
{kind=link}
Up to now few months, Google has launched its Gemini fashions—massive and mid-sized fashions meant for complicated duties. Gemma is a part of the Gemini AI household, aimed toward making AI growth accessible and secure. This newly launched Gemma, nevertheless, is a light-weight, smaller mannequin aimed toward serving to builders worldwide construct AI responsibly, in compliance with Google’s AI ideas.
This text will discover the Gemma mannequin, coaching processes, and efficiency comparability throughout numerous benchmarks. It additionally features a code demo to implement the Gemma mannequin and different mission concepts that may be applied utilizing this mannequin.
What’s Google’s Gemma?

The Gemma mannequin is a household of light-weight, state-of-the-art open fashions developed by Google DeepMind. These fashions reveal educational strong efficiency when it comes to language understanding, reasoning, and security benchmarks.
The Gemma fashions are available two sizes, with 2 billion and 7 billion parameters, and each present pre-trained and fine-tuned checkpoints. They outperform equally sized open fashions on 11 out of 18 text-based duties and have undergone complete evaluations of security and duty points. The event of the Gemma fashions concerned coaching on as much as 6T tokens of textual content utilizing comparable architectures, knowledge, and coaching.
The Gemma mannequin structure relies on the transformer decoder, with core parameters such because the variety of layers, feedforward hidden dimensions, variety of heads, head dimension, and vocabulary dimension.
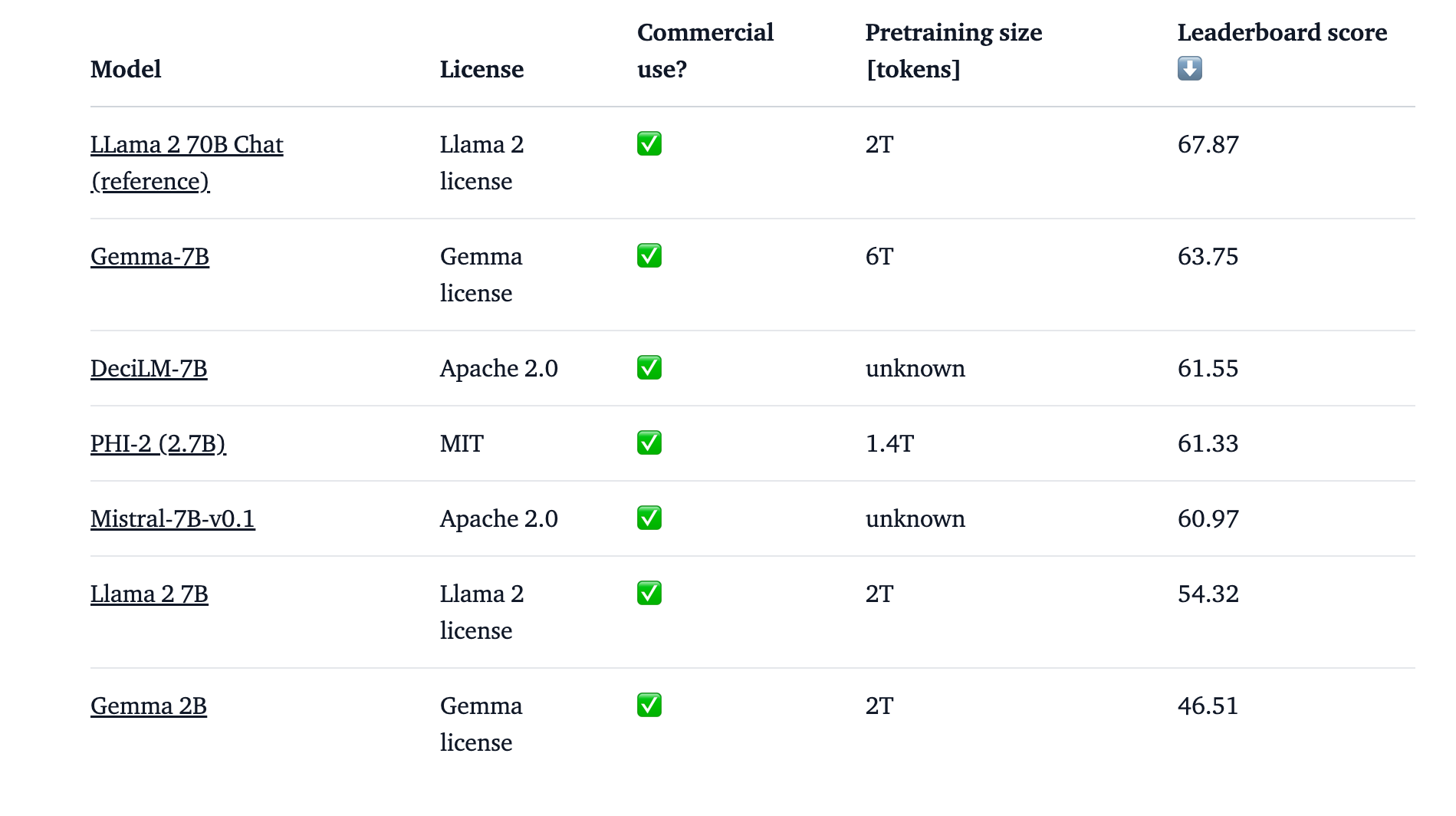
Gemma 7B and Gemma 2B are in contrast with different fashions like PHI-2,together with Mistral 7B. Gemma 2B would not rating as excessive as within the leaderboard compared to different fashions.However Gemma 7B scored good on chief board compared to Mistral and Llama 7B.
How is Gemma Skilled?
Gemma 2B and 7B fashions had been educated on 2T and 60 tokens and knowledge sources like internet docs, code, and arithmetic. Earlier than coaching, rigorously filter and removes undesirable or unsafe content material, together with private and delicate knowledge.
💡
Word: The Gemma mannequin shouldn’t be multimodal. As an alternative, it focuses on textual content solely.
Supervised Fantastic-Tuning (SFT)
- Coaching of the Gemma mannequin is finished with a mixture of actual and made-up conversations (prompts and responses) the place people give directions.
- To select the perfect coaching knowledge, a extra in depth Gemma mannequin checks which responses are higher primarily based on human preferences.
- Coaching knowledge is cleaned by eradicating private data, dangerous content material, and repeated stuff.
- This step helps Gemma perceive directions and reply accordingly.
Reinforcement Studying from Human Suggestions (RLHF)
- Even after coaching with directions, Gemma may make errors.
- Right here, people straight inform Gemma which responses they like, serving to it be taught from their suggestions.
- The mannequin is educated to provide responses with greater rewards, primarily educating it to generate the varieties of responses people preferred extra.
- Baseline fashions examine the high-capacity fashions and guarantee they be taught the proper classes (e.g., tricking the system to get higher scores with out enhancing).
- A capability mannequin as an automated rater is used to compute side-by-side comparisons towards baseline fashions.
Comparability of Gemma with Different Fashions
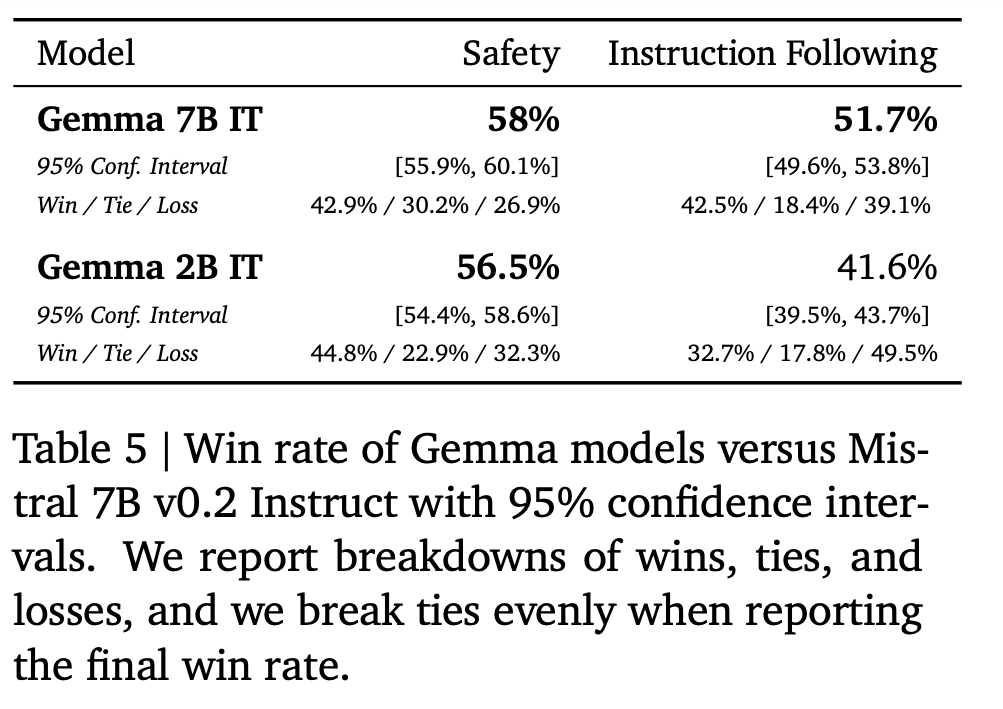
- Check Setup
- Two held-out collections of prompts had been used:
- 1000 prompts: Centered on instruction following in numerous duties.
- 400 prompts: Centered on testing primary security protocols.
- Two held-out collections of prompts had been used:
- Profitable Mannequin
- Instruction Following: Gemma 7B IT emerged victorious with a 51.7% constructive win charge, adopted by Gemma 2B IT (41.6%) after which Mistral v0.2 7B Instruct.
- Security Protocols: Gemma 7B IT once more secured a 58% constructive win charge, intently adopted by Gemma 2B IT (56.5%).
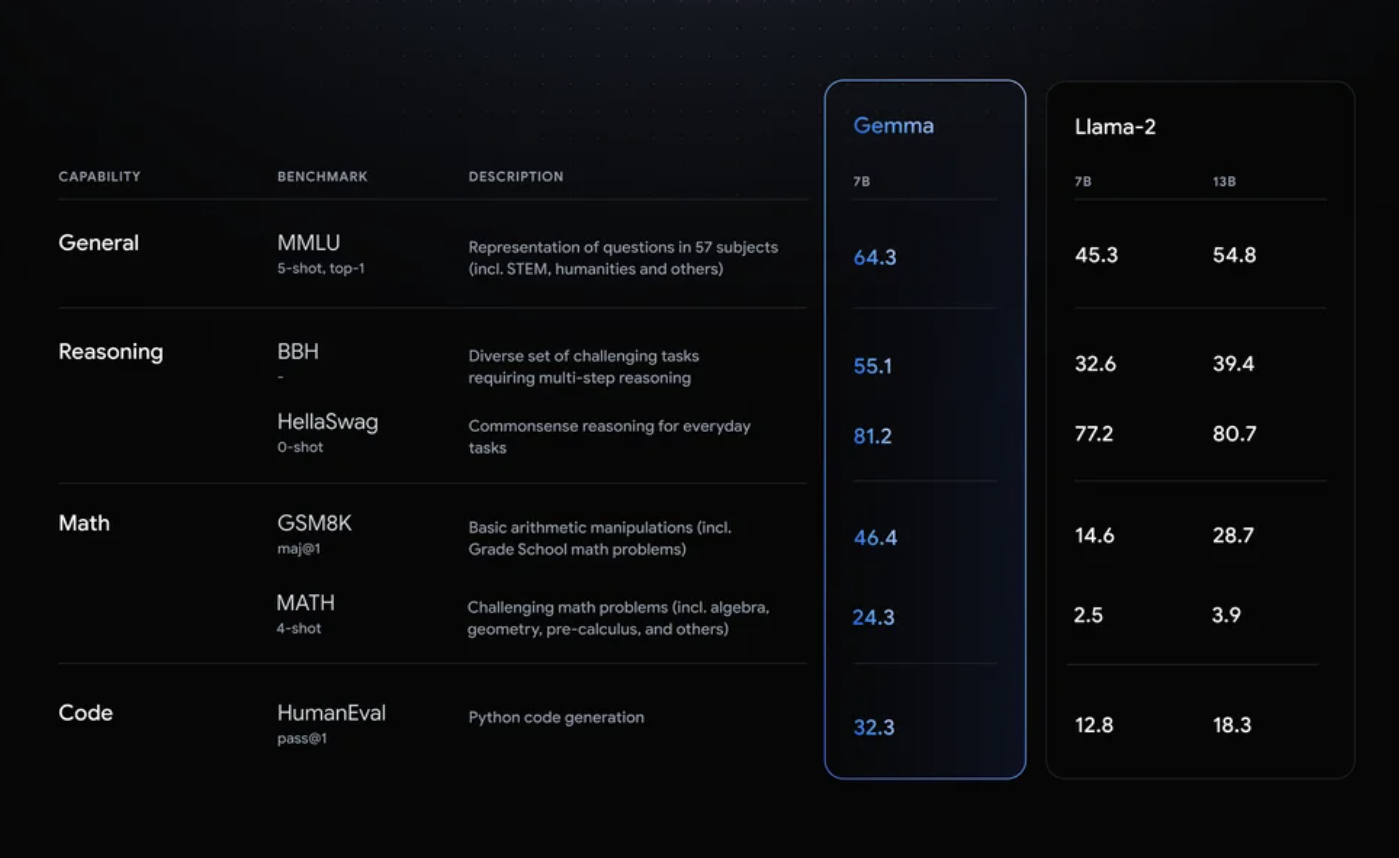
As proven within the above determine, Gemma 7 B is in contrast with LLama -2 7 B and 13 B on numerous benchmarks.
Gemma persistently outperformed Llama 2 in all these domains.
- Reasoning: Gemma scored 55.1 on the BBH benchmark in comparison with Llama 2’s rating of 32.6.
- Arithmetic: Gemma scored 46.4, whereas Llama 2 lagged behind at 14.6.
- Advanced Downside-Fixing: Within the MATH 4-shot benchmark, Gemma scored 24.3, which is considerably greater than Llama 2’s 2.5 rating.
- Python Code Technology: Gemma scored 32.3, outpacing Llama 2’s rating of 12.8.
Comparability with Mistral Mannequin
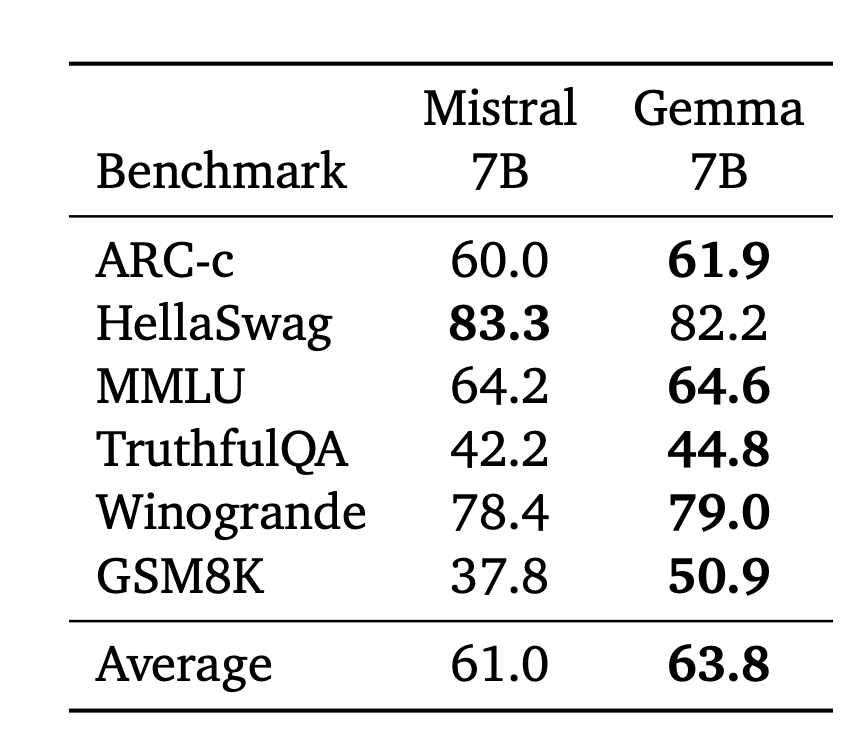
- Gemma 7B outperforms Mistral 7B throughout numerous capabilities, similar to query answering, reasoning, math/science, and coding. So, when it comes to language understanding and technology efficiency, Gemma is healthier than Mistral.
- Throughout completely different benchmarks similar to ARC-c, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K, Gemma fashions present aggressive efficiency in comparison with Mistral.
- On educational benchmarks like RealToxicity, BOLD, CrowS-Pairs, BBQ Ambig, BBQ Disambig, Winogender, TruthfulQA, Winobias, and Toxigen, Gemma fashions exhibit greater scores as in comparison with Mistral.
Demo
First signup on Paperspace. Select the GPU, template and auto-shutdown time and get began.
Putting in the dependencies
!pip set up datasets pandas transformers
!pip set up -U transformers
!pip set up speed up
!pip set up -U sentence-transformers
from datasets import load_dataset
import pandas as pd
from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer, AutoModelForCausalLMFirst, set up all of the dependencies.
Load and put together dataset
dataset = load_dataset("AIatMongoDB/embedded_movies", break up="practice")
dataset = dataset.remove_columns(["plot_embedding"]).to_pandas()
dataset.dropna(subset=["fullplot"], inplace=True)
# Operate to generate response utilizing Gemma mannequin
def generate_response(question):
# Load tokenizer and mannequin
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it", use_auth_token="hf_v")
mannequin = AutoModelForCausalLM.from_pretrained("google/gemma-2b-it", use_auth_token="hf_v")AIatMongoDB/embedded_movies dataset is loaded from the HuggingFace datasets library. This dataset seems to comprise film knowledge, together with plots. Rows with lacking values within the fullplot column are dropped. The use_auth_token parameter is used for authentication with the Hugging Face API, suggesting that the mannequin is hosted in a non-public repository or requires API entry.
To entry the mannequin, additionally, you will want a HuggingFace entry token. You may generate one by going to Settings, then Entry Tokens within the left sidebar, and clicking on the New token button to create a brand new entry token.
Now the entry token is generated, however the place ought to or not it’s pasted? For that, write the next code.
from huggingface_hub import notebook_login
notebook_login()Now, paste the entry token and get entry to the Gemma mannequin.
Put together Enter for the Mannequin and Producing Response
# Put together enter for the mannequin
input_ids = tokenizer(question, return_tensors="pt").input_ids
# Generate a response
response = mannequin.generate(input_ids, max_length=500, max_new_tokens=500, no_repeat_ngram_size=2)
return tokenizer.decode(response[0], skip_special_tokens=True)
# Instance question
question = "What's the finest romantic film to observe and why?"
# Generate response
print(generate_response(question))The question is tokenised and transformed right into a format that the mannequin can perceive (input_ids). The mannequin generates a response primarily based on the enter question. Some parameters are handed, similar to max_length of the output, max_new_tokens to restrict the variety of new tokens generated, and no_repeat_ngram_size to keep away from repeating n-grams within the output.
The generated response is then decoded from its tokenised kind into human-readable textual content and returned.
Do that Task on Paperspace Gradient!!!
We have now applied Gemma 2B, so Gemma 7B can be utilized for higher outcomes for the next mission concepts:
1. Producing personalised information digests for customers primarily based on their pursuits, summarising articles from numerous sources.
2. Growing an interactive device that makes use of Gemma to offer language studying workouts, similar to translations, filling within the blanks, or producing conversational observe eventualities.
3. Making a platform the place customers can co-write tales with Gemma, select plot instructions, or ask Gemma to develop sure story points.
💡
Word: Leverage Paperspace Gradient’s experimentation instruments and deployment choices for attempting out these initiatives.
Closing Ideas
As we stand getting ready to a brand new period in synthetic intelligence, it is clear that fashions like Gemma will play a vital function in shaping the longer term. For builders and researchers wanting to discover the potential of Gemma and harness its energy for his or her initiatives, now could be the time to dive in. With sources like Paperspace GPUs accessible, you could have all the things that you must begin experimenting with Gemma and unlock new prospects in AI growth. So, embark on this thrilling journey with Gemma, and let’s have a look at what unbelievable improvements we are able to deliver to life collectively.