
{kind=link}
Deliver this challenge to life
What is best than Llama 1? LLama 2. What’s even higher than LLama 2? LLama 3. Meta lately introduced LLama 2, the next-generation state-of-the-art open-source giant language mannequin.
Llama 3 now options superior language fashions with 8B and 70B parameters. These fashions have confirmed to excel throughout numerous duties and supply higher reasoning capabilities. The mannequin has been open-sourced for industrial makes use of and for the neighborhood to innovate in AI purposes, developer instruments, and extra. This text explores the mannequin’s capabilities utilizing Paperspace’s highly effective GPUs.
The Llama 3 releases 4 LLM fashions by Meta, constructed on the Llama 2 framework. These fashions are available two sizes: 8B and 70B parameters, every that includes base (pre-trained) and instruct-tuned variations. They’re designed to run easily on completely different client {hardware} varieties and boast a context size of 8K tokens.
The unique analysis paper has but to be launched. Nonetheless, Meta claims to launch the paper quickly.
LLama 3 Enhancements
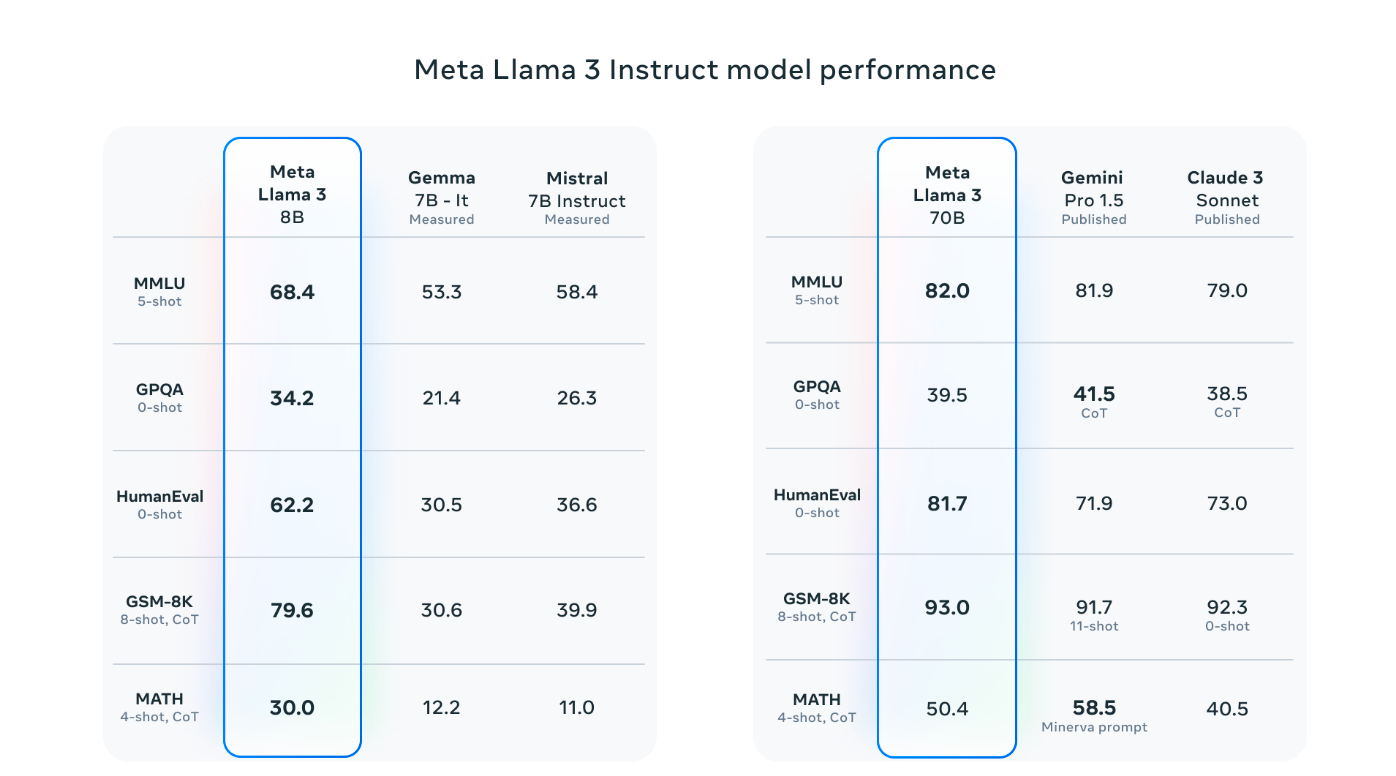
The most recent Llama 3 fashions with 8B and 70B parameters are a substantial step ahead from Llama 2, setting a brand new commonplace for big language fashions. They’re the highest fashions of their class, thanks to higher pretraining and fine-tuning strategies. The post-training enhancements have considerably decreased errors and improved the fashions’ efficiency at reasoning, producing code, and following directions. Briefly, Llama 3 is extra superior and versatile than ever.
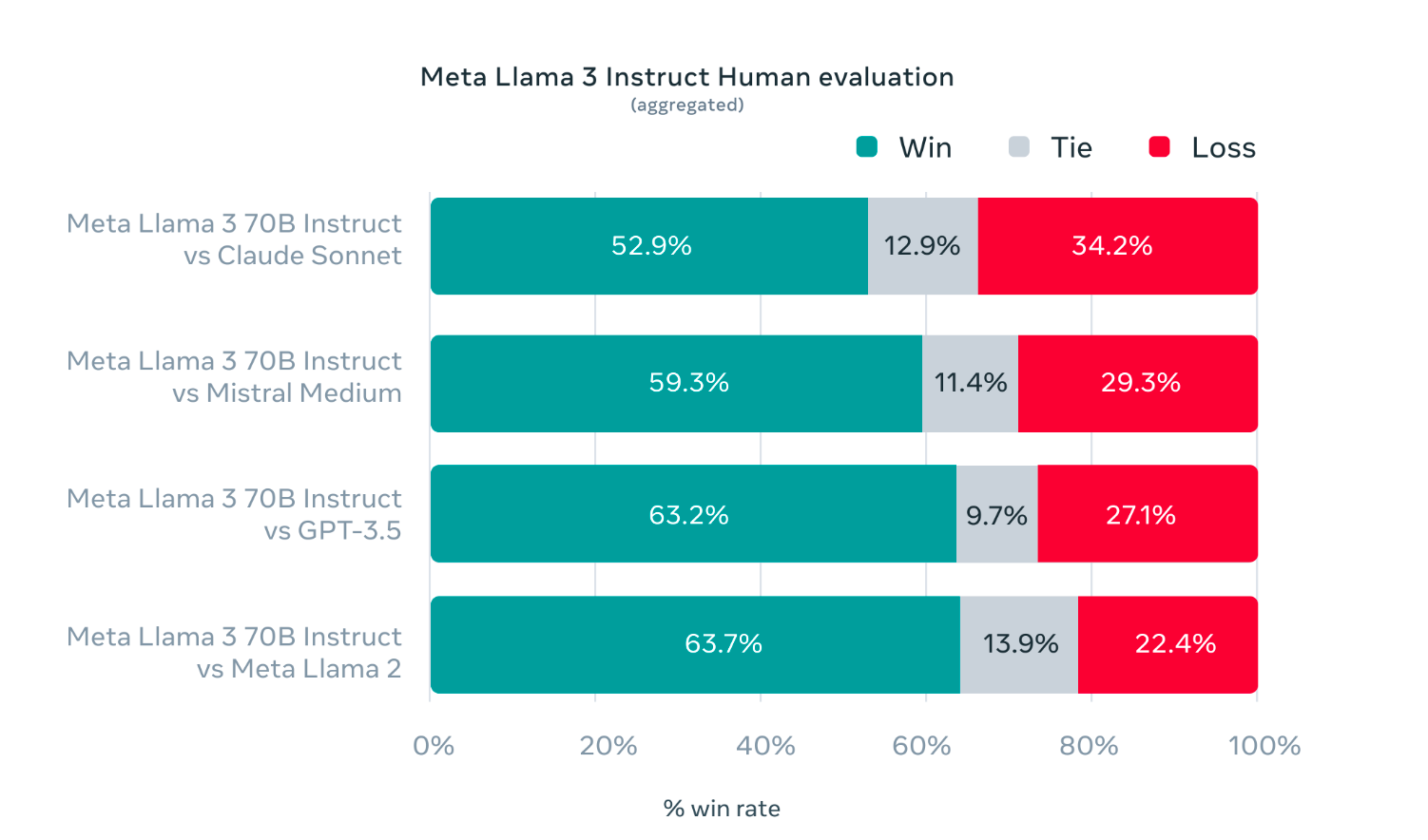
Whereas creating Llama 3, the primary focus was mannequin optimisation for real-life conditions. A top-notch analysis set was created with 1,800 prompts masking 12 important duties: advice-seeking, coding, and summarization. Additional, the validation knowledge has been used privately to forestall mannequin overfitting. Human evaluations evaluating Llama 3 to different fashions present promising outcomes throughout numerous duties and situations.
To boost Llama 3’s capabilities, Meta targeted on scaling up pretraining and refining post-training methods.
Scaling up pre-training concerned creating exact scaling legal guidelines to optimize knowledge leakage and compute utilization. Surprisingly, even after coaching on large quantities of knowledge—as much as 15 trillion tokens—the fashions continued to enhance. Varied parallelization strategies and custom-built GPU clusters have been mixed for environment friendly coaching and boosting effectivity by thrice in comparison with Llama 2.
For instruction fine-tuning, completely different methods like supervised fine-tuning and desire optimization have been thought of. Additional, cautious curation of coaching knowledge and studying from desire rankings considerably improved the fashions’ efficiency, particularly in reasoning and coding duties. These developments enable the fashions to higher perceive and reply to complicated queries.
Mannequin Structure
In designing Llama 3, a regular decoder-only transformer setup was put in. In comparison with Llama 2, an environment friendly tokenizer with a vocabulary of 128K tokens helped to spice up the efficiency. Plus, to make Llama 3 fashions quicker throughout inference, grouped question consideration (GQA) throughout completely different sizes was launched. Throughout coaching, sequences of 8,192 tokens and a masking approach to keep up consideration inside doc boundaries have been used.
Creating the most effective language mannequin begins with a top-quality coaching dataset. For Llama 3, over 15 trillion tokens have been curated from publicly accessible sources—seven instances bigger than what was used for Llama 2. This dataset even consists of 4 instances extra code. This mannequin goals for multilingual use by together with over 5% non-English knowledge, masking 30 languages, though we anticipate English will nonetheless outperform others.
To take care of high quality, sturdy data-filtering pipelines are constructed, additionally utilizing strategies like heuristic filters and textual content classifiers elevated the mannequin efficiency. By way of in depth experimentation, researchers guarantee Llama 3 performs properly throughout numerous duties, from trivia to coding and past.
LLama 3 Demo
Deliver this challenge to life
Earlier than beginning, be sure to get entry to the mannequin “meta-llama/Meta-Llama-3-70B” on huggingface.co
To make use of Llama 3 we are going to first begin by upgrading the transformers bundle
#improve the transformer bundle
pip set up -U "transformers==4.40.0" --upgrade
Subsequent, run the next code snippet. The Hugging Face weblog put up states that the mannequin sometimes requires about 16 GB of RAM, together with GPUs resembling 3090 or 4090.
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
mannequin="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={"torch_dtype": torch.bfloat16},
machine="cuda",
)
pipeline("Hey how are you doing at this time?")
💡
In the event you obtain the error “RuntimeError: cutlassF: no kernel discovered to launch!”, attempt the code under and run the cell once more.
torch.backends.cuda.enable_mem_efficient_sdp(False)
torch.backends.cuda.enable_flash_sdp(False)‘generated_text’: “Hey how are you doing at this time? I hope you are having an amazing day up to now! I simply”
Few issues to bear in mind right here,
- In our instance case, we’ve got used ‘bfloat16’ to load the mannequin. Initially, Meta used ‘bfloat16.’ Therefore, it is a beneficial technique to run to make sure the most effective precision or to conduct evaluations. For real-world instances, attempt
float16, which can be quicker relying in your {hardware}. - One may also mechanically compress the mannequin, loading it in both 8-bit or 4-bit mode. Operating in 4-bit mode requires much less reminiscence, making it appropriate with many consumer-grade graphics playing cards and fewer highly effective GPUs. Under is an instance code snippet on load the pipeline with 4-bit mode.
pipeline = transformers.pipeline(
"text-generation",
mannequin="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)The Way forward for Llama 3
Whereas the present 8B and 70B fashions are spectacular, Meta researchers are engaged on even larger ones with over 400B parameters. These fashions are nonetheless in coaching. Within the coming months, they are going to have thrilling new options like multimodality, multilingual dialog talents, longer context understanding, and general stronger capabilities.

Conclusion
With Llama 3, Meta has set to construct the most effective open fashions which might be on par with the most effective proprietary fashions accessible at this time. The most effective factor about Meta’s Llama 3 is its open-source ethos of releasing early and sometimes to allow the neighborhood to entry these fashions whereas they’re nonetheless creating. The launched text-based fashions are the primary within the Llama 3 assortment of fashions. As said by Meta, their predominant aim is to make Llama 3 multilingual and multimodal, have a extra prolonged context, and proceed to enhance general efficiency throughout core LLM capabilities resembling reasoning and coding.
We will’t wait to see what’s subsequent within the GenAI subject.