
{kind=link}
The mixture of Synthetic Intelligence (AI) and Neuroscience remains to be an thrilling area for scientific analysis. The examine of human cognition intersects with clever machine growth, catalyzing advances for each fields. This symbiotic relationship has the potential to revolutionize our understanding of cognition and develop extra correct diagnostics/ remedies for neurological ailments.
Synthetic Intelligence is a self-discipline in pc science that pertains to the event of machines that may emulate human intelligence. AI has efficiently been deployed throughout domains resembling medical diagnostics or pure language processing.
Developments in {hardware} have pushed technological shifts towards machine studying growth to deep studying strategies. Sustainable neuromorphic structure use of natural neural buildings attracts consideration to the event of environment friendly computing which ends up in one other technical breakthrough.
Neuroscience is the umbrella time period underneath which all facets of finding out the mind and nervous system fall. These facets embrace physiology, anatomy, psychology and even pc science. Neuroscience supplies us with the means to know mind perform, and thereby insights into their implementation utilizing AI algorithms. In distinction, AI is utilized in neuroscience analysis to research huge quantities of knowledge associated to mind performance and pathology.
This text endeavors to delve into the interdependent companionship between Synthetic Intelligence (AI) and neuroscience.
Synthetic Neural Networks
Synthetic Neural Networks (ANNs) have modified AI eternally, offering machines the flexibility to carry out duties that will usually require human intelligence. These mimic the structure and actions of neurobiological networks, roughly replicating how neurons work together to course of info in a mind.
Though ANNs have been profitable in a plethora of duties, the connection between ANN and neuroscience might give us deeper insights about synthetic and organic intelligence.
The Fundamentals of Synthetic Neural Networks
A synthetic neural community is a set of interconnected synthetic nodes, sometimes called neurons or items. Given a set of neurons, these will course of the incoming knowledge by stepping by means of completely different layers that carry out mathematical operations to derive helpful perception and make predictions.
An ANN has a number of layers together with an enter layer, one or a number of hidden layers, and an output layer. The hyperlinks that join the neurons are referred to as weights. These weights get adjusted throughout coaching to attenuate the distinction between our predicted end result and precise output. The community learns from the information by means of a course of referred to as backpropagation, the place it repeatedly adjusts itself by transferring backwards and forwards by means of the layers. We are able to characterize an Synthetic Neural Community (ANN) within the following diagram:
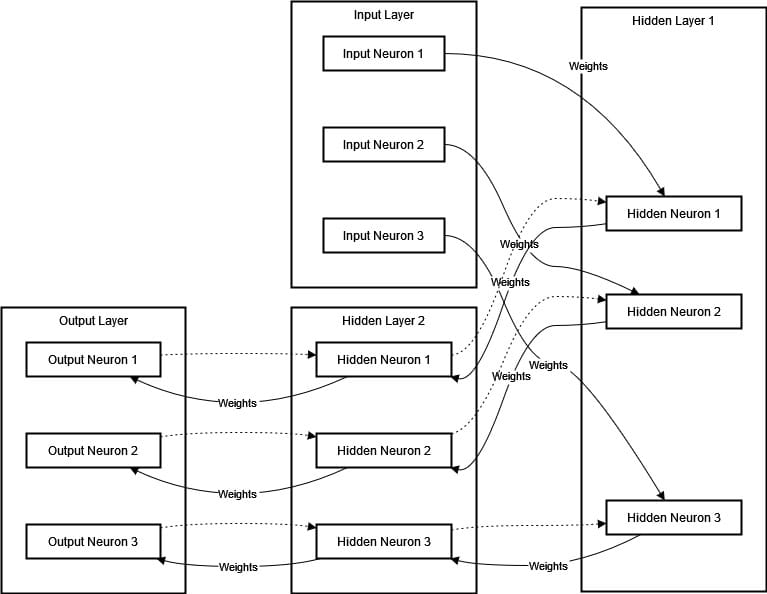
The diagram above represents an Synthetic Neural Community (ANN) with one enter layer, two hidden layers, and one output layer. Enter knowledge flows by means of the hidden layers to the output layer. Every connection has a weight that’s adjusted within the coaching section. Backpropagation is represented as dashed traces, indicating the method of weight adjustment to attenuate errors.
The Mind’s Neural Networks
The human mind is a cluster of billions of neurons, liable for creating the nervous system. Neurons talk by means of electrical and chemical indicators, a lot of which come up from complicated networks. These networks permit the mind to encode info, make choices, and direct habits. Neurons obtain enter from different neurons by means of their dendrites, course of that info within the cell physique (also called soma), after which ship indicators to downstream neurons through axons.
Neural networks within the mind are extremely dynamic and might study from expertise, retailer info related to new conditions, or recuperate perform if broken. Neuroplasticity is the capability of the mind to reorganize itself in response to modifications within the setting. The diagram under illustrates a neuron sign transmission pathway.

The purposeful anatomy of a neuron is proven within the diagram above for example its elements and their capabilities throughout sign transmission. Dendrites perform like antennas for neurons, receiving indicators from different neurons through synaptic connection. The Cell Physique (Soma) consolidates these indicators and, with the assistance of its nucleus decides if it ought to create an motion potential.
The Axon sends electrical indicators away from the cell physique to speak with different neurons, muscle tissue, or glands.
Myelin Sheath (elective) insulates axon for quicker sign transmission. On the terminus of axon, terminal boutons launch neurotransmitters in a Synaptic Cleft that bind to receptors on the dendrites of the receiving neuron. Neurotransmitters are chemical messengers launched into the synaptic cleft. Receptors on receiving neuron’s dendrites bind neurotransmitters to set off and transfer indicators additional.
Recurrent Neural Networks: Mimicking Reminiscence Processes within the Mind for Sequential Information Evaluation
Recurrent Neural Networks (RNNs) retailer info of their hidden states to tug out the patterns in knowledge sequences. Not like feedforward neural networks, RNNs course of an enter sequence one step at a time. Utilizing earlier inputs to have an effect on present outputs is right for duties resembling language modeling and time sequence forecasting. The method circulation in a Recurrent Neural Community is described within the flowchart under:
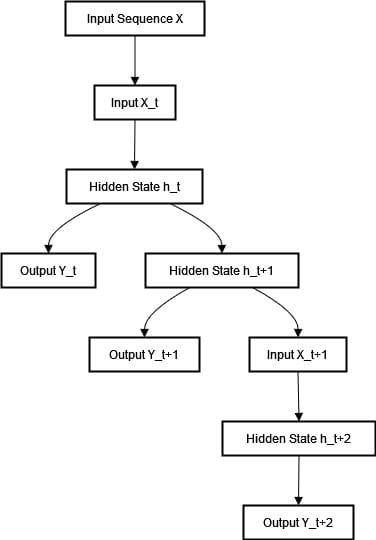
Within the diagram abobe, the enter sequence X is launched to the community as Enter X_t, which the RNN makes use of to replace its hidden state to Hidden State h_t. Based mostly on this hidden state, the RNN generates an output, Output Y_t. Because the sequence progresses, the hidden state is up to date to Hidden State h_t+1 with the subsequent enter Enter X_t+1. This up to date hidden state then evolves to Hidden State h_t+2 because the RNN processes every subsequent enter, repeatedly producing outputs for every time step within the sequence.
Reminiscence in neuroscience consists of buying, storing, retaining and recalling info. It may be divided into short-term (working reminiscence) and long-term reminiscence, with the hippocampus taking part in an necessary position in declarative recollections. The energy of synapses altering by means of synaptic plasticity is crucial for the mind’s studying and reminiscence.
RNNs borrow closely from the mind’s reminiscence capabilities and make use of hidden states to hold info throughout time, thus approximating neural suggestions loops. Each programs alter their habits based mostly on previous info, with RNNs utilizing studying algorithms to switch their weights and improve efficiency on sequential duties.
Convolutional Neural Networks and the Mind: A Comparative Perception
Convolutional Neural Networks, which have remodeled synthetic intelligence, draw inspiration from nature’s paradigm. By way of their multi-layered evaluation of visible inputs, CNNs detect important patterns in methods analogous to the human mind’s hierarchical strategy.
Their distinctive structure emulates how our brains extract summary representations of the world by means of filtering and pooling operations throughout the visible cortex. Simply as CNN’s success reshaped machine notion, evaluating them to the mind enhances our understanding of synthetic and organic imaginative and prescient.
Mind Visible Processing System
The human mind is a strong processor of visible info. Situated in entrance of the mind, the visible cortex is especially liable for processing visible info, using a hierarchical construction of neurons to attain this. These neurons are arrange in layers, every layer coping with completely different facets of the visible scene, from easy edges and textures to finish shapes and objects.
Within the preliminary phases, neurons within the visible cortex reply to easy stimuli like traces and edges. As visible info strikes by means of successive layers, neurons combine these primary options into complicated representations and in the end object recognition.
The Structure of Convolutional Neural Networks
CNNs goal to copy this strategy, and the ensuing community is an structure with a number of layers. Convolutional layers, pooling layers, and absolutely linked layers are several types of layers in a CNN. They’re liable for detecting the precise options within the enter picture, the place every layer passes its outputs on to the next layers. Let’s think about every one among them:
- Convolutional Layers: These layers use filters to “look” on the enter picture and detect native options like edges or textures. Each filter behaves like a receptive subject and captures the native area in enter knowledge, very like the receptive fields of neurons within the visible cortex.
- Pooling Layers: These layers cut back the spatial dimensions of the information whereas nonetheless preserving vital traits. It’s a good approximation to the truth that human brains can condense and prioritize visible info.
- Absolutely Linked Layers: Within the last phases, the final layers combine all detected options. This strategy is much like how our brains combine complicated options to acknowledge an object, resulting in a last classification or resolution.
Similarities and Variations
The similarity between synthetic neural networks crafted for pc imaginative and prescient duties and the complicated visible system in organic organisms lies of their hierarchical architectures. In CNNs, this development emerges by means of simulated neurons performing mathematical operations. In residing entities, it arises by means of precise neurons exchanging electrochemical indicators.
Nonetheless, putting variations do exist. The mind’s visualization dealing with far exceeds present algorithms in complexity and dynamism. Natural neurons maintain the potential for interactive, experience-driven plasticity not possible to completely emulate. Moreover, the mind processes info, different senses and contextual particulars. This enables it to type a richer, extra holistic understanding of the setting moderately than analyzing pictures independently.
Reinforcement Studying and the Mind: Exploring the Connections
One parallel that may exist between RL and the human mind is how each programs study by interacting with their setting. The substitute intelligence subject is progressively being formed by RL algorithms. This enables us to higher perceive how its studying methods relate to these of our brains.
Reinforcement Studying
Reinforcement Studying (RL) is a sort of machine studying the place the agent learns to make choices by interacting with its setting. It will get a reward or penalty in accordance with its actions. After sufficient trials, the training algorithm figures out which actions result in maximize cumulative reward and learns an optimized coverage to make choices.
RL entails key elements:
- Agent: It makes decisions to succeed in a objective.
- Surroundings: That is all the pieces exterior the agent that it will possibly work together with and get suggestions from.
- Actions: These are the various things the agent can select to do.
- Rewards: The setting offers the agent good or unhealthy factors after every option to let it know the way it’s doing.
- Coverage: The technique that the agent follows to find out its actions.
Mind Studying Mechanism
In an identical method to RL algorithms, the human mind operates in an setting that gives reinforcement indicators throughout studying. In relation to mind studying, particularly reinforcement-related processing, some mechanisms are a part of this course of:
- Neural Circuits: Networks of neurons that soak up info and inform decision-making.
- Dopamine System: A neurotransmitter system concerned in reward processing and reinforcement studying. The dopamine indicators are reward suggestions that adjusts future habits.
- Prefrontal Cortex: A mind area concerned in planning, decision-making, and evaluating doable rewards/penalties.
Similarities Between Reinforcement Studying and Mind Studying
Let’s think about some similarities between Reinforcement studying and mind studying:
- Trial and Error: RL algorithms and the mind study by means of trial and error. RL brokers differ within the actions they take to see what offers them the optimum rewards. In the identical means, our mind tries out varied behaviors to seek out which actions are simplest.
- Reward-based Studying: In RL, the brokers study from their rewards. Dopamine indicators encourage the mind to strengthen behaviors that result in constructive outcomes whereas lowering these resulting in adverse outcomes.
- Worth Perform: Utilizing worth capabilities, an RL algorithm can estimate anticipated rewards for all actions. Comparable mechanisms are utilized by the mind for potential rewards analysis and decision-making.
- Exploration vs. Exploitation: RL brokers stability exploration (attempting new actions) and exploitation (utilizing recognized actions that yield excessive rewards). The mind additionally performs a stability between exploring new behaviors and counting on realized methods.
Variations and Developments
Though RL algorithms are impressed by mind capabilities there’s a huge distinction. Let’s think about a few of them:
Complexity
The mind studying mechanism is extra complicated and dynamic than probably the most refined present RL algorithms. That is exemplified by the flexibility of our mind to course of sensory info from disparate sources, adapt in actual time, and function with appreciable flexibility.
Switch Studying
People can study and switch acquired information to new conditions, a property that is still troublesome for many RL programs. In novel environments or duties, most RL algorithms require important retraining.
Multi-modal Studying
The mind is a multi-modal learner, leveraging completely different sensory inputs and experiences to study extra successfully. Nonetheless, even probably the most superior RL programs give attention to a single sort of interplay or setting.
The Symbiosis Between RL and Neuroscience
The connection between RL and the mind is bidirectional. Insights from neuroscience are built-in into the design of RL algorithms. This ends in extra refined fashions which replicate brain-inspired studying processes. Then again, enhancements in RL can facilitate an explanatory framework to mannequin and simulate mind perform (thus aiding computational neuroscience).
Use Case: Enhancing Autonomous Driving Methods with Reinforcement Studying
Superior algorithms allow autonomous autos to navigate complicated environments, make instant choices, and preserve passengers secure. Nonetheless, most of the present algorithms carry out poorly in unpredictable situations.
This consists of sudden visitors flows, climate circumstances, and erratic driving habits from drivers. More and more, these calls for require the flexibility to reply considerably like a human mind would—requiring an adaptive and dynamic decision-making course of.
Answer
We are able to add Reinforcement Studying (RL) algorithms to imitate human studying to assist enhance the decision-making energy of our autonomous driving programs. RL imitates our mind by studying from rewards and adapting to new situations. This allows it to reinforce the efficiency of those programs underneath real-world driving circumstances.
The diagram under illustrates the iterative strategy of our autonomous driving system utilizing Reinforcement Studying (RL).
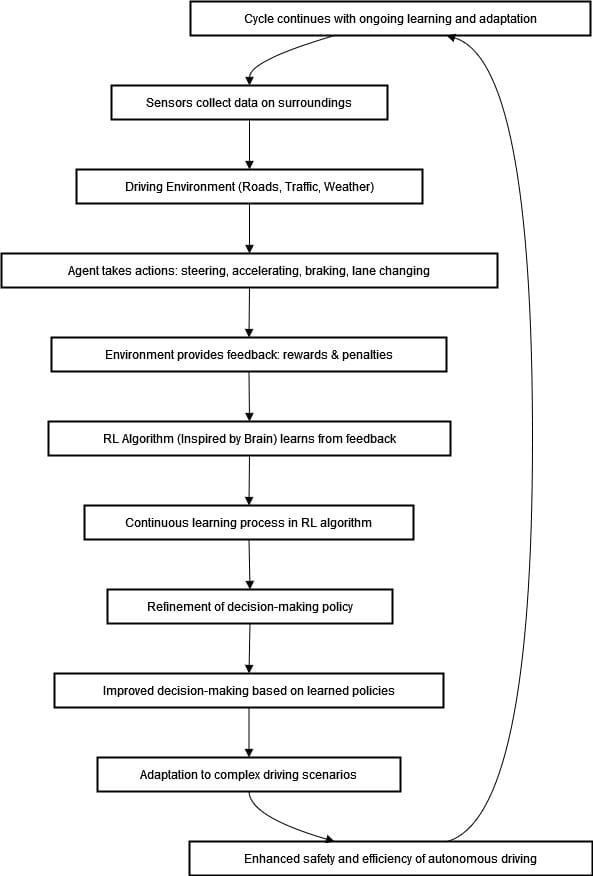
The agent (autonomous car) interacts with the setting, receives suggestions by means of sensors, and adjusts its habits utilizing RL algorithms. By repeatedly studying and refining its coverage, the system continues to enhance decision-making and help extra complicated situations that additional improve driving security and effectivity.
Deep Reinforcement Studying
Deep Reinforcement Studying (DRL) is a strong set of algorithms for instructing agent how you can behave in an setting by means of deep studying and reinforcement Studying ideas. This methodology permits machines to study by means of trial and error, like human beings or every other organism on this planet.
The ideas underlying DRL share similarities with the mind studying course of. Consequently, it would present us useful clues on synthetic and organic intelligence.
Parallels Between DRL and the Mind
Let’s think about some parallels between Deep Reinforcement Studying and the mind:
- Hierarchical Studying: The mind and deep reinforcement studying execute studying throughout a number of ranges of abstraction. The mind processes sensory info in phases, the place every stage extracts more and more extra complicated options. Redundantly, that is parallel to the deep neural networks in DRL which study hierarchical representations from primary edges (early layers) as much as high-level patterns (deeper ones).
- Credit score Project: One of many challenges in each DRL and the mind is determining which actions are to be credited for rewards. The mind’s reinforcement studying circuits, which contain the prefrontal cortex and basal ganglia, assist to attribute credit score for actions. DRL offers with it utilizing strategies resembling backpropagation by means of time and temporal distinction studying.
- Generalization and Switch Studying: The mind excels at generalizing information from one context to a different. As an example, studying to experience a bicycle could make it simpler to study to experience a motorbike. DRL is starting to attain related feats, with brokers that may switch information throughout completely different duties or environments, though this stays an space of energetic analysis.
Developments and Challenges
DRL has come a great distance however remains to be removed from capturing brain-like studying with all its intricacies. Areas the place DRL could provide enhancement embrace the seamless mixing of multi-modal (imaginative and prescient, listening to, and contact) info. It additionally consists of robustness to noisy or incomplete knowledge, and its effectivity in studying from restricted experiences.
In the meantime, in DRL analysis, neuroscience appears to have an outsized affect. To enhance DRL efficiency, new approaches are being examined resembling neuromodulation (which mimics how neurotransmitters within the mind regulate studying). Moreover, memory-augmented networks try and emulate some distinctive qualities of human reminiscence.
Spiking Neural Networks
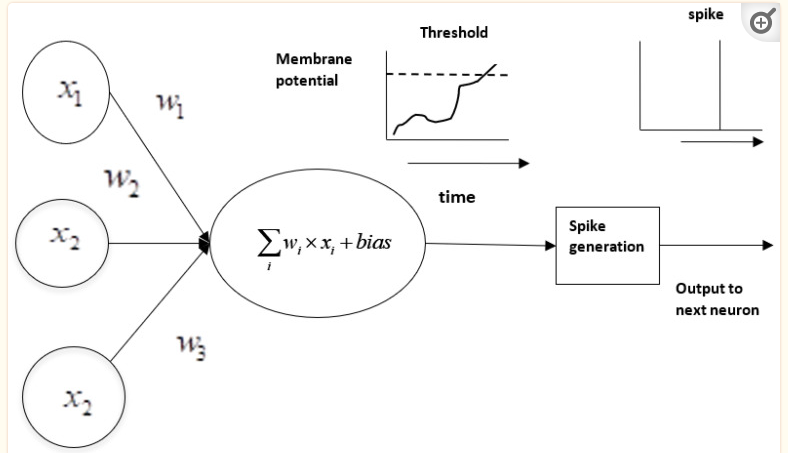
The Spiking Neural Networks are a sort of neural mannequin that features the dynamics of organic neurons. As a substitute of utilizing steady values for neuron activations like conventional fashions, SNNs depend on discrete spikes or pulses. These spikes are generated as soon as the neuron’s membrane potential exceeds some threshold as proven within the picture under. These spikes are based mostly on the motion potentials of organic neurons.
Key Options of Spiking Neural Networks
Let’s think about some options:
- Temporal Dynamics: SNNs mannequin the timing of spikes. It permits them to trace temporal patterns and dynamics which might be vital in understanding how the mind performs over a sequence of occasions.
- Occasion-based processing: Neurons in SNNs get activated solely when spike happens. This basically event-driven nature is environment friendly and extra akin to how organic brains course of info.
- Synaptic Plasticity: SNNs can mannequin a number of types of synaptic plasticity. These embrace spike timing dependence of plasticity (STDP). This mechanism adjusts the energy of connections based mostly on the timing of spikes, mirroring studying processes within the mind.
Connection to Neuroscience
SNNs are supposed to reproduce the habits of organic neurons higher than conventional neural networks. They act as a mannequin of neuron behaviors and their electrical actions in receiving and sending spiking underneath time-dynamic associations.
They provide a window for researchers to know how info is encoded and processed in organic neurons. This will present perception into how sensory info is encoded and play a task in studying and reminiscence laws.
SNNs are central to neuromorphic computing, which goals to develop {hardware} that mimics the facility and effectivity of our brains. It will allow extra power-efficient and versatile computing programs.
Spiking Neural Networks Purposes
SNNs can acknowledge patterns in knowledge streams, like visible or auditory enter. They’re designed to course of and acknowledge temporal patterns or real-time streams.
They’re used for sensory processing and motor management in robotics. They’re event-driven, which makes them excellent for real-time decision-making, particularly in dynamic environments.
SNNs may also be utilized in brain-machine interfaces to interpret the neural indicators for controlling exterior gadgets.
Use Case: Enhancing Mind-Machine Interfaces with Spiking Neural Networks (SNNs)
Mind-machine interfaces (BMIs) confer with programs that acknowledge and translate neural indicators into directions that may be processed by an exterior machine. They’ve giant prospects for analysis together with serving to individuals with neurological ailments, enhancing cognitive capabilities, and even constructing state-of-the-art prosthetics.
Spiking Neural Networks (SNNs) present a substitute for present approaches which were discovered much less environment friendly for excellent BMIs. They’re impressed by the neural mechanisms of the mind. Our goal is to reinforce the accuracy and responsiveness of a BMI for controlling a robotic arm by means of thought alone.
Answer
The diagram under can describe the method.
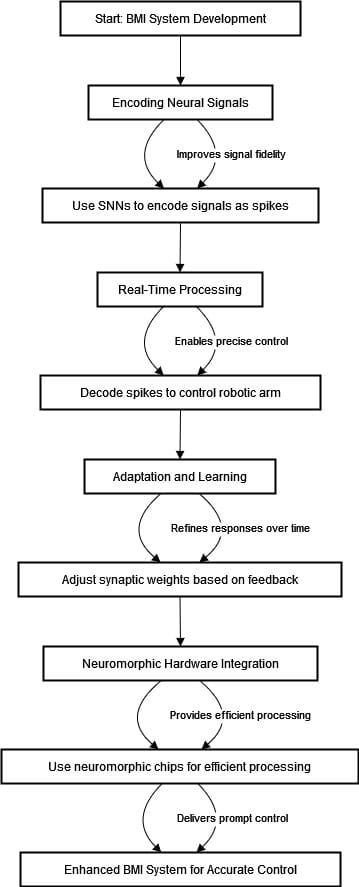
The diagram above represents a flowchart for the event of a Mind-Machine Interface (BMI) system enhanced by Spiking Neural Networks (SNNs). The primary section is the encoding of neural indicators with SNNs that convert steady mind indicators to discrete spikes. This encoding improves the sign’s integrity and permits a greater approximation to actual mind exercise. The next phases embrace actual time processing the place the timing and order of those spikes are decoded. This allows the robotic arm to be managed precisely with reactivity pushed by neural intention.
After real-time processing, the system can adapt and study. SNNs alter synaptic weights in accordance with the robotic arm actions, thus optimizing responses from the community with a studying expertise. The final section focuses on neuromorphic {hardware} integration, which mimics the brain-like processing of spikes. Such {hardware} permits power effectivity and real-time processing. This ends in a greater BMI system that may command the robotic arm promptly and precisely. Lastly, we’ve a sophisticated methodology to design BMIs that makes use of the organic realism of SNNs for extra appropriate and adaptable algorithms.
Conclusion
Manmade Intelligence (AI) and Neuroscience are a promising analysis space, combining each fields. AI refers back to the simulation of human intelligence in machines designed for duties resembling medical prognosis and pure language processing. {Hardware} advances have seen a transition from machine studying to deep studying, with neuro-inspired structure leveraging natural neural buildings for extra environment friendly computation.
Synthetic Neural Networks(ANNs) are synthetic variations of organic networks boasting extremely spectacular synthetic intelligence functionalities. RNNs and CNNs are impressed by processes within the mind to acknowledge patterns in sequential knowledge and visible processing.
Reinforcement Studying (RL) mimics how the mind learns by means of trial and error, with implications for autonomous driving and different areas. Deep Reinforcement Studying (DRL) investigates additional the training processes of AI. Spiking Neural Networks (SNNs) mannequin extra precisely the habits of organic neurons.