNorm for steady coaching. As an alternative of ReLU, the SwiGLU activation perform (Swish and Gated Linear Unit) from Llama 2 is used. For environment friendly reminiscence utilization, grouped-query consideration is adopted with 32 heads for question consideration and 4 teams of key-value heads, permitting sharing of key and worth representations throughout a number of heads with out important efficiency loss.
Additional, the analysis included Totally Sharded Knowledge Parallel (FSDP)1 to optimize the utilization of multi-GPU and multi-node setups throughout coaching. This integration is vital for effectively scaling the coaching course of throughout a number of computing nodes, this resulted in a considerable enchancment in coaching pace and effectivity. So as to add extra, one other important enhancement is the mixing of Flash Consideration 2 (Dao, 2023), an optimized consideration mechanism. Additionally, the substitute of SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the unique SwiGLU module lead a discount in reminiscence footprint. Because of this, the 1.1B mannequin can now comfortably match inside 40GB of GPU RAM.
The incorporation of those parts
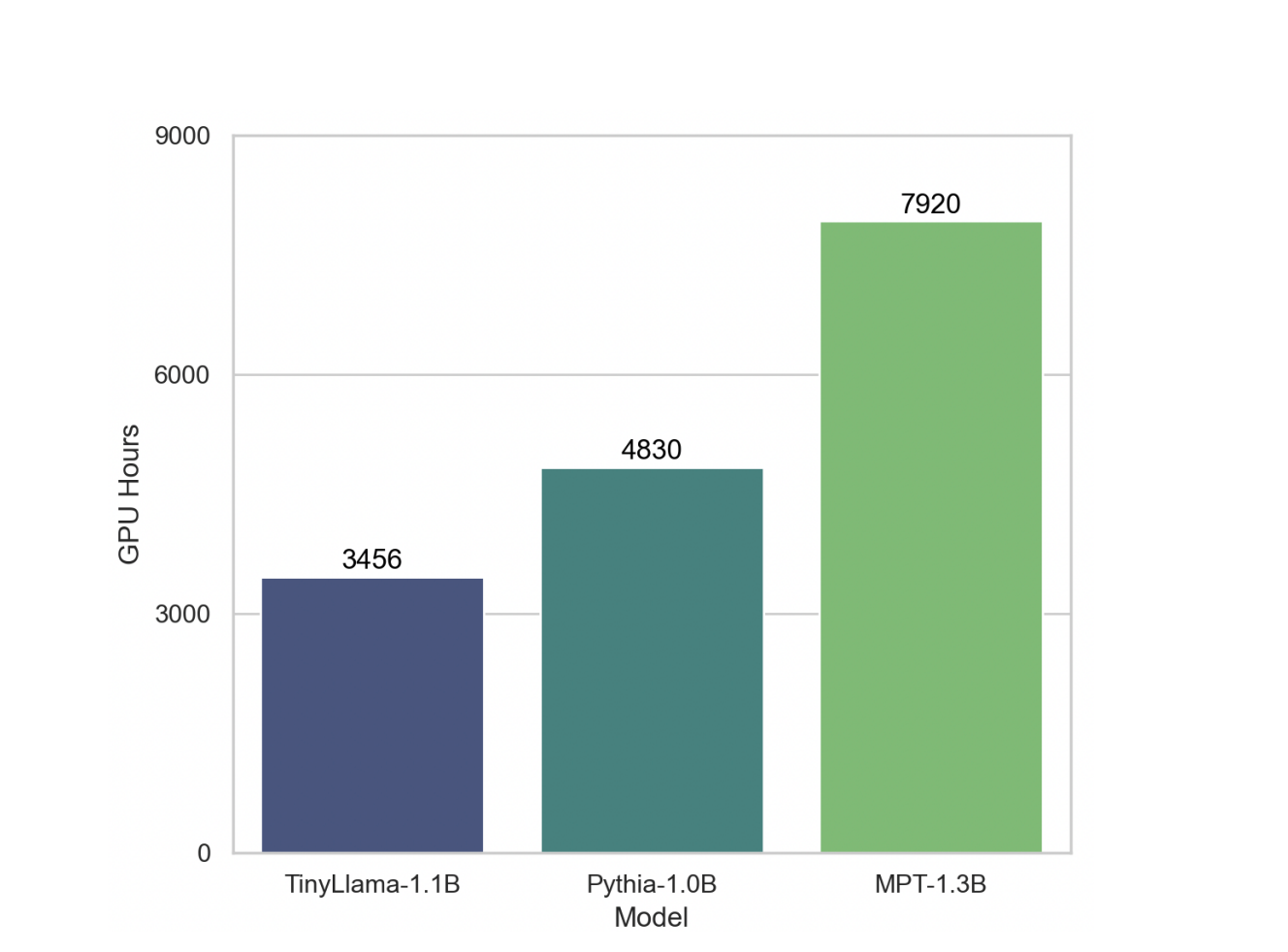
has propelled our coaching throughput to 24,000 tokens per second per A100-40G GPU. When
in contrast with different fashions like Pythia-1.0B (Biderman et al., 2023) and MPT-1.3B 2
, our codebase
demonstrates superior coaching pace. As an example, the TinyLlama-1.1B mannequin requires solely 3,456
A100 GPU hours for 300B tokens, in distinction to Pythia’s 4,830 and MPT’s 7,920 hours. This reveals
the effectiveness of our optimizations and the potential for substantial time and useful resource financial savings in
large-scale mannequin coaching. -Authentic Analysis Paper
Code Demo
Deliver this challenge to life
Allow us to take a better have a look at TinyLlama, earlier than we begin please just remember to have transformers>=4.31.
- Set up the required packages
!pip set up speed up
!pip set up transformers==4.36.2
!pip set up gradioAs soon as the packages are put in be sure that to restart the kernel
- Import the required libraries
from transformers import AutoTokenizer
import transformers
import torch- Initialize the Mannequin and the Tokenizer and use TinyLlama to generate texts
# Mannequin and Tokenizer Initialization
mannequin = "PY007/TinyLlama-1.1B-Chat-v0.1"
tokenizer = AutoTokenizer.from_pretrained(mannequin)
# Pipeline Initialization
pipeline = transformers.pipeline(
"text-generation",
mannequin=mannequin,
torch_dtype=torch.float16,
device_map="auto",
)
# Immediate
immediate = "What are the values in open supply tasks?"
formatted_prompt = (
f"### Human: {immediate}### Assistant:"
)
# Generate the Texts
sequences = pipeline(
formatted_prompt,
do_sample=True,
top_k=50,
top_p = 0.7,
num_return_sequences=1,
repetition_penalty=1.1,
max_new_tokens=500,
)
# Print the outcome
for seq in sequences:
print(f"End result: {seq['generated_text']}")
Outcomes
We now have examined the mannequin to grasp its effectivity and we will conclude that the mannequin works high quality for normal q and a and isn’t appropriate for calculations. This is sensible as these fashions are primarily designed for pure language understanding and technology duties.
Understanding the Mannequin’s Language Understanding and Downside Fixing Capabilities
TinyLlama’s downside fixing talents has been evaluated utilizing the InstructEval benchmark, which contains a number of duties. Additionally, within the Large Multitask Language Understanding (MMLU) process, the mannequin’s world data and problem-solving capabilities are examined throughout numerous topics in a 5-shot setting. The BIG-Bench Laborious (BBH) process, a subset of 23 difficult duties from BIG-Bench, evaluates the mannequin’s skill to observe complicated directions in a 3-shot setting. The Discrete Reasoning Over Paragraphs (DROP) process focuses on measuring the mannequin’s math reasoning talents in a 3-shot setting. Moreover, the HumanEval process assesses the mannequin’s programming capabilities in a zero-shot setting. This various set of duties supplies a complete analysis of TinyLlama’s problem-solving and language understanding expertise.
Conclusion
On this article we introduce TinyLlama, an open supply, small language mannequin a novel strategy on the earth of LLMs. We’re grateful for the truth that these fashions are open sourced to the group.
TinyLlama, with its compact design and spectacular efficiency, has the potential to assist end-user purposes on cellular gadgets and function a light-weight platform for experimenting with modern language mannequin concepts.
I hope you loved the article and the gradio demo!
Thanks for studying!