
{kind=link}
Introduction
Textual content classification or categorization (TC) is a elementary subtask in all NLU duties. Textual data comes from quite a lot of locations, together with social media, digital communications, and buyer interactions that contain questions and solutions. Textual content is a superb supply of knowledge in itself, however it may be tough and time-consuming to attract conclusions from it because of its lack of group.
Textual content classification (TC) could be carried out both manually or routinely. Knowledge is more and more obtainable in textual content kind in all kinds of functions, making computerized textual content classification a strong software. Automated textual content categorization typically falls into considered one of two broad classes: rule-based or synthetic intelligence-based. Rule-based approaches divide textual content into classes in response to a set of established standards and require in depth experience in related matters. The second class, AI-based strategies, are skilled to establish textual content utilizing information coaching with labeled samples.
Limitations of conventional approaches
Studying, understanding, and deciphering make up the majority of NLU’s work. Step one is to manually extract sure options from any doc, and the second step is to make use of these options to coach a classifier and make a prediction.
One sort of manually extracted characteristic is a Bag of Phrases (BoW), and well-known classification strategies embrace Naive Bayes, Logistic Regression, Help Vector Machines, and Random Forests. This multi-step course of has quite a few drawbacks; counting on the manually collected options requires complicated characteristic evaluation to acquire correct outcomes. Extra work is required to generalize this strategy to different duties as a result of it depends closely on native area data for characteristic engineering.
As well as, the predetermined options of those fashions forestall them from making the most of the huge quantities of coaching information obtainable.
To beat these limitations, researchers have turned to neural community approaches. As a substitute of counting on manually extracted options, these strategies concentrate on a machine studying approach that maps textual content to a low-dimensional steady characteristic vector.
Evolution of deep studying fashions in NLU
- Latent Semantic Evaluation (LSA) was first launched in 1989 by Deerwester et al. It has a protracted historical past as one of many first embedding fashions. When skilled on the 200K phrase corpus, LSA is a linear mannequin with lower than 1,000,000 parameters. The mannequin has sure shortcomings, reminiscent of the shortcoming to completely exploit the dimensional data within the vector illustration and the statistical properties of an LSA house when used as a measure of similarity.
- In 2000, Bengeo et al. introduced the primary pure language mannequin. It makes use of 14 million phrases for coaching and relies on a feed-forward neural community. Nevertheless, the efficiency of those early embedding fashions is inferior to that of extra typical fashions that depend on manually extracted options. This case shifted dramatically as bigger embedding fashions with extra in depth coaching information had been created.
- Google’s word2vec fashions, in-built 2013, are thought-about state-of-the-art for a lot of NLU functions, having been skilled on a corpus of 6 billion phrases.
- In 2017, AI2 and the College of Washington labored collectively to develop a three-layer bidirectional LSTM contextual embedding mannequin with 93 million parameters and 1 billion phrases. The Elmo mannequin outperforms the word2vec technique by a large margin as a result of to its potential to consider context.
- In 2018, OpenAI has been leveraging Google’s Transformer, a ground-breaking neural community structure, to create embedding fashions. Giant-scale mannequin coaching on TPU advantages significantly from the transformer’s reliance on consideration.
- The unique Transformers-based strategy, GPT, continues to be extensively used right now for textual content producing duties. Based mostly on the bidirectional transformer, Google developed BERT in 2018. BERT is a 340M parameter mannequin that’s skilled on 3.3B phrases. The newest mannequin from OpenAI, GPT-3, maintains this pattern towards bigger fashions with extra coaching information.
- It has 170 billion parameters, in comparison with 600 billion in Google’s Gshard. Microsoft’s T-NLG has 17 billion parameters, whereas NVIDIA’s Megatron has 1 trillion coaching parameters; each are well-liked fashions primarily based on generative pre-trained transformer approaches.
- Whereas some researchers have proven that these large-scale fashions carry out brilliantly on sure NLU duties, others have discovered that they lack language understanding and are therefore unfit for a lot of key functions.
Feed-forward networks primarily based fashions
Feed-forward networks are a sort of easy DL mannequin used to symbolize textual content. In these frameworks, phrases are handled because the constructing blocks of textual content. These fashions use word2ve or GloVe to be taught a vector illustration of every phrase. One other classifier, fastText, was introduced by Joulin et al. To be taught extra in regards to the native phrase order, fastText makes use of a set of n-grams as an extra characteristic. This strategy is efficient as a result of it offers comparable outcomes to strategies that take phrase order into consideration. The unsupervised algorithm doc2vec was developed by Le and Mikolove to be taught fixed-length characteristic representations of variable-length textual content.
RNN-based fashions
In RNN-based fashions, the textual content is usually interpreted as a phrase order. Capturing phrase relationship between sentences and textual content construction is the principle purpose of an RNN-based mannequin for textual content categorization. Nevertheless, common feed-forward neural networks outperform RNN-based fashions. One sort of RNN designed to be taught long-term relationships between phrases and sentences is the Lengthy Quick-Time period Reminiscence (LSTM) mannequin. The values are saved in a reminiscence cell that has an enter, an output, and a overlook gate to maintain them secure for a sure period of time. LSTM fashions use this reminiscence cell to repair the vanishing gradient and gradient boosting points of normal RNNs.
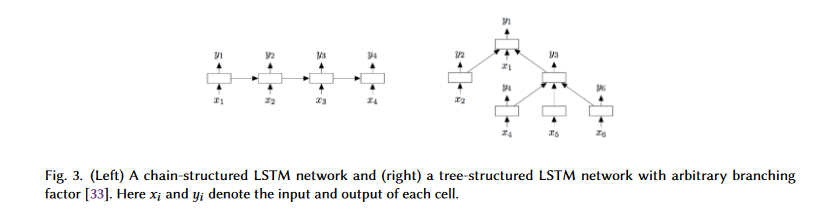
By extending the LSTM mannequin to incorporate tree-structured community varieties, Tai et al. create a mannequin able to studying detailed semantic representations. Since actual language shows syntactic options that might naturally be part of phrases to phrases, the authors imagine that Tree-LSTM is simpler than the chain-structured LSTM for NLP functions. Two duties, sentiment classification and semantic similarity prediction, are used to confirm Tree-LSTM’s effectivity. Mannequin architectures are proven in Fig. 3.
Fashions primarily based on CNN
In contrast to RNNs, that are skilled to acknowledge patterns over time, CNNs are skilled to seek out patterns in house. Whereas RNNs excel at pure language processing (NLP) duties that require an understanding of long-range semantics, reminiscent of RQA-POS tagging, CNNs excel at duties the place the notion of native and location-independent patterns in textual content is crucial. These repeated occurrences could also be key phrases used to precise a specific sentiment.
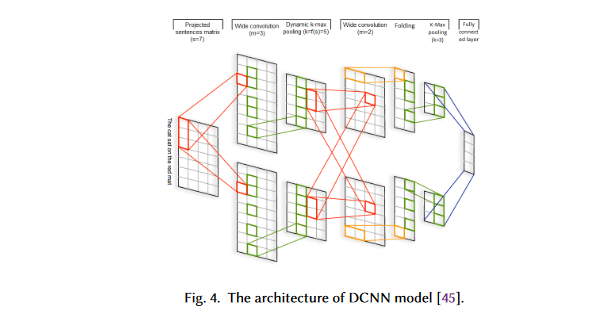
This has led to the widespread adoption of CNNs as a mannequin for general-purpose textual content categorization. A novel CNN-based textual content categorization has been proposed by Kalchbrenner et al. Relying on the pooling technique used, the mannequin could be known as a dynamic Okay-max pooling mannequin.
The primary layer of a DCNN builds a sentence matrix by embedding every phrase within the sentence. A convolutional construction that mixes massive convolutional layers with dynamic convolutional settings is used within the second stage of the method.
Utilizing the dynamic Okay-max pooling layers, we construct a sentence-wide characteristic map that captures completely different levels of relatedness between phrases.
Based mostly on the sentence dimension and the convolution hierarchy degree, the pooling parameter is chosen dynamically at runtime.
Capsule neural network-based fashions
CNN’s image and textual content classification is carried out by a number of layers of convolutions and pooling. Whereas pooling strategies are capable of establish vital options and cut back the computational price of convolution processes, they’re unable to account for spatial data and should result in misclassification of objects primarily based on their orientation or proportion.
To get across the points associated to pooling, Hinton et al. proposed a novel technique known as capsule networks (CapsNets). The exercise vector of a gaggle of neurons referred to as a capsule has a number of of the hallmarks of a block or partial block. A block’s likelihood of existence is represented by the vector’s size, and the block’s attributes are represented by the vector’s orientation.
In distinction to max-pooling in CNNs, which solely makes use of a subset of the obtainable data for classification, capsules “route” every capsule within the backside layer to its finest father or mother capsule within the higher layer. Many strategies exist for implementing routing, together with dynamic routing by settlement.. A number of strategies, such because the Expectation-Maximization algorithm and dynamic routing by settlement, may obtain this job.
Fashions with consideration mechanism
Consideration could be directed in some ways, reminiscent of specializing in particular elements of a picture or clusters of phrases in a sentence. Constructing DL fashions for NLP more and more focuses on consideration as a key idea and approach. It is a vector with some vital weights on it. Utilizing the eye vector, we are able to consider the energy of a phrase’s relationship to the opposite phrases within the sentence, after which by summing the weighted values of the eye vector, we are able to predict the goal worth.
Yang et al. [79] suggest a hierarchical consideration community for textual content classification. This mannequin has two distinctive traits: (1) a hierarchical construction that mirrors the hierarchical construction of paperwork, and (2) two ranges of consideration mechanisms utilized on the phrase and sentence-level, enabling it to attend differentially to extra and fewer vital content material when setting up the doc illustration.
Fashions primarily based on graph neural community
Whereas common texts have a sequential order, in addition they include underlying community constructions, much like parse timber, that infer their relationship primarily based on the syntax and semantic properties of sentences.
TextRank is a novel NLP mannequin primarily based on graph principle. The authors suggest {that a} textual content written in a pure language is represented as a graph G (V, E), the place V represents a set of nodes and E represents a set of edges connecting these nodes. The assorted items of textual content that make up sentences are represented by nodes. Edges will also be used to point different kinds of relationships between nodes, relying on the context by which they’re used.
DNN fashions primarily based on CNNs, RNNs, and autoencoders have been modified in recent times to take care of the complexity of graph information. Due to their effectivity, versatility, and skill to be mixed with different networks, GCNs and their offshoots have develop into fairly well-liked among the many varied kinds of GNNs.
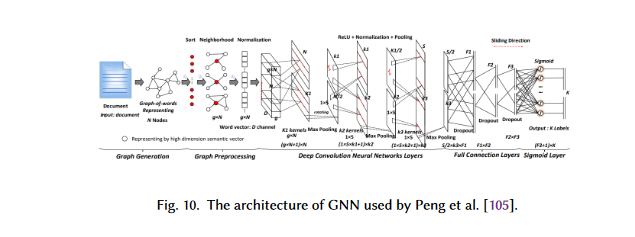
TC is a standard use case for GNNs in NLP. To deduce doc labels, GNNs use the relationships between paperwork or phrases. The graph CNN primarily based DL mannequin proposed by Peng et al. includes first remodeling textual content right into a graph of phrases after which convolving this graph utilizing graph convolution processes.
Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are two examples of extra neural community designs that may be built-in with GNN-based fashions to boost their efficiency. Coaching GNN-based fashions on massive graphs could be difficult, and the training representations are typically tough to interpret. Improved GNN-based fashions, in addition to strategies for deciphering and visualizing the discovered representations, often is the focus of future analysis on this space.
Fashions with hybrid strategies
The mix of LSTM and CNN architectures has led to the event of numerous hybrid fashions that may distinguish between international and native paperwork.
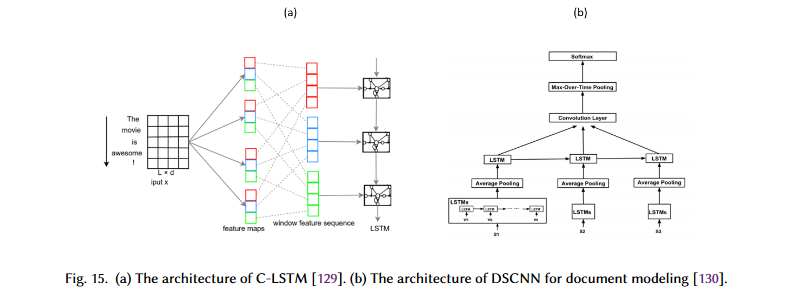
Zhou et al. got here up with the thought of a community referred to as Convolutional LSTM (C-LSTM). In C-LSTM, a CNN is used to extract a set of phrase (n-gram) representations. These representations are then fed into an LSTM community to acquire the sentence-level illustration.
For doc modeling, Zhang et al. suggest a dependency delicate CNN (DSCNN). For multi-label TC, Chen et al. use a CNN-RNN mannequin. Tang et al. use a CNN to interpret sentence representations that encode the fundamental hyperlinks between sentences. Within the hierarchical mannequin of the DSCNN, the LSTM learns the sentence vectors, that are then fed into the convolution and max-pooling layers to create the doc illustration, as proven within the determine beneath.
Fashions primarily based on transformers
A computational problem for RNNs is the sequential processing of textual content. Whereas RNNs are extra sequential than CNNs, the computational price of capturing the connection between phrases in a sentence will increase with sentence size for each kinds of networks. To beat this limitation, transformer-based fashions concurrently generate an “consideration rating” for every phrase in a sentence.
In comparison with convolutional and recurrent neural networks, transformers provide a lot higher parallelization, permitting efficient coaching of huge fashions on large quantities of knowledge on GPUs. Since 2018, a number of large-scale Transformer-based pre-trained LMs have entered the market. Transformer-based fashions use extra complicated community topologies. To raised seize the context of textual content representations, these fashions are pre-trained on bigger quantities of textual content.
Conclusion
On this artgicle, now we have speak about:
- The evolution of deep learning-based language fashions in pure language understanding.
- The Feed-forward networks primarily based fashions
- RNN-based fashions
- Capsule neural network-based fashions
- Fashions with consideration mechanismModels with consideration mechanism
- Fashions primarily based on graph neural community
- Fashions with hybrid strategies
- Fashions primarily based on transformers
References
Deep Studying Based mostly Textual content Classification: A Complete Evaluation
Deep studying primarily based fashions have surpassed classical machine studying primarily based approaches in varied textual content classification duties, together with sentiment evaluation, information categorization, query answering, and pure language inference. On this paper, we offer a complete evaluate of greater than 150 deep le…