
{kind=link}
Deliver this undertaking to life
Machine studying fashions can not deal with categorical variables. Subsequently, if the dataset accommodates categorical variables, we have to convert them to numeric variables. There are numerous methods to transform categorical values to numbers. Every strategy has its personal tradeoffs and implications for the function set. Typically, this encoding course of makes use of the information engineering method sizzling encoding utilizing dummy variables. Let’s take a look at this system in larger element.
On this article we are going to study One-hot encoding with examples, its implementation and the way to deal with multi categorical knowledge utilizing One-hot encoding. We may also study the distinction between One-hot encoding and label encoding.
What’s One-hot Encoding?
The method of changing categorical knowledge (having knowledge represented by totally different classes) into numerical knowledge (i.e 0 and 1) is named One-hot Encoding. There may be typically a must convert the specific knowledge into numeric knowledge, so we will use One-hot Encoding as a attainable answer. Categorical knowledge is transformed into numeric knowledge by splitting the column into a number of columns. The numbers are changed by 1s and 0s, relying on which column has what worth. In every column, which might be titled with the conference “is_<colour>”, the values for every row might be binary representations of whether or not that colour characterization is current within the fruit.
For instance, right here now we have a dataset by which now we have one column ‘Fruit’, which accommodates categorical knowledge.
Authentic dataset:
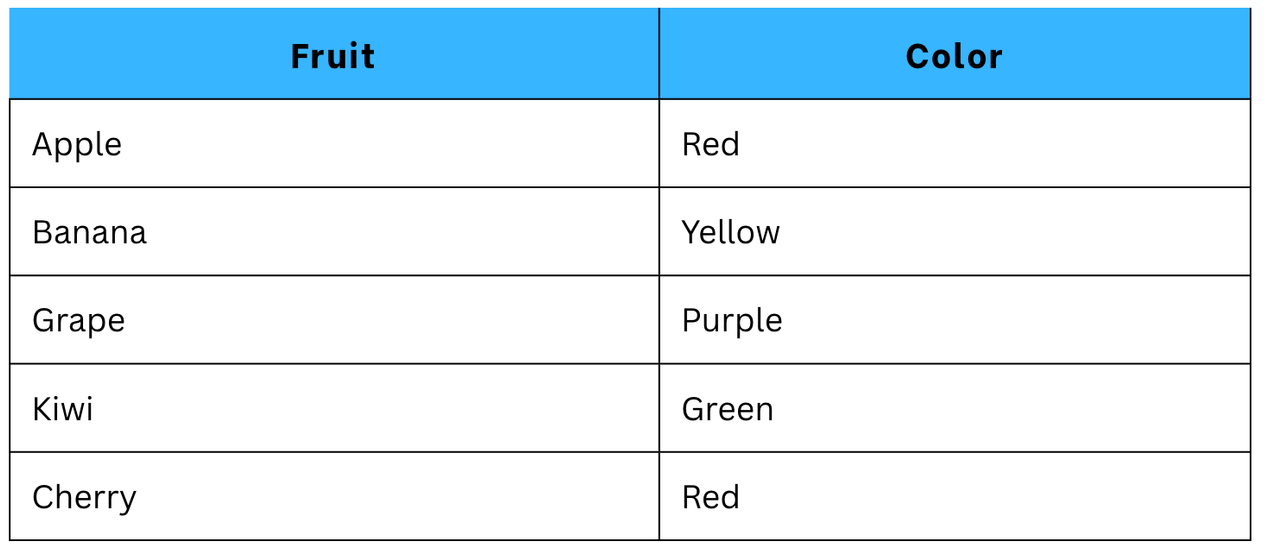
Right here now we have our authentic dataset. To get it in numerical format, now we have to transform it by making use of One-hot Encoding method. There, 4 extra columns might be added within the dataset. It is because 4 classes of labels are there.
After One-hot Encoding:
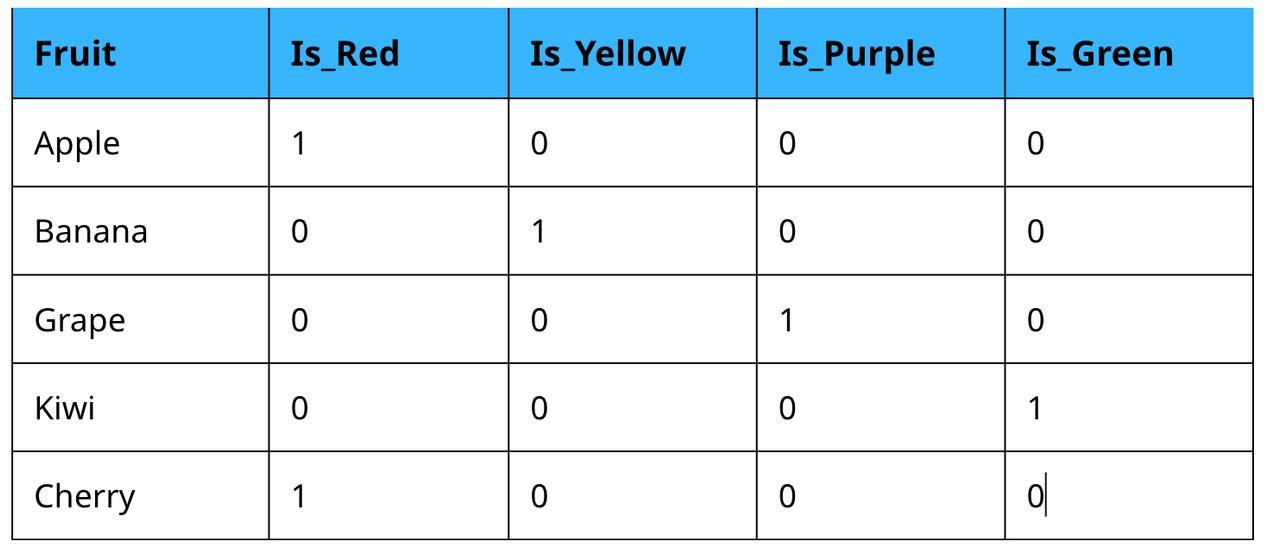
💡
Categorical Variables comprise values which can be names, labels, or strings. At first look, these variables appear innocent. Nevertheless, they’ll trigger difficulties within the machine studying fashions as they are often processed solely when some numerical significance is given to them.
What’s Label Encoding?
Until now now we have seen the way to deal with categorical knowledge. However what if our labeled knowledge have some order? And what if there are various categorical labels within the dataset?
Label encoding is the method of changing categorical options into numerical options(i.e 0, 1, 2, 3, and so forth). Label encoding entails changing every worth in a column to a quantity. Lets take a look at an instance:
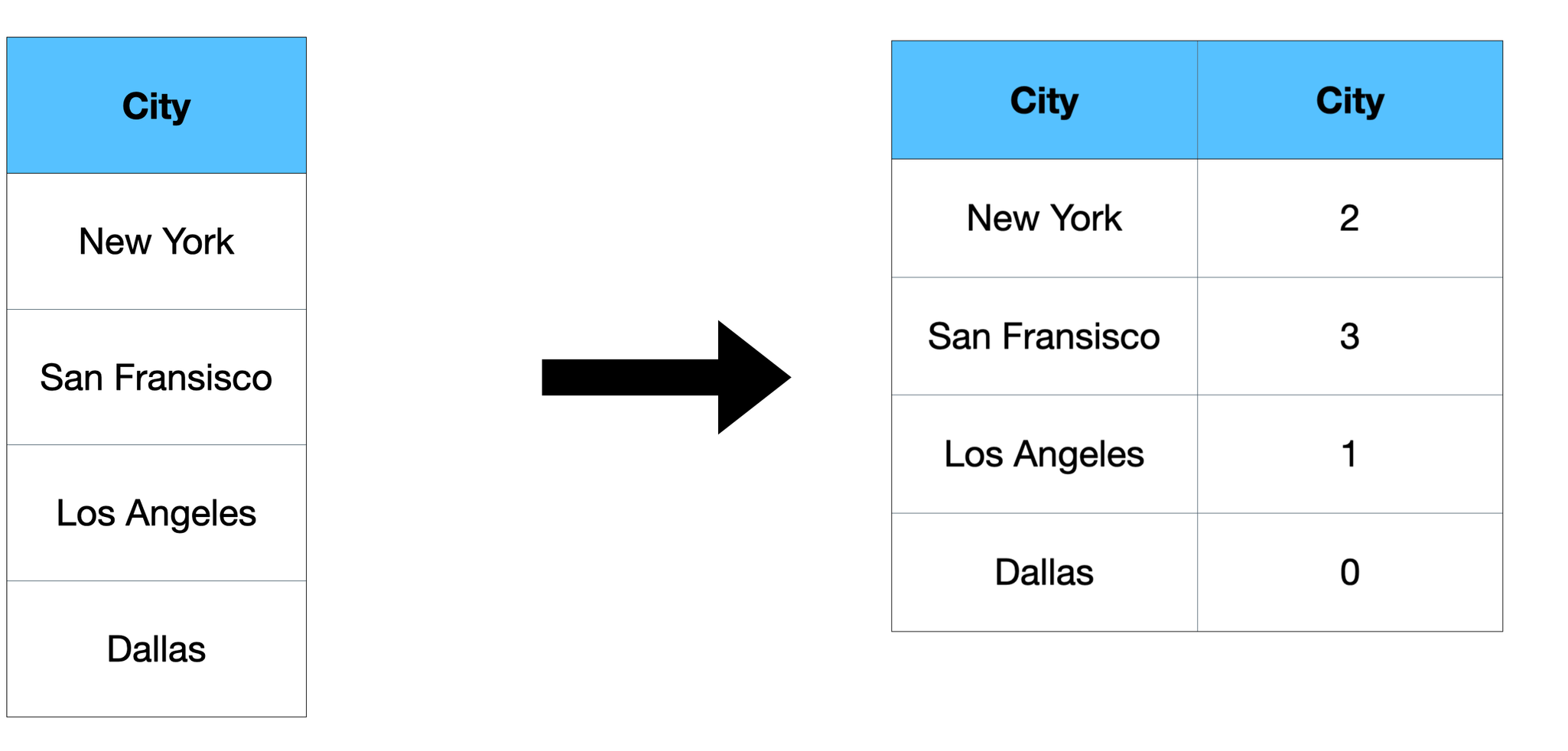
So totally different numbers are assigned to totally different metropolis names not like a separate column for every metropolis as we did in One-hot Encoding.
Subsequently in conditions like the instance above, we will think about using methods equivalent to label encoding, which might help cut back the variety of labels whereas preserving the important info within the categorical knowledge. We are going to now take a look at what label encoding is.
Distinction between One-hot encoding and Label Encoding
|
Illustration |
Represents categorical variables utilizing binary vectors, i.e. 0 and 1. |
Represents categorical variables by assigning a novel integer to every class. |
|
Variety of columns |
Will increase dimensionality with binary columns. The variety of columns equals the variety of distinctive classes. |
Ends in a single column of integers. Every integer represents a distinct class. |
|
Ordinal info |
Every class is handled as impartial, and no inherent order is imposed. |
The assigned integer values carry a significant order, indicating the relative positioning of classes. |
|
Mannequin sensitivity |
One-hot encoding is especially advantageous for fashions that may effectively deal with high-dimensional knowledge. Examples of such fashions embody determination bushes, random forests, and deep studying fashions |
Label encoding is appropriate for algorithms, like determination bushes or linear regression, that may naturally interpret and make the most of the ordinal info encoded in integers. |
When to make use of One-Scorching encoding and Label Encoding?
The info coding methodology is chosen accordingly. For instance, within the instance above, we encoded numerous state names into numeric knowledge. This categorical knowledge has no relationship between rows. Then we will use Label encoding.
Label encoders are used when:
- One-hot encoding may be reminiscence intensive, so use this system when the variety of classes may be very giant.
- Order doesn’t matter for categorical features.
Scorching encoders are used when:
- For categorical options, when label order isn’t vital.
- Variety of labels is much less. As for every label, there might be a separate column.
- Stopping machine studying fashions from incorrectly assuming an order amongst categorical options.
Dummy Variable Lure
The Dummy Variable Lure happens when totally different enter variables completely predict one another – resulting in multicollinearity.
Multicollinearity happens when two or extra impartial variables in a regression mannequin are extremely correlated. As now we have seen within the above instance, for each label we can have a separate column. These newly created binary options are known as dummy variables. That is additionally known as dummy encoding. The variety of dummy variables is set by the variety of classes current. It might sound a bit of difficult. However don’t be concerned, we’ll clarify it with an instance.
As an example now we have a dataset within the “Nation” class that additionally contains numerous nations equivalent to India, Australia, Russia, and America. Inside these, now we have three labels/classes within the ‘City’ column, so we can have three columns for 3 totally different dummy variables. These columns are ‘monroe township’, ‘robinsville’, ‘west windsor’.
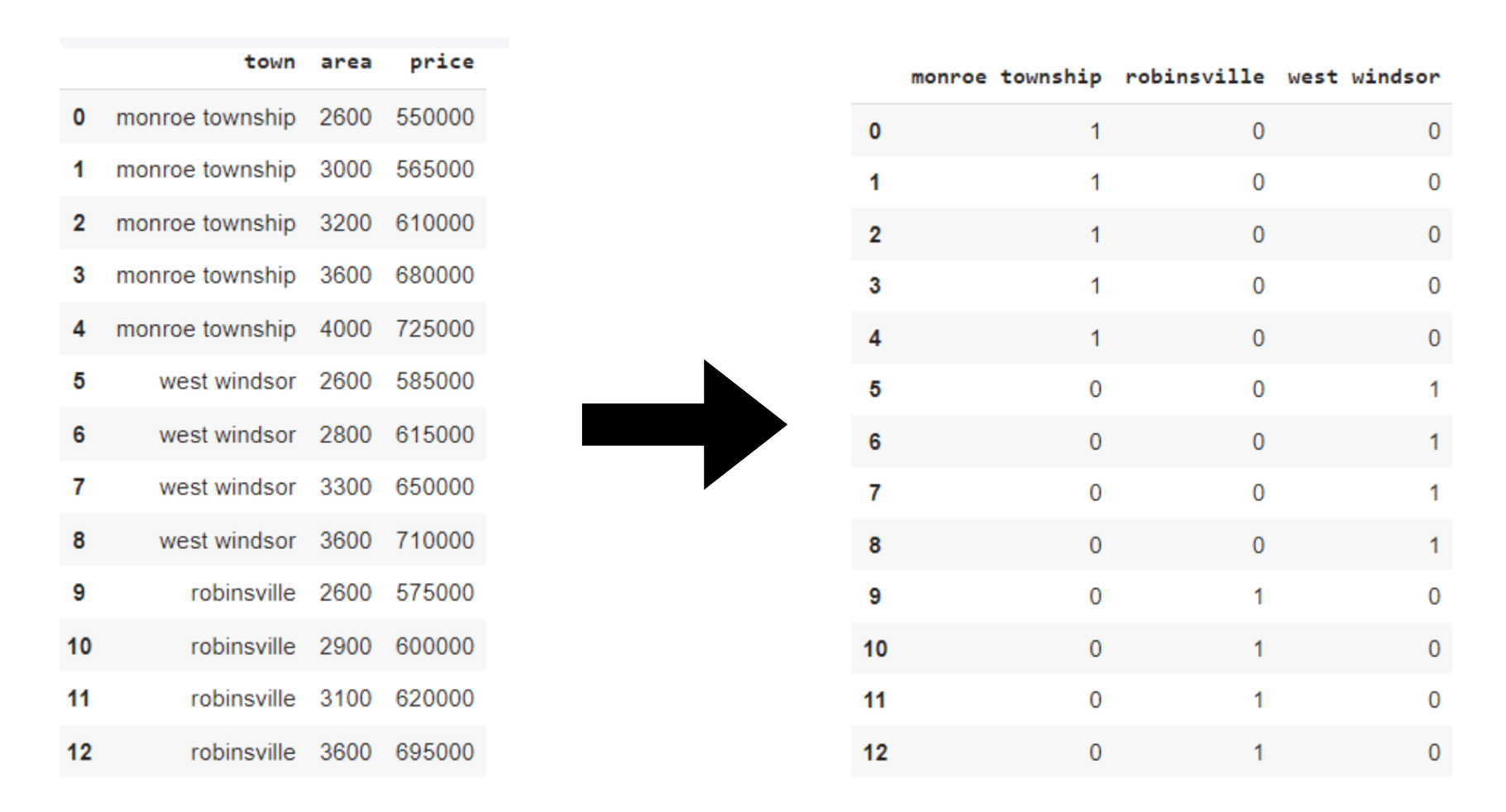
Then merge these three columns with the unique dataset. As now we have totally different dummy options representing the identical info because the ‘city’ column, so to take away redundancy, we will drop the ‘city’ column.
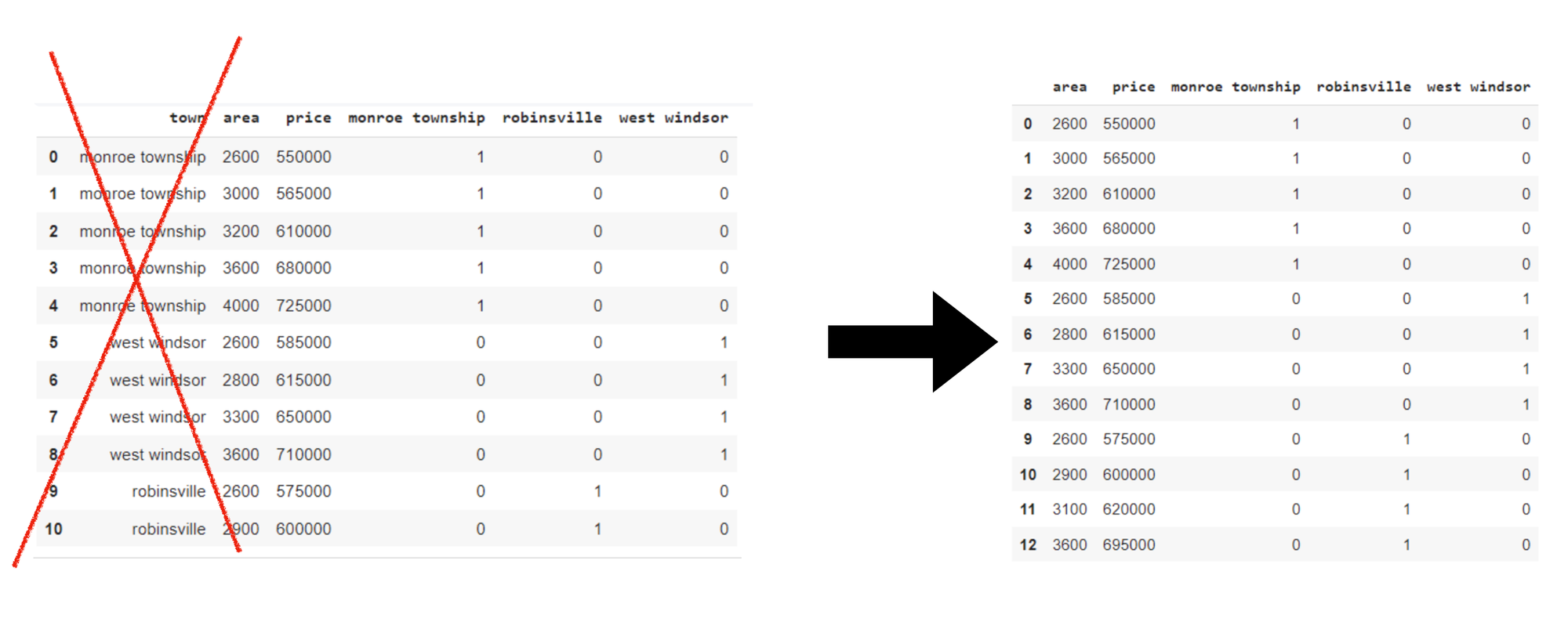
On this instance, sure columns can introduce points with creating dummy variables. This may be known as a dummy variable lure. To keep away from a dummy variable lure, we drop the ‘west windsor’ column right here. That is accomplished to stop multicollinearity. Will dropping columns result in vital info loss? The reply is often NO. Even when now we have deleted ‘west windsor’. We will nonetheless get the details about it from the remaining variables.
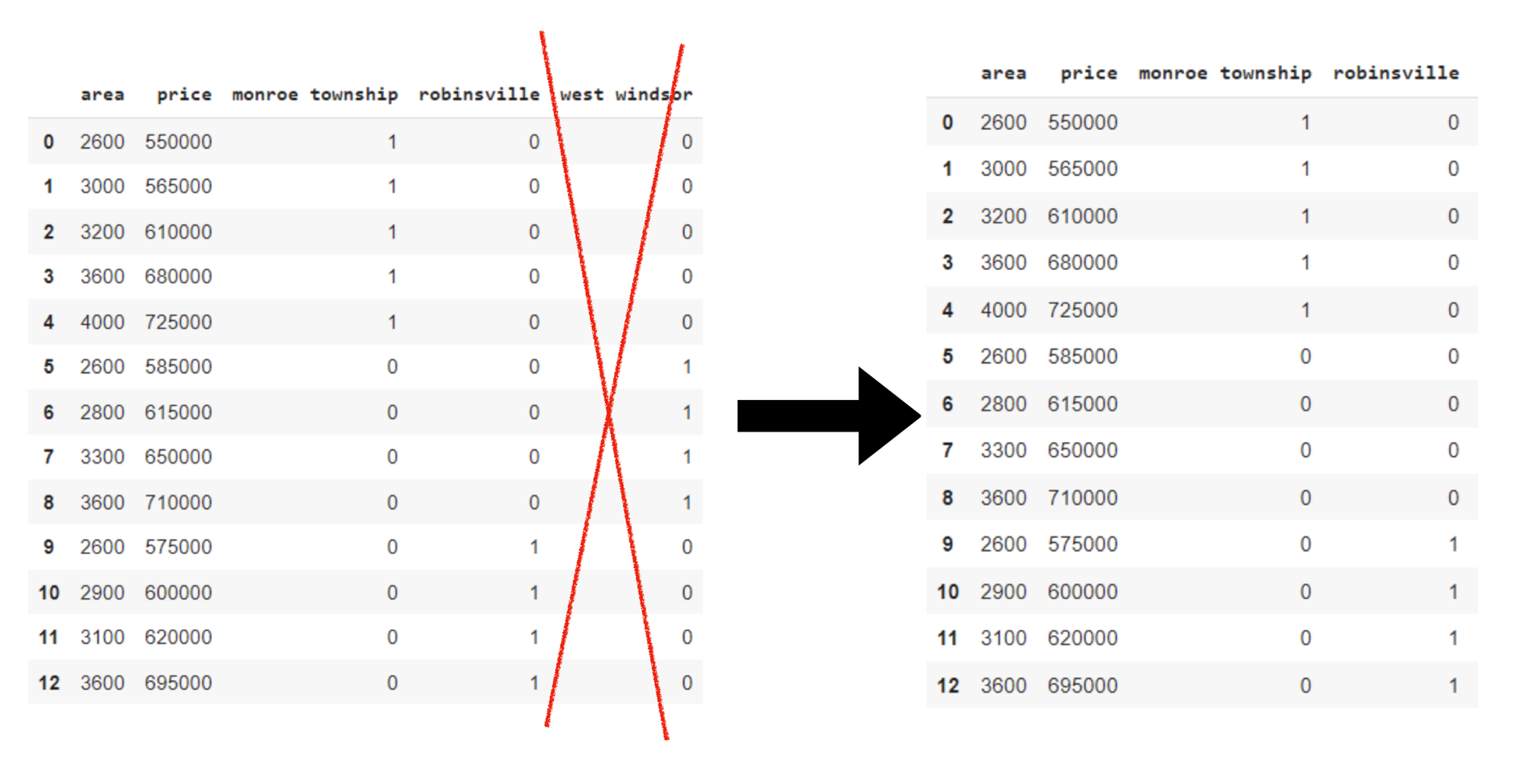
Let’s now implement the instance above instance. Suppose we need to predict the home worth. We’re utilizing the ‘residence worth.csv’ dataset (accessible on Github) by which ‘City’ is a categorical function, which now we have to transform to a numerical function/variable.
import pandas as pd
df = pd.read_csv("residence worth.csv") # loading the dataset
dummies = pd.get_dummies(df.city)
merged = pd.concat([df,dummies],axis=1) # merging dummy variable
remaining = merged.drop(['town'], axis=1) # merging the ‘City’ column
remaining = remaining.drop(['west windsor’], axis=1) # dropping anybody dummy variable.Right here dropping ‘west windsor’Rationalization: Dummy variables for the city column is created. Then, dummy variable columns are added to the top of your authentic DataFrame. To keep away from multicollinearity, one of many dummy variable columns, ‘west windsor’ is dropped.
💡
We will drop any dummy variable column we would like.
How One-hot Encoding handles Multi-categorical knowledge?
Does One-hot encoding deal with multi-labeled knowledge? The reply is YES. Now we are going to see how. Suppose 200 classes are current in a function then solely these 10 classes that are the highest 10 repeating classes might be chosen and one-hot encoding is utilized to solely these classes.
After making use of One-hot encoding we are going to delete one column to stop dummy variable trapping and can have 9 classes.
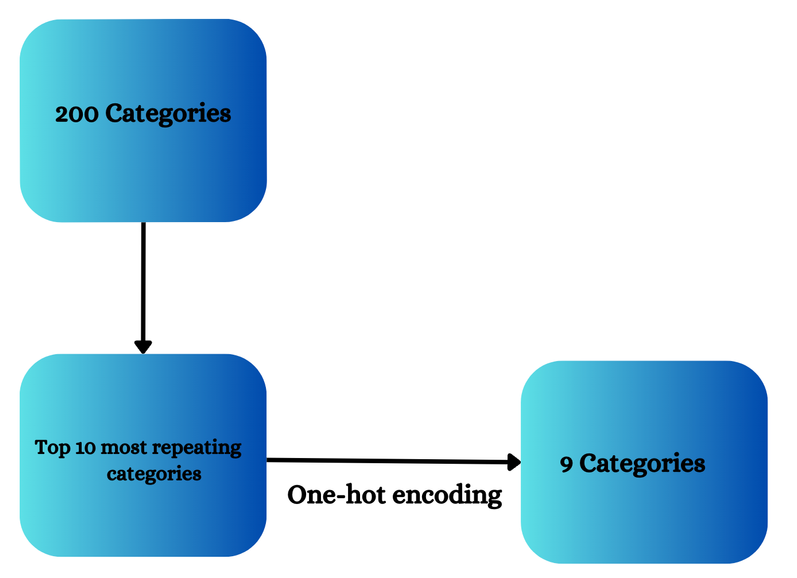
Now we are going to see this may be carried out with a sensible instance. Now we have taken mercedesbenz.csv (accessible on Github). Now we have chosen this dataset because it accommodates a number of classes.
import pandas as pd
import numpy as np
df = pd.read_csv('mercedesbenz.csv', usecols=['X1', 'X2'])
df.head()
counts = df['X1'].value_counts().sum() # Counting variety of labels for ‘X1’ column
top_10_labels = [y for y in df.X1.value_counts().sort_values(ascending=False).head(10).index] # checking the highest 10 labels
df.X1.value_counts().sort_values(ascending=False).head(10) # arranging the labels in ascending order
df=pd.get_dummies(df['X1']).pattern(10) #making use of One-hot encodingRationalization: On this X1 and X2 columns comprise a number of labels.So first we are going to test the variety of labels and what number of occasions they’re repeating. Organize them in ascending order after which apply One-hot encoding.
Project: Attempt changing the opposite categorical options of X2 column to numerical options utilizing one-hot encoding (I solely transformed X1 column options). Attempt implementing chosen algorithm and test its prediction accuracy.
Demo
Deliver this undertaking to life
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# Learn the dataset
df = pd.read_csv("residence worth.csv")
# One-Scorching Encoding
dummies = pd.get_dummies(df['town'])
merged_one_hot = pd.concat([df, dummies], axis=1)
final_one_hot = merged_one_hot.drop(['town'], axis=1)
final_one_hot = final_one_hot.drop(['robinsville'], axis=1)
# Label Encoding
label_encoder = LabelEncoder()
df['town_encoded'] = label_encoder.fit_transform(df['town'])
final_label_encoded = df.drop(['town'], axis=1)
# Separate options and goal for One-Scorching Encoding
X_one_hot = final_one_hot.drop('worth', axis=1)
y_one_hot = final_one_hot['price']
# Separate options and goal for Label Encoding
X_label_encoded = final_label_encoded.drop('worth', axis=1)
y_label_encoded = final_label_encoded['price']
# Cut up the information into prepare and take a look at units for One-Scorching Encoding
X_train_one_hot, X_test_one_hot, y_train_one_hot, y_test_one_hot = train_test_split(X_one_hot, y_one_hot, test_size=0.2, random_state=42)
# Cut up the information into prepare and take a look at units for Label Encoding
X_train_label_encoded, X_test_label_encoded, y_train_label_encoded, y_test_label_encoded = train_test_split(X_label_encoded, y_label_encoded, test_size=0.2, random_state=42)
# Mannequin utilizing One-Scorching Encoded knowledge
model_one_hot = LinearRegression()
model_one_hot.match(X_train_one_hot, y_train_one_hot)
predictions_one_hot = model_one_hot.predict(X_test_one_hot)
score_one_hot = r2_score(y_test_one_hot, predictions_one_hot)
# Mannequin utilizing Label Encoded knowledge
model_label_encoded = LinearRegression()
model_label_encoded.match(X_train_label_encoded, y_train_label_encoded)
predictions_label_encoded = model_label_encoded.predict(X_test_label_encoded)
score_label_encoded = r2_score(y_test_label_encoded, predictions_label_encoded)
# Examine outcomes
print("R-squared rating for One-Scorching Encoded knowledge:", score_one_hot)
print("R-squared rating for Label Encoded knowledge:", score_label_encoded)
Rationalization:
On this code pattern, we’re preprocessing the specific options accessible in ‘residence worth’ dataset. Now we have taken the identical instance (defined above), in order that we will simply relate to it. Each One-hot encoding and label encoding are used. We carried out One-hot encoding and did the next:
- Dummy variables are created
- Merged with the unique dataset
- Sure columns are dropped to keep away from multicollinearity
Label encoding is utilized utilizing scikit-learn’s LabelEncoder, introducing a brand new ‘town_encoded’ column In label encoding the next steps are carried out:
- Launched a brand new ‘town_encoded’ column
- Information is cut up into dependent and impartial variables for each encoding strategies
- Prepare take a look at cut up is carried out (for each One-hot encoding and label encoding)
Comparability for One-hot encoding and label encoding is carried out by making use of Linear regression fashions educated on each one-hot encoded and label-encoded datasets, and their predictive efficiency is evaluated utilizing R-squared scores.
Closing ideas
Congratulations on making it to the top! We will need to have understood what one-hot encoding is, why it’s used, and the way to use it. One-hot and label encoding are the methods to preprocess the information.
These two are the extensively used methods, so now we have to resolve which method to implement for every kind of information: One-hot or label encoding. I hope this text helped we in studying One-hot encoding.