{kind=link}
Introduction
Giant language fashions (LLMs) have dramatically reshaped computational arithmetic. These superior AI methods, designed to course of and mimic human-like textual content, are actually pushing boundaries in mathematical fields. Their capacity to know and manipulate complicated ideas has made them invaluable in analysis and improvement. Amongst these improvements stands Paramanu-Ganita, a creation of Gyan AI Analysis. This mannequin, although solely 208 million parameters robust, outshines lots of its bigger counterparts. It’s particularly constructed to excel in mathematical reasoning, demonstrating that smaller fashions can certainly carry out exceptionally nicely in specialised domains. On this article, we are going to discover the event and capabilities of the Paramanu-Ganita AI mannequin.

The Rise of Smaller Scale Fashions
Whereas large-scale LLMs have spearheaded quite a few AI breakthroughs, they arrive with vital challenges. Their huge measurement calls for in depth computational energy and power, making them costly and fewer accessible. This has prompted a seek for extra viable alternate options.
Smaller, domain-specific fashions like Paramanu-Ganita show advantageous. By specializing in particular areas, corresponding to arithmetic, these fashions obtain larger effectivity and effectiveness. Paramanu-Ganita, for example, requires fewer sources and but operates quicker than bigger fashions. This makes it best for environments with restricted sources. Its specialization in arithmetic permits for refined efficiency, usually surpassing generalist fashions in associated duties.
This shift in direction of smaller, specialised fashions is more likely to affect the longer term path of AI, notably in technical and scientific fields the place depth of data is essential.
Improvement of Paramanu-Ganita
Paramanu-Ganita was developed with a transparent focus: to create a strong, but smaller-scale language mannequin that excels in mathematical reasoning. This method counters the pattern of constructing ever-larger fashions. It as a substitute focuses on optimizing for particular domains to attain excessive efficiency with much less computational demand.
Coaching and Improvement Course of
The coaching of Paramanu-Ganita concerned a curated mathematical corpus, chosen to boost its problem-solving capabilities throughout the mathematical area. It was developed utilizing an Auto-Regressive (AR) decoder and educated from scratch. Impressively, it managed to succeed in its aims with simply 146 hours of coaching on an Nvidia A100 GPU. That is only a fraction of the time bigger fashions require.

Distinctive Options and Technical Specs
Paramanu-Ganita stands out with its 208 million parameters, a considerably smaller quantity in comparison with the billions usually present in giant LLMs. This mannequin helps a big context measurement of 4096, permitting it to deal with complicated mathematical computations successfully. Regardless of its compact measurement, it maintains excessive effectivity and pace, able to working on lower-spec {hardware} with out efficiency loss.
Efficiency Evaluation
Paramanu-Ganita’s design tremendously enhances its capacity to carry out complicated mathematical reasoning. Its success in particular benchmarks like GSM8k highlights its capacity to deal with complicated mathematical issues effectively, setting a brand new commonplace for a way language fashions can contribute to computational arithmetic.
Comparability with Different LLMs like LLaMa, Falcon, and PaLM
Paramanu-Ganita has been immediately in contrast with bigger LLMs corresponding to LLaMa, Falcon, and PaLM. It exhibits superior efficiency, notably in mathematical benchmarks, the place it outperforms these fashions by vital margins. For instance, regardless of its smaller measurement, it outperforms Falcon 7B by 32.6% factors and PaLM 8B by 35.3% factors in mathematical reasoning.
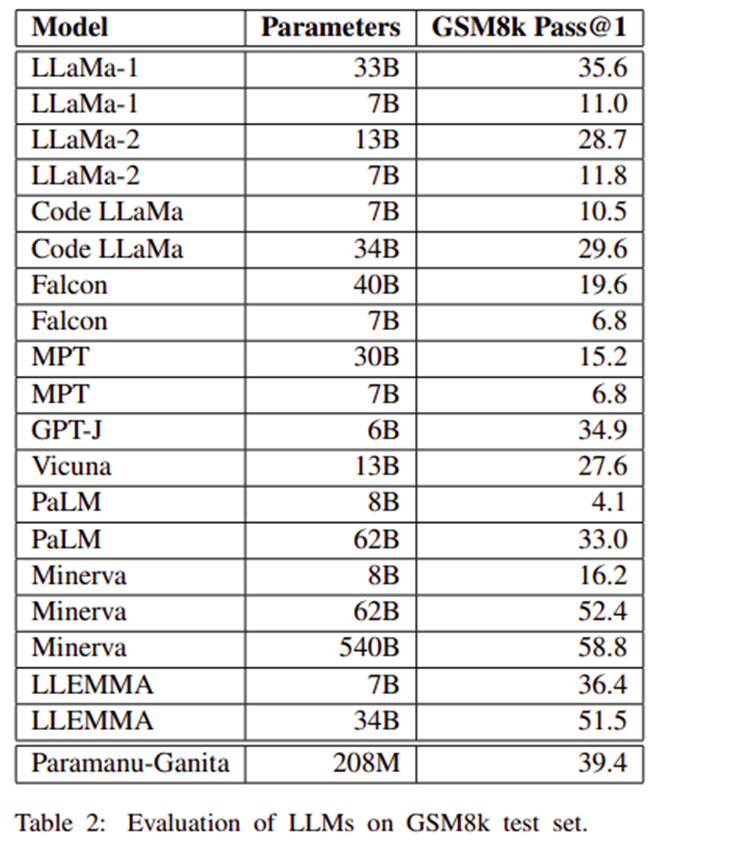
Detailed Efficiency Metrics on GSM8k Benchmarks
On the GSM8k benchmark, which evaluates the mathematical reasoning capabilities of language fashions, Paramanu-Ganita achieved exceptional outcomes. It scored larger than many bigger fashions, demonstrating a Move@1 accuracy that surpasses LLaMa-1 7B and Falcon 7B by over 28% and 32% factors, respectively. This spectacular efficiency underlines its effectivity and specialised functionality in dealing with mathematical duties, confirming the success of its targeted and environment friendly design philosophy.
Implications and Improvements
One of many key improvements of Paramanu-Ganita is its cost-effectiveness. The mannequin requires considerably much less computational energy and coaching time in comparison with bigger fashions, making it extra accessible and simpler to deploy in varied settings. This effectivity doesn’t compromise its efficiency, making it a sensible selection for a lot of organizations.
The traits of Paramanu-Ganita make it well-suited for academic functions, the place it will possibly help in instructing complicated mathematical ideas. In skilled environments, its capabilities may be leveraged for analysis in theoretical arithmetic, engineering, economics, and information science, offering high-level computational assist.
Future Instructions
The event group behind Paramanu-Ganita is actively engaged on an intensive research to coach a number of pre-trained mathematical language fashions from scratch. They purpose to analyze whether or not varied mixtures of sources—corresponding to mathematical books, web-crawled content material, ArXiv math papers, and supply code from related programming languages—improve the reasoning capabilities of those fashions.
Moreover, the group plans to include mathematical question-and-answer pairs from well-liked boards like StackExchange and Reddit into the coaching course of. This effort is designed to evaluate the total potential of those fashions and their capacity to excel on the GSM8K benchmark, a preferred math benchmark.
By exploring these various datasets and mannequin sizes, the group hopes to additional enhance the reasoning capacity of Paramanu-Ganita and doubtlessly surpass the efficiency of state-of-the-art LLMs, regardless of Paramanu-Ganita’s comparatively smaller measurement of 208 million parameters.
Paramanu-Ganita’s success opens the door to broader impacts in AI, notably in how smaller, specialised fashions could possibly be designed for different domains. Its achievements encourage additional exploration into how such fashions may be utilized in computational arithmetic. Ongoing analysis on this area exhibits potential in dealing with algorithmic complexity, optimization issues, and past. Related fashions thus maintain the facility to reshape the panorama of AI-driven analysis and software.
Conclusion
Paramanu-Ganita marks a big step ahead in AI-driven mathematical problem-solving. This mannequin challenges the necessity for bigger language fashions by proving that smaller, domain-specific options may be extremely efficient. With excellent efficiency on benchmarks like GSM8k and a design that emphasizes cost-efficiency and decreased useful resource wants, Paramanu-Ganita exemplifies the potential of specialised fashions to revolutionize technical fields. Because it evolves, it guarantees to broaden the impression of AI, introducing extra accessible and impactful computational instruments throughout varied sectors, and setting new requirements for AI functions in computational arithmetic and past.