
{kind=link}
Introduction
Creating visually partaking content material could be a time-consuming job for bloggers and creators. After crafting a compelling article, discovering the precise pictures is usually a separate problem. However what if Weblog Creation with AI may do all of it for you? Think about a seamless course of the place, alongside your writing, AI generates authentic, high-quality pictures tailor-made to your article and even supplies captions for them.
This text delves into constructing a completely automated system of weblog creation with AI for picture era and captioning, simplifying the weblog creation workflow. The strategy right here entails utilizing conventional Pure Language Processing (NLP) to summarize the article into a brief sentence, capturing the essence of your weblog. We then use this sentence as a immediate for automated picture era through Secure Diffusion, adopted by utilizing an image-to-text mannequin to create captions for these pictures.
Studying Targets
- Perceive learn how to combine AI-based picture era utilizing textual content ‘prompts’.
- Automating Weblog Creation with AI for captioning.
- Be taught the basics of conventional NLP for textual content summarization.
- Discover learn how to make the most of the Segmind API for automated picture era, enhancing your weblog with visually interesting content material.
- Acquire sensible expertise with Salesforce BLIP for picture captioning.
- Construct a REST API to automate summarization, picture era, and captioning.
This text was printed as part of the Information Science Blogathon.
What’s Picture-to-Textual content in GenAI?
Picture-to-text in Generative AI (GenAI) refers back to the technique of producing descriptive textual content (captions) from pictures. That is carried out utilizing machine studying fashions educated on massive datasets, the place the mannequin learns to determine objects, folks, and scenes in a picture and generates a coherent textual content description. Such fashions are helpful in functions, from automating content material creation to enhancing accessibility for the visually impaired.
What’s Picture Captioning?
Picture captioning is a subfield of pc imaginative and prescient the place a system generates textual descriptions for pictures. It entails understanding the contents of a picture and describing it in a method that’s significant and proper. The mannequin often combines methods from each imaginative and prescient (for picture understanding) and language modeling (for producing textual content).
Introduction to the Salesforce BLIP Mannequin
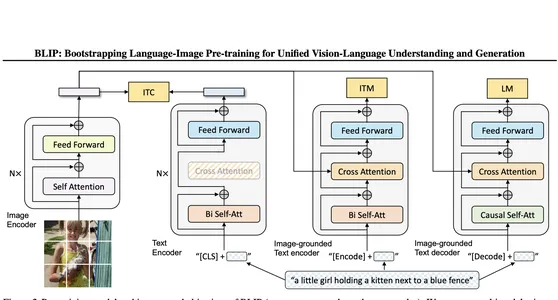
BLIP (Bootstrapping Language-Picture Pretraining) is a mannequin from Salesforce that leverages imaginative and prescient and language processing for duties like picture captioning, visible query answering, and multimodal understanding. The mannequin is educated on large datasets and is thought for its potential to generate correct and contextually wealthy captions for pictures. We’re contemplating this mannequin for our captioning. We’ll get it from HuggingFace.
What’s Segmind API?
Segmind is a platform that gives companies to facilitate Generative AI workflows, primarily by API calls. Builders and enterprises can use it to generate pictures from textual content ‘prompts’, making use of numerous fashions within the cloud with no need to handle the computational sources themselves. Segmind’s API means that you can create pictures in kinds—starting from life like to inventive—whereas customizing them to suit your model’s visible id. For this mission, we’ll use the free Segmind API to generate pictures, guaranteeing that we don’t have to fret about working picture fashions regionally. You may enroll and create an API key right here.
We might be utilizing the brand new picture mannequin from Black Forest Labs referred to as FLUX which is offered on Segmind. You will get them from hugging face diffusers or learn the docs right here.
Overview of NLP for Textual content Summarization
Pure Language Processing (NLP) is a subfield of synthetic intelligence centered on the interplay between computer systems and human (pure) language. It allows computer systems to know, interpret, and generate human language. Functions of NLP embrace textual content evaluation, sentiment evaluation, language translation, textual content era, and textual content summarization. On this mission, we’ll be utilizing NLP particularly for textual content summarization.
Why Conventional NLP and Not LLM for Textual content Summarization?
The textual content summarization on this mission will not be meant for finish customers however might be used as a ‘immediate’ for the Secure Diffusion mannequin. Conventional NLP methods, whether or not extractive or abstractive summarization, are adequate for creating image-generation ‘prompts’. In truth, even easy key phrase extraction would work. Whereas utilizing Giant Language Fashions (LLMs) may make the abstract smoother by introducing contextual understanding, it’s not mandatory on this case, because the generated abstract solely serves as a ‘immediate’. Moreover, utilizing conventional NLP saves computational prices in comparison with LLMs. Realizing when to make use of LLMs versus conventional NLP is essential to optimizing each efficiency and price.
Overview of the System:
- Textual content Evaluation: Use NLP methods to summarize the article.
- Picture Technology: Use Segmind API to generate pictures based mostly on the abstract.
- Picture Captioning: Use Salesforce BLIP to caption the generated pictures.
- REST API: Construct an endpoint that accepts article textual content or URL and returns the picture with a caption.
Step-by-Step Code Implementation
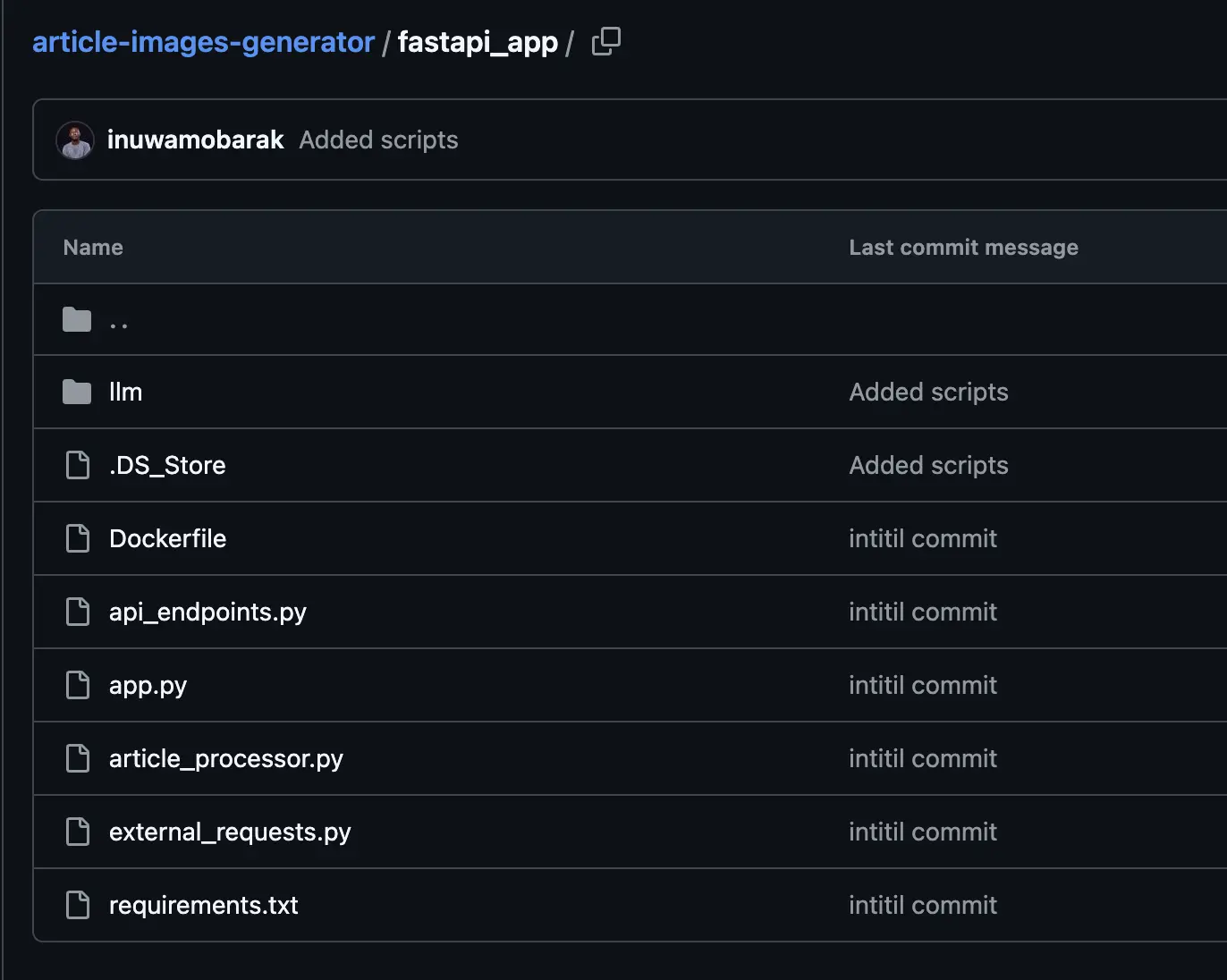
Create a folder/listing referred to as fastapi_app. Add all of the information within the screenshot beneath. The opposite folder might be created later which can maintain an optionally available UI.
Right here is your complete code on this repo.
Step 1: Set up Dependencies
Earlier than going into the principle steps, allow us to set up necessities. Now we have as much as 15 packages we have to set up so we’ll simply use a necessities.txt file to do that. Create it and add the next packages:
beautifulsoup4
lxml
nltk
fastapi
fastcore
uvicorn
pytest
llama-cpp-python==0.2.82
pydantic==2.8.2
torch
diffusers
speed up
litserve
transformers
streamlitNow go to that listing in terminal and run this command:
pip set up -r necessities.txtWe’ll begin with constructing the textual content summarizer with NLP. open the article_processor.py and import the next libraries:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from bs4 import BeautifulSoup
import urllib.request
import heapq
import reSubsequent, we have to obtain some sources for our NLP toolkit:
# Obtain required NLTK sources
nltk.obtain('stopwords')
nltk.obtain('wordnet')
nltk.obtain('punkt')
nltk.obtain('averaged_perceptron_tagger')We want a category we are able to name with our article that may do the summarization and return the abstract. I’ve added a docstring to understand what the category will do completely. Right here is the category:
class TextSummarizer:
"""
A category used to summarize textual content from a given enter.
Attributes:
----------
input_data : str
The textual content to be summarized. Could be a URL or a string of textual content.
num_sentences : int
The variety of sentences to incorporate within the abstract.
is_url : bool
Whether or not the input_data is a URL or not.
Strategies:
-------
__init__(input_data, num_sentences)
Initializes the TextSummarizer object.
check_if_url(input_data)
Checks if the input_data is a URL.
fetch_article()
Fetches the article from the given URL.
parse_article(article)
Parses the article and extracts the textual content.
calculate_word_frequencies(article_text)
Calculates the frequency of every phrase within the article.
calculate_sentence_scores(article_text, word_frequencies)
Calculates the rating of every sentence based mostly on the phrase frequencies.
summarize()
Summarizes the textual content and returns the abstract.
"""
def __init__(self, input_data, num_sentences):
self.input_data = input_data
self.num_sentences = num_sentences
self.is_url = self.check_if_url(input_data)
def check_if_url(self, input_data):
# Easy regex to verify if the enter is a URL
url_pattern = re.compile(r'^(http|https)://')
return re.match(url_pattern, input_data) will not be None
def fetch_article(self):
wikipedia_article = urllib.request.urlopen(self.input_data)
article = wikipedia_article.learn()
return article
def parse_article(self, article):
parsed_article = BeautifulSoup(article, 'lxml')
paragraphs = parsed_article.find_all('p')
article_text = ""
for p in paragraphs:
article_text += p.textual content
return article_text
def calculate_word_frequencies(self, article_text):
stopwords_list = stopwords.phrases('english')
word_frequencies = {}
for phrase in word_tokenize(article_text):
if phrase not in stopwords_list:
if phrase not in word_frequencies.keys():
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
maximum_frequency = max(word_frequencies.values())
for phrase in word_frequencies.keys():
word_frequencies[word] = (word_frequencies[word] / maximum_frequency)
return word_frequencies
def calculate_sentence_scores(self, article_text, word_frequencies):
sentence_list = sent_tokenize(article_text)
sentence_scores = {}
for despatched in sentence_list:
for phrase in word_tokenize(despatched.decrease()):
if phrase in word_frequencies.keys():
if len(despatched.break up(' ')) < 32:
if despatched not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word]
else:
sentence_scores[sent] += word_frequencies[word]
return sentence_scores
def summarize(self):
"""
Summarizes the textual content and returns the abstract.
Returns:
-------
str
The abstract textual content.
"""
if self.is_url:
# If the enter is a URL, fetch and parse the article
article = self.fetch_article()
article_text = self.parse_article(article)
else:
# If the enter will not be a URL, use the enter textual content immediately
article_text = self.input_data
# Calculate the phrase frequencies and sentence scores
word_frequencies = self.calculate_word_frequencies(article_text)
sentence_scores = self.calculate_sentence_scores(article_text, word_frequencies)
# Get the top-scoring sentences for the abstract
summary_sentences = heapq.nlargest(self.num_sentences, sentence_scores, key=sentence_scores.get)
# Be a part of the abstract sentences right into a single string
abstract = ''.be a part of(summary_sentences)
return abstractStep 2: Exterior API Name for Segmind API
Now open the exterior request and add the request to Segmind. I’ve added a docstring to understand the category higher.
import requests
class SegmindAPI:
"""
A category used to work together with the Segmind API.
Attributes:
----------
api_key : str
The API key for the Segmind API.
url : str
The bottom URL for the Segmind API.
Strategies:
-------
__init__(api_key)
Initializes the SegmindAPI object.
generate_image(immediate, steps, seed, aspect_ratio, base64=False)
Generates a picture utilizing the Segmind API.
"""
def __init__(self, api_key):
self.api_key = api_key
self.url = "https://api.segmind.com/v1/fast-flux-schnell"
def generate_image(self, immediate, steps, seed, aspect_ratio, base64=False):
# Create the info payload for the API request
information = {
"immediate": immediate,
"steps": steps,
"seed": seed,
"aspect_ratio": aspect_ratio,
"base64": base64
}
headers = {
"x-api-key": self.api_key
}
response = requests.publish(self.url, json=information, headers=headers)
if response.status_code == 200:
with open("picture.png", "wb") as f:
f.write(response.content material)
print("Picture saved to picture.png")
return response
else:
print(f"Error: {response.textual content}")
return NoneWe’ll name this class generate_image to get our article picture from Segmind API.
Step 3: Picture Caption with Blip
Since we’re loading blip from hugging face API, for simplicity, we’ll initialize it in our api_endpoints.py. However if you want you can also make it a separate file or higher nonetheless embrace it within the script for segmind API.
from fastapi import FastAPI, HTTPException
from fastapi.responses import FileResponse
from PIL import Picture
import base64
from article_processor import TextSummarizer
from external_requests import SegmindAPI
from pydantic import BaseModel
from transformers import BlipProcessor, BlipForConditionalGeneration
from llm.inference import LlmInference
inference = LlmInference()
app = FastAPI()
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
mannequin = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
Step 4: Put together Endpoint for Interacting with our lessons
Now we’ll replace the api_endpoints.py file by including 3 endpoints. One endpoint might be for easy producing pictures, the second and third will generate each picture and caption however in carious format relying on how tyou need to get the picture.
class ImageRequest(BaseModel):
"""A Pydantic mannequin for picture requests"""
# textual content: str = None
url: str = None
num_sentences: int
steps: int
seed: int
aspect_ratio: str
class ArticleRequest(BaseModel):
"""A Pydantic mannequin for article requests"""
description: str = None
num_sentences: int
steps: int
seed: int
aspect_ratio: str
@app.publish("/generate_image")
async def generate_image(image_request: ImageRequest):
"""
Generates a picture based mostly on the abstract of an article.
Parameters:
----------
image_request : ImageRequest
The request containing the article URL and picture era parameters.
Returns:
-------
FileResponse
The generated picture as a PNG file.
"""
strive:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
summarizer = TextSummarizer(image_request.url, image_request.num_sentences)
abstract = summarizer.summarize()
response = api.generate_image(abstract, image_request.steps, image_request.seed, image_request.aspect_ratio,
False)
if response will not be None:
return FileResponse("picture.png", media_type="picture/png")
else:
increase HTTPException(status_code=500, element="Error producing picture")
besides Exception as e:
increase HTTPException(status_code=500, element=str(e))
@app.publish("/generate_image_caption")
async def generate_image_caption(image_request: ImageRequest):
"""
Generates a picture and its caption based mostly on the abstract of an article.
Parameters:
----------
image_request : ImageRequest
The request containing the article URL and picture era parameters.
Returns:
-------
dict
A dictionary containing the encoded picture and its caption.
"""
strive:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
summarizer = TextSummarizer(image_request.url, image_request.num_sentences)
abstract = summarizer.summarize()
response = api.generate_image(abstract, image_request.steps, image_request.seed, image_request.aspect_ratio,
False)
if response will not be None:
picture = Picture.open("picture.png")
inputs = processor(picture, textual content="a canopy picture of", return_tensors="pt")
out = mannequin.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
with open("picture.png", "rb") as image_file:
encoded_image = base64.b64encode(image_file.learn()).decode('utf-8')
return {"picture": encoded_image, "caption": caption}
else:
increase HTTPException(status_code=500, element="Error producing picture")
besides Exception as e:
increase HTTPException(status_code=500, element=str(e))
@app.publish("/generate_article_and_image_caption")
async def generate_article_and_image_caption(article_request: ArticleRequest):
"""
Generates an article and its picture caption.
Parameters:
----------
article_request : ArticleRequest
The request containing the article description and picture era parameters.
Returns:
-------
dict
A dictionary containing the encoded picture and its caption.
"""
num_sentences=article_request.num_sentences
strive:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
# Generate article with llm
article = inference.generate_article(article_request.description)
# Summarize article
summarizer = TextSummarizer(input_data=article, num_sentences=num_sentences)
abstract = summarizer.summarize()
# Generate picture with Segmind
response = api.generate_image(abstract, article_request.steps, article_request.seed,
article_request.aspect_ratio,
False)
if response will not be None:
picture = Picture.open("picture.png")
inputs = processor(picture, textual content="a canopy picture of", return_tensors="pt")
out = mannequin.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
with open("picture.png", "rb") as image_file:
encoded_image = base64.b64encode(image_file.learn()).decode('utf-8')
return {"picture": encoded_image, "caption": caption}
else:
increase HTTPException(status_code=500, element="Error producing picture")
besides Exception as e:
increase HTTPException(status_code=500, element=str(e))No you can begin the FastAPI server a utilizing this command:
uvicorn api_endpoints:app --host 0.0.0.0 --port 8000you will discover the endpoint right here in your native server:
http://127.0.0.1:8000/docsTo check your code ship this payload in terminal:
{"url": "https://en.wikipedia.org/wiki/History_of_Poland_(1945percentE2percent80percent931989)", "num_sentences": 5, "steps": 4, "seed": 1184522, "aspect_ratio": "1:1"}The endpoint will return a JSON with two fields. One is “picture” and the opposite is “caption”. To comply with finest observe we return the picture encoded as base64. To view the precise picture, it is advisable to convert the base64 regular picture. Copy the picture content material and click on right here. Paste the base64 string there and it’ll present you the generated picture.
That is the generated picture and picture caption for the article on the Historical past of Poland:

Generated caption: “a canopy picture of a person in a army uniform”
Instance 2: Wikipedia Article associated to Nigeria
{"url": "https://en.wikipedia.org/wiki/Nigeria#Well being", "num_sentences": 5, "steps": 4, "seed": 1184522, "aspect_ratio": "1:1"}
caption: “a canopy picture of the republic of nigeria”
Including a UI with Streamlit
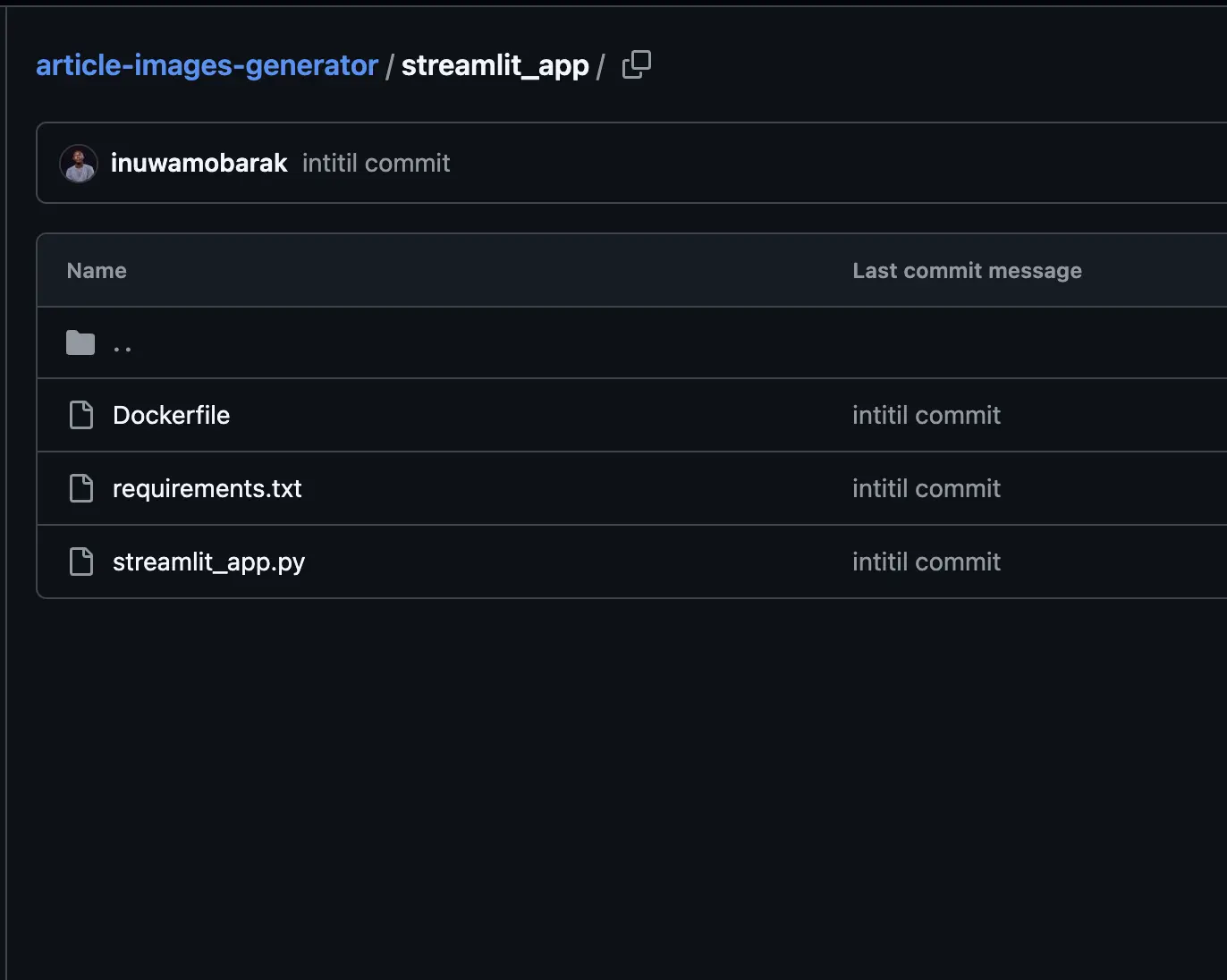
We’ll add a easy UI for our app utilizing Streamlit. Create one other listing referred to as streamlit_app:
Lets create the streamlit_app.py:
import streamlit as st
import requests
from PIL import Picture
from io import BytesIO
import base64
st.title("Article Picture and Caption Generator")
# Enter fields
url = st.text_input("Enter the article URL")
num_sentences = st.number_input("Variety of sentences to summarize to", min_value=1, worth=3)
steps = st.number_input("Steps for picture era", min_value=1, worth=50)
seed = st.number_input("Random seed for era", min_value=0, worth=42)
aspect_ratio = st.selectbox("Choose Facet Ratio", ["16:9", "4:3", "1:1"])
# Button to set off the era
if st.button("Generate Picture and Caption"):
# Present a spinner whereas producing
with st.spinner("Producing..."):
# Ship a POST request to the FastAPI endpoint
response = requests.publish(
"http://fastapi:8000/generate_image_caption", # Use service title outlined in docker-compose
json={
"url": url,
"num_sentences": num_sentences,
"steps": steps,
"seed": seed,
"aspect_ratio": aspect_ratio
}
)
# Verify if the response was profitable
if response.status_code == 200:
# Get the response information
information = response.json()
caption = information["caption"]
image_data = base64.b64decode(information["image"])
# Open the picture from the response information
picture = Picture.open(BytesIO(image_data))
# Show the picture with its caption
st.picture(picture, caption=caption, use_column_width=True)
else:
st.error(f"Error: {response.json()['detail']}")To start out the Streamlit app and see the UI in your browser, run `streamlit run streamlit_app.py`
In the event you see this on terminal then all is effectively:

Output:

You may modify the code and the picture era parameters for automated picture era to get totally different sorts of pictures, and even make the most of fashions from Segmind or the BLIP mannequin for captioning. Be at liberty to implement the part for article era earlier than passing that article for automated picture era. The probabilities are many, so get pleasure from skilling up and constructing AI apps!
Conclusion
By combining conventional NLP with the ability of generative AI, we’ve created a system that simplifies the blog-writing course of. With the assistance of the Segmind API for automated picture era and Salesforce BLIP for captioning, now you can automate the creation of authentic visuals that improve your written content material. This not solely saves time however ensures that your blogs stay visually interesting and informative. The mixing of AI into artistic workflows is a game-changer, making content material creation extra environment friendly and scalable, notably by automated picture era.
Key Takeaways
- AI can generate pictures and captions for blogs, considerably lowering the necessity for guide search by automated picture era.
- Conventional NLP strategies save on computational prices whereas nonetheless producing ‘prompts’ for picture creation.
- The Segmind API permits high-quality, cloud-based picture era, facilitating automated picture era for varied functions.
- AI-driven captions present contextual relevance to generated pictures, enhancing weblog content material high quality.
References and Hyperlinks
Often Requested Questions
A. Conventional NLP summarization extracts or generates summaries utilizing easy rule-based strategies, whereas LLMs use deep studying fashions to supply extra context-aware and fluent summaries. For picture era, conventional NLP suffices.
A. Segmind API permits cloud-based picture era, saving computational sources and eliminating the necessity to arrange or preserve native fashions.
A. BLIP (Bootstrapping Language-Picture Pretraining) is used to generate captions for the photographs produced by the AI. It converts pictures to significant textual content.
A. You may regulate the abstract, ‘immediate’, or picture era parameters (like steps, seed, and side ratio) to fine-tune the outputs.
A. Weblog Creation with AI automates duties like picture era, captioning, and textual content summarization, considerably dashing up and simplifying the content material manufacturing course of.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.
I’m an AI Engineer with a deep ardour for analysis, and fixing advanced issues. I present AI options leveraging Giant Language Fashions (LLMs), GenAI, Transformer Fashions, and Secure Diffusion.