
{kind=link}
The sphere of Pure language processing or NLP has undergone inspiring breakthrough because of the incorporation of state-of-art deep studying strategies. These algorithms have improved the inner flexibility of NLP fashions exponentially past human chance.
They’ve excelled in duties resembling textual content classification, pure language inference, sentiment evaluation, and machine translation. By leveraging massive quantities of knowledge – these deep studying frameworks are revolutionizing how we course of and perceive language. They’re inspiring high-performance outcomes throughout numerous NLP duties.
Regardless of the advances which have been witnessed within the sector of Pure Language Processing (NLP) there are nonetheless open points together with threat of adversarial assaults. Often, such assaults contain injecting small perturbations into the info which are hardly noticeable, however efficient sufficient to deceive an NLP mannequin and skew its outcomes.
The presence of adversarial assaults in pure language processing can pose a problem, versus steady information resembling pictures. That is primarily because of the discrete nature of text-based information which renders the efficient era of adversarial examples extra complicated.
Many mechanisms have been established to defend in opposition to the assaults. This text affords an summary of adversarial mechanisms that may be categorized underneath three broad classes: adversarial training-based strategies, perturbation control-based strategies and certification-based strategies.
Overview of Adversarial Assaults in NLP
Understanding of the various kinds of assaults is crucial to create sturdy defenses and fostering confidence in NLP fashions’ reliability.
Kinds of Assaults
The diagram under describe the various kinds of assaults.
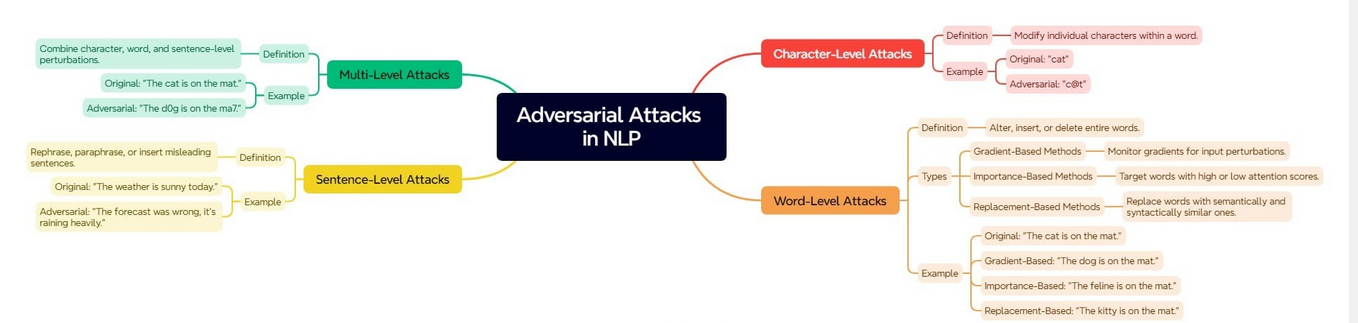
Adversarial assaults within the discipline of Pure Language Processing (NLP) have the potential to have an effect on various textual content granularities, spanning from particular person characters as much as whole sentences. They might additionally exploit a number of ranges concurrently for extra complicated assaults.
Black Field vs. White Field Assaults
The classification of adversarial assaults on NLP fashions will be usually characterised as two sorts(black-box assaults and white-box assaults) These depend on the extent of entry that the attacker has to the mannequin’s parameters. It’s crucial to know these classes to ascertain protection mechanisms.
White Field Assaults
A white field assault entails an attacker having unrestricted management over all parameters related to a specific mannequin. Such elements embody however usually are not restricted to structure, gradients and weights – granting intensive information relating to inside operations. From this place of deep perception into mentioned mechanisms, attackers can execute focused adversarial measures with effectivity and precision.
Adversaries ceaselessly leverage gradient-based strategies to detect essentially the most proficient perturbations. By computing the gradients of the loss perform with respect to the enter, attackers can deduce which modifications to inputs would have a considerable affect on mannequin output.
Owing to the intensive familiarity with the mannequin, white field assaults generally tend to realize nice success in fooling it.
Black Field Assaults
Within the paradigm of black field assaults, entry to a given mannequin’s parameters and structure stays restricted for attackers. Nevertheless, their communication with the mannequin is restricted to enter, to which the mannequin responds with outputs.
The very nature of such an attacker is restricted, which makes black field assaults extra complicated. The noticed queries are the one means by which they’re compelled to infer the mannequin’s inherent habits.
Typically, attackers interact within the course of of coaching a surrogate mannequin that emulates the patterns of operation exhibited by its supposed goal. This surrogate mannequin is subsequently employed to formulate cases of adversarial nature.
Challenges in Producing NLP Adversarial Examples
The era of efficient adversarial examples in pure language processing (NLP) is a multifaceted enterprise that presents inherent challenges. These challenges come up from the complexity of linguistics, NLP mannequin habits, and constraints related to assault methodologies. We’ll summarize these challenges within the following desk:
| Problem | Description |
|---|---|
| Semantic Integrity | Guaranteeing adversarial examples are semantically much like the unique textual content. |
| Linguistic Variety | Sustaining naturalness and variety within the textual content to evade detection. |
| Mannequin Robustness | Overcoming the defenses of superior NLP fashions. |
| Analysis Metrics | Lack of efficient metrics to measure adversarial success. |
| Assault Transferability | Reaching transferability of assaults throughout completely different fashions. |
| Computational Sources | Excessive computational calls for for producing high quality adversarial examples. |
| Human Instinct and Creativity | Using human creativity to generate practical adversarial examples. |
These challenges underscore the necessity for continued analysis and growth efforts to advance the area of adversarial assaults in pure language processing. Additionally they spotlight the significance to enhance NLP programs’ resilience in opposition to such assaults.
Adversarial Coaching-Primarily based Protection Strategies
The first goal of adversarial training-based protection is to reinforce the mannequin’s resilience. It is achieved by subjecting it to adversarial examples throughout its coaching section. Moreover, it entails integrating an adversarial loss into the general coaching goal.
Knowledge Augmentation-Primarily based Approaches
Approaches based mostly on information augmentation entail creating adversarial examples and incorporating them into the coaching dataset. This technique facilitates the event of a mannequin’s capability to handle perturbed inputs, enabling it to resist assaults from adversaries with resilience.
For instance, some strategies might contain introducing noise into phrase embeddings or implementing synonym substitution as a way for producing adversarial examples. There are completely different approaches to performing information augmentation-based adversarial coaching. These embody phrase stage information augmentation, concatenation based mostly information augmentation and era based mostly information augmentation.
Phrase-Stage Knowledge Augmentation
On the word-level, textual content information augmentation will be carried out by making use of some perturbations on to the phrases of the enter textual content. This may be achieved by substitution, addition, omission, or repositioning of phrases in a sentence or doc. Via these perturbations, the mannequin is educated to detect and handle adversarial adjustments that happens.
For exemple, the phrase “The film was implausible” could also be reworked into “The movie was nice.” Utilizing these augmented datasets for coaching allows the mannequin to generalize higher and reduces its vulnerability in opposition to enter perturbations.
Concatenation-Primarily based and Technology-Primarily based Knowledge Augmentation
In concatenation-based method, new sentences or phrases are added to the unique textual content. This methodology can inject adversarial examples by concatenating different info which may change the mannequin’s predictions. For instance, in a picture classification situation, an adversarial instance is likely to be created by including a deceptive sentence to the enter textual content.
The generation-based information augmentation generates new adversarial examples utilizing generative fashions. Utilizing Generative Adversarial Networks (GANs), it is doable to create adversarial texts which are syntactically and semantically right. These generated examples are then included into the coaching set to reinforce the range of adversarial situations.
Regularization Methods
Regularization strategies add adversarial loss to the coaching goal. This encourages the mannequin to provide the identical output for clear and adversarial pertubed inputs. By minimizing the distinction in predictions on clear and adversarial examples, these strategies make the mannequin extra sturdy to small perturbations.
In machine translation, regularization can be utilized to make sure that the interpretation is identical even when the enter is barely perturbed. For instance, translating “She goes to the market” ought to give the identical consequence if the enter is modified to “She’s going to the market”. This consistency makes the mannequin extra sturdy and dependable in actual world functions.
GAN-Primarily based Approaches
GANs use the ability of Generative Adversarial Networks to enhance robustness. In these strategies a generator community creates adversarial examples and a discriminator community tries to tell apart between actual and adversarial inputs. This adversarial coaching helps the mannequin to be taught to deal with a variety of doable perturbations. GANs have proven promise to enhance efficiency on clear and adversarial inputs.
In a textual content classification activity a GAN can be utilized to generate adversarial examples to problem the classifier. For instance producing sentences which are semantically related however syntactically completely different, like altering “The climate is good” to “Good is the climate” may help the classifier to be taught to acknowledge and classify these variations.
Digital Adversarial Coaching and Human-In-The-Loop
Specialised strategies for adversarial coaching embody Digital Adversarial Coaching (VAT) and Human-In-The-Loop (HITL). VAT works by producing perturbations that maximize the mannequin’s prediction change in a small neighborhood round every enter. This improves native smoothness and robustness of the mannequin.
Quite the opposite, HITL strategies embody human enter throughout adversarial coaching. By requiring enter from people to create or validate difficult examples, these approaches generate extra practical and difficult inputs. This enhances a mannequin’s resilience in opposition to assaults.
All of those protection strategies look very efficient. Additionally they current a set of approaches to reinforce the resilience of NLP fashions from adversarial assaults. Throughout mannequin coaching, these approaches guarantee fashions are educated with various kinds of adversarial examples therefore making the NLP programs extra sturdy.
Perturbation Management-Primarily based Protection Strategies
In NLP, protection strategies based mostly on perturbation management intention to detect and alleviate unfavorable impacts brought on by adversarial perturbations. These methods will be categorized into two strategies: perturbation identification and correction, and perturbation path management.
The primary goal of perturbation identification and correction strategies is to detect and handle adversarial perturbations within the enter textual content. They normally make use of a number of strategies to detect suspicious or adversarial inputs. For instance, to detect out-of-distribution phrases or phrases, the mannequin can use language fashions or depend on statistical strategies to detect uncommon patterns within the textual content. After detection, these perturbations will be mounted or eliminated to carry the textual content again to its authentic that means as supposed.
Alternatively, perturbation path management strategies lean in the direction of controlling the path of doable perturbations to cut back their impact on the mannequin’s consequence. Such strategies are normally utilized by altering both the construction of the mannequin or the coaching course of itself to reinforce the mannequin’s robustness in opposition to particular varieties of perturbations.
Enhancing the Robustness of Buyer Service Chatbots Utilizing Perturbation Management-Primarily based Protection Strategies
Organizations are adopting customer support chatbots to handle buyer inquiries and provide help. Nonetheless, these chatbots will be vulnerable to adversarial assaults. Slight modifications within the enter textual content might end in inaccurate or unreliable responses. To strengthen the resilience of such chatbots, protection mechanisms based mostly on perturbation management can be utilized.
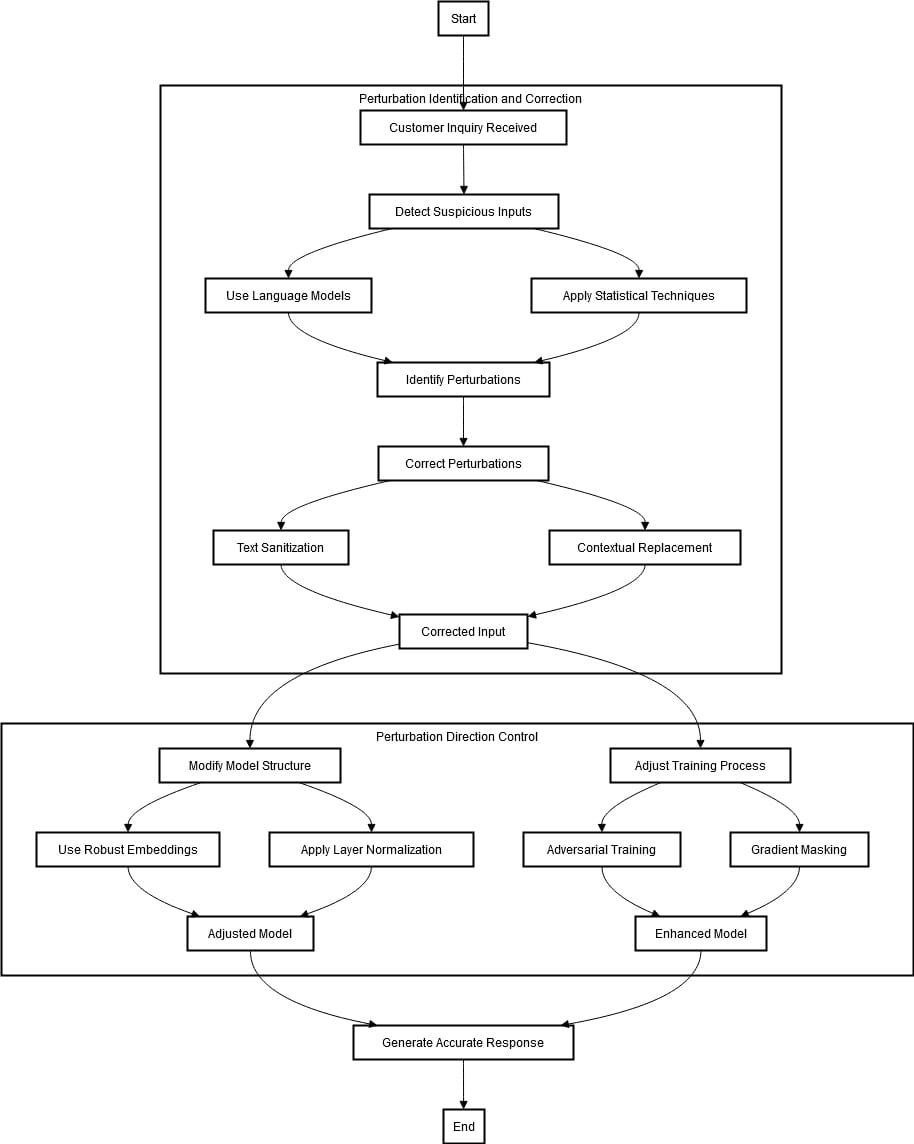
The method begins by receiving a request from a buyer. Step one is to determine and proper any perturbations within the enter textual content which may be adversarial. That is achieved by means of language fashions and statistical strategies that acknowledge uncommon patterns or out-of-distribution phrases indicative of such assaults. As soon as detected, they are often corrected by means of textual content sanitization (e.g., correcting spelling errors), or contextual substitute (i.e., changing inappropriate phrases with extra related ones).
The second stage focuses on perturbation path management. This consists of enhancing the chatbot’s resistance in opposition to adversarial assaults. This may be achieved by adjusting the coaching course of and modifying its mannequin construction. To make it much less weak to slight modifications within the enter textual content, sturdy embeddings, and layer normalization strategies are included into the system.
The coaching mechanism is adjusted by integrating adversarial coaching and gradient masking. This course of entails coaching the mannequin on authentic and adversarial inputs, guaranteeing its capability to proficiently handle perturbations.
Certification-Primarily based Protection Strategies in NLP
Certification-based protection strategies provide a proper stage of assurance of resistance in opposition to adversarial assaults in NLP fashions. These strategies make sure that the mannequin performances stay constant in a given neighborhood of the enter area and will be thought-about as a extra rigorous resolution to the mannequin robustness drawback.
In distinction to adversarial coaching or perturbation management strategies, certification-based strategies enable proving mathematically {that a} specific mannequin is strong in opposition to sure varieties of adversarial perturbations.
Within the context of NLP, certification strategies normally entails the specification of a set of allowable perturbation (for instance, substitute of phrases, characters, and so forth.) of the unique enter after which guaranteeing the mannequin’s output stays constant for all inputs inside this outlined set.
There are numerous strategies to compute provable higher bounds on a mannequin’s output variations underneath enter perturbations.
Linear Leisure Methods
Linear rest strategies contain approximating the non-linear operations that exist in a neural community by linear bounds. These strategies remodel the precise non-linear constraints into linear ones.
Fixing these linearized variations, we are able to get the higher and decrease bounds of the output variations. Linear rest strategies present a stability between computational effectivity and the tightness of the bounds, providing a sensible approach to confirm the robustness of complicated fashions.
Understanding Interval Sure Propagation
Interval sure propagation is a approach to make the neural community fashions much less delicate to perturbation and to compute the interval of the community outputs. This methodology aids in guaranteeing that the mannequin’s outputs keep bounded even when the inputs could also be barely modified.
The method will be outlined as follows:
- Enter Intervals: Step one on this course of entails figuring out ranges for the inputs of the mannequin. An interval is a set of values which can be taken by the enter. For instance, if the enter is a single quantity, an interval is likely to be [3. 5, 4. 5]. Which means the enter is inside the vary of the 2 numbers: 3. 5 and 4. 5.
- Propagation by means of Layers: The enter intervals are then reworked by means of the layer’s operations as they progress by means of the layers of the neural community. The output of every layer can be an interval. If the enter interval is [3. 5, 4. 5] and the layer carried out a multiplication by 2 on every of the inputs, the present interval could be [7. 0, 9. 0].
- Interval Illustration: The output is an interval that accommodates all values that the layer’s output can take given the enter interval. This implies if there are any pertubations inside the enter interval, the output interval will nonetheless embody all of the doable ranges.
- Systematic Monitoring: The intervals are tracked systematically by means of every layer of the community. This entails updates of intervals at every step to precisely replicate doable output values within the subsequent step after transformation. Instance: If the second layer provides 1 to the output, the interval [7.0, 9.0] turns into [8.0, 10.0].
- Assured Vary: By the point the enter intervals have propagated by means of all of the layers of the community, the ultimate output interval offers a assured vary of values. This vary signifies all doable outputs the mannequin can produce for any enter inside the preliminary interval.
The above course of will be visualized within the diagram under.
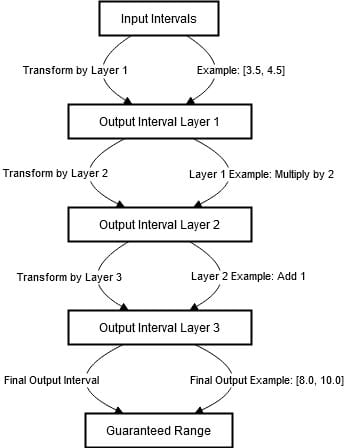
The above diagram highlights the steps taken to make sure that the outputs of the neural community are bounded regardless of of the enter variations. It begins with the specification of the primary enter intervals.
When passing by means of layers of the community, inputs endure extra modifications resembling multiplication and addition which modify the intervals.
For instance, multiplying by 2 shifts the interval to [7. 0,9. 0], whereas including 1 adjustments the interval to [8. 0,10. 0]. In every layer, the output supplied as an interval encompasses all of the doable values given the vary of inputs.
Via this systematic monitoring by means of the community, it is doable to ensure the output interval. This makes the mannequin immune to small inputs.
Randomized Smoothing
Alternatively, randomized smoothing is one other method that entails including random noise to inputs. It additionally consists of statistical strategies to ensure robustness in opposition to identified assaults and potential ones. The diagram under describe the method of randomized smoothing.
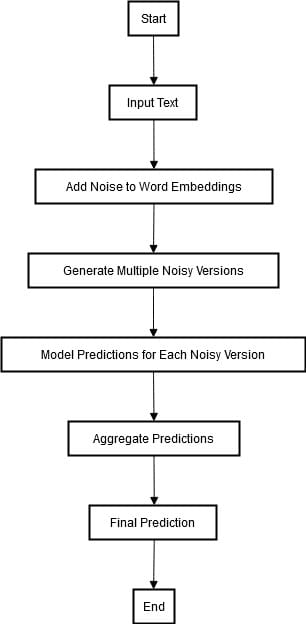
In randomized smoothing, random noise is added to the phrase embeddings of a specific enter textual content to get a number of perturbed variations of the textual content. Afterward, we combine every noisy model into the mannequin and produce an output for every of them.
These predictions are then mixed, normally by a majority voting or likelihood averaging, to provide the ultimate constant prediction. This method ensures that the mannequin’s outputs stay steady and correct, even when the enter textual content is subjected to small adversarial perturbations. By doing so, it strengthens the robustness of the mannequin in opposition to adversarial assaults.
Sensible Use Case: Robustness in Automated Authorized Doc Assessment
A authorized tech firm decides to construct an NLP system for legal professionals that may allow them to mechanically evaluation and summarize authorized paperwork. The right functioning of this technique should be assured as a result of any error might result in authorized and monetary penalties.
Use Case Implementation
- Drawback: The system should be sturdy in opposition to adversarial inputs, together with sentences or phrases which are supposed to idiot the mannequin into offering defective interpretations or summaries.
- Resolution: Utilizing certification-based protection mechanisms to make sure that the mannequin stays dependable and safe.
Interval Sure Propagation
Interval sure propagation is included into the NLP mannequin of the authorized tech firm. When analysing a authorized doc, the mannequin performs mathematical calculations to compute the intervals for each portion of the textual content. Even when some phrases or phrases have been barely pertubed(for instance, due to typo errors, or slight shifts in that means), the calculated interval will nonetheless fall right into a reliable vary.
Exemple: If the unique phrase is “contract breach,” a slight perturbation would possibly change it to “contrct breach.” The interval bounds would ensure that the mannequin is aware of that this phrase continues to be associated to “contract breach.”
Linear Leisure
The corporate approximate the nonlinear elements of the NLP mannequin utilizing the linear rest method. For instance, the complicated interactions between authorized phrases are simplified into linear segments, that are simpler to confirm for robustness.
Exemple: Phrases resembling ‘indemnity’ and ‘legal responsibility’ would possibly work together in complicated methods inside a doc. Linear rest approximates these interactions into less complicated linear segments. This helps make sure that slight variations or typos of those phrases resembling utilizing ‘indemnity’ to ‘indemnityy’ or ‘legal responsibility’ to ‘liabilitty’ do not mislead the mannequin.
Randomized Smoothing
- Software: The corporate makes use of randomized smoothing by including some random noise to the enter authorized paperwork throughout information preprocessing. For instance, small variations within the wording or phrasing are included with a view to clean out the choice boundaries of the mannequin.
- Statistical Evaluation: Statistical evaluation is carried out on the mannequin’s output to substantiate that whereas noise has been included, the elemental authorized interpretations/summaries usually are not affected.
Exemple: Throughout preprocessing, phrases like “settlement” is likely to be randomly assorted to “contract” or “understanding.” Randomized smoothing ensures these variations don’t have an effect on the elemental authorized interpretation.
This method facilitates the mitigation of unpredictable or substantial adjustments in mannequin output ensuing from small enter variations (e.g., as a result of noise or minor adversarial alterations). Consequently, it enhances the mannequin’s robustness.
In contexts the place reliability is of utmost significance, resembling in self-driving vehicles or scientific diagnostic programs, interval-bound propagation affords a scientific method to ensure that the outcomes generated by a mannequin are safe and dependable underneath a spread of enter circumstances.
Conclusion
Deep studying approaches have been included into NLP and have provided wonderful efficiency with varied duties. With the rise within the complexity of those fashions, they develop into weak to adversarial assaults that may manipulate them. Mitigating these vulnerabilities is essential for bettering the soundness and reliability of the NLP programs.
This text supplied a number of protection approaches for adversarial assaults resembling adversarial training-based method, perturbation control-based method, and certification-based method. All these approaches assist to enhance the robustness of the NLP fashions in opposition to adversarial perturbations.