
{kind=link}
Google not too long ago launched a brand new mild weight vision-model PaliGemma. This mannequin was launched on the 14 Could 2024 and has multimodal capabilities.
A vision-language mannequin (VLM) is a sophisticated sort of synthetic intelligence that integrates visible and textual knowledge to carry out duties that require understanding and producing each photographs and language. These fashions mix strategies from pc imaginative and prescient and pure language processing, enabling them to research photographs, generate descriptive captions, reply questions on visible content material, and even have interaction in complicated visible reasoning.
VLMs can perceive context, infer relationships, and produce coherent multimodal outputs by leveraging large-scale datasets and complicated neural architectures. This makes them highly effective instruments for functions in fields reminiscent of picture recognition, automated content material creation, and interactive AI programs.
Gemma is a household of light-weight, cutting-edge open fashions developed utilizing the identical analysis and expertise because the Gemini fashions. PaliGemma is a strong open imaginative and prescient language mannequin (VLM) that was not too long ago added to the Gemma household.
What’s PaliGemma?
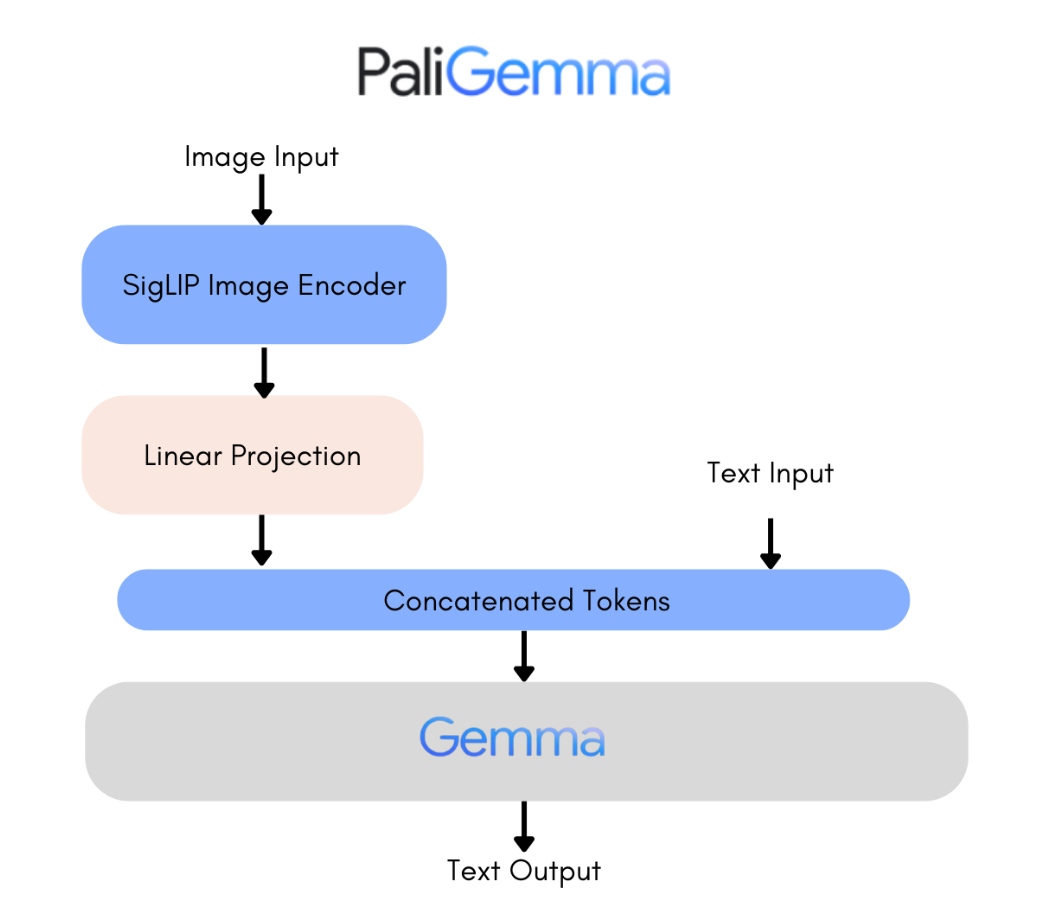
PaliGemma is a strong new open vision-language mannequin impressed by PaLI-3, constructed utilizing the SigLIP imaginative and prescient mannequin and the Gemma language mannequin. It is designed for top-tier efficiency in duties like picture and quick video captioning, visible query answering, textual content recognition in photographs, object detection, and segmentation.
Each the pretrained and fine-tuned checkpoints are open-sourced in varied resolutions, plus task-specific ones for rapid use.
PaliGemma combines SigLIP-So400m because the picture encoder and Gemma-2B because the textual content decoder. SigLIP is a SOTA mannequin able to understanding photographs and textual content, just like CLIP, that includes a collectively skilled picture and textual content encoder. The mixed PaliGemma mannequin, impressed by PaLI-3, is pre-trained on image-text knowledge and may be simply fine-tuned for duties like captioning and referring segmentation. Gemma, a decoder-only mannequin, handles textual content technology. By integrating SigLIP’s picture encoding with Gemma through a linear adapter, PaliGemma turns into a strong vision-language mannequin.
Overview of PaliGemma Mannequin Releases
- Sorts of Fashions:
- PT Checkpoints:
- Pretrained fashions for fine-tuning downstream duties.
- Combine Checkpoints:
- Pretrained fashions fine-tuned on a combination of duties.
- Appropriate for general-purpose inference with free-text prompts.
- Supposed for analysis functions solely.
- FT Checkpoints:
- Fantastic-tuned fashions specialised on completely different tutorial benchmarks.
- Obtainable in varied resolutions.
- Supposed for analysis functions solely.
- PT Checkpoints:
- Mannequin Resolutions:
- Mannequin Precisions:
- Repository Construction:
- Every repository accommodates checkpoints for a given decision and job.
- Three revisions can be found for every precision.
- The primary department accommodates float32 checkpoints.
- bfloat16 and float16 revisions include corresponding precisions.
- Compatibility:
- Separate repositories can be found for fashions appropriate with 🤗 transformers and the unique JAX implementation.
- Reminiscence Issues:
- Excessive-resolution fashions (448×448, 896×896) require considerably extra reminiscence.
- Excessive-resolution fashions are helpful for fine-grained duties like OCR.
- High quality enchancment is marginal for many duties.
- 224×224 variations are appropriate for many functions.
Check out PaliGemma with Paperspace
Deliver this challenge to life
We’ll discover find out how to use 🤗 transformers for PaliGemma inference.
Allow us to first, set up the required libraries with the replace flag to make sure we’re utilizing the most recent variations of 🤗 transformers and different dependencies.
!pip set up -q -U speed up bitsandbytes git+https://github.com/huggingface/transformers.git💡
notebook_login() and enter your entry token by working the cell under.Enter Picture

:strip_icc()/cute-dog-breeds-we-can-t-get-enough-of-4589340-hero-04aba92c6fbb4651b7fa1f54823a1a6d.jpg?ref=blog.paperspace.com){kind=link}
input_text = "what number of canines are there within the picture?"
Subsequent, we’ll import the required libraries and import AutoTokenizer, PaliGemmaForConditionalGeneration, and PaliGemmaProcessor from the transformers library.
As soon as the import is completed we’ll load the pre-trained PaliGemma mannequin and the mannequin is loaded with torch.bfloat16 knowledge sort, which may present a great stability between efficiency and precision on trendy {hardware}.
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
gadget = torch.gadget("cuda" if torch.cuda.is_available() else "cpu")
model_id = "google/paligemma-3b-mix-224"
mannequin = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
processor = PaliGemmaProcessor.from_pretrained(model_id)As soon as the code is executed, the processor will preprocesses each the picture and textual content.
inputs = processor(textual content=input_text, photographs=input_image,
padding="longest", do_convert_rgb=True, return_tensors="pt").to("cuda")
mannequin.to(gadget)
inputs = inputs.to(dtype=mannequin.dtype)
Subsequent, use the mannequin to generate the textual content based mostly on the enter query,
with torch.no_grad():
output = mannequin.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True))Output:-
what number of canines are there within the picture?
1
Load the mannequin in 4-bit
We are able to additionally load mannequin in 4-bit and 8-bit, to scale back the computational and reminiscence assets required for coaching and inference. First, initialize the BitsAndBytesConfig.
from transformers import BitsAndBytesConfig
import torch
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
Subsequent, reload the mannequin and move in above object as quantization_config,
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
gadget="cuda"
model_id = "google/paligemma-3b-mix-224"
mannequin = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16,
quantization_config=nf4_config, device_map={"":0})
processor = PaliGemmaProcessor.from_pretrained(model_id)Generate the output,
with torch.no_grad():
output = mannequin.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True))Output:-
what number of canines are there within the picture?
1
Utilizing PaliGemma for Inference: Key Steps
- Tokenizing the Enter Textual content:
- Textual content is tokenized as regular.
- A
<bos>token is added initially. - A newline token (
n) is appended, which is vital because it was a part of the mannequin’s coaching enter immediate.
- Including Picture Tokens:
- The tokenized textual content is prefixed with a particular variety of
<picture>tokens. - The variety of
<picture>tokens depends upon the enter picture decision and the SigLIP mannequin’s patch dimension. - For PaliGemma fashions:
- 224×224 decision: 256
<picture>tokens (224/14 * 224/14). - 448×448 decision: 1024
<picture>tokens. - 896×896 decision: 4096
<picture>tokens.
- 224×224 decision: 256
- The tokenized textual content is prefixed with a particular variety of
- Reminiscence Issues:
- Bigger photographs end in longer enter sequences, requiring extra reminiscence.
- Bigger photographs can enhance outcomes for duties like OCR, however the high quality acquire is normally small for many duties.
- Check your particular duties earlier than choosing increased resolutions.
- Producing Token Embeddings:
- The entire enter immediate goes by the language mannequin’s textual content embeddings layer, producing 2048-dimensional token embeddings.
- Processing the Picture:
- The enter picture is resized to the required dimension (e.g., 224×224 for the smallest decision fashions) utilizing bicubic resampling.
- It’s then handed by the SigLIP Picture Encoder to create 1152-dimensional picture embeddings per patch.
- These picture embeddings are projected to 2048 dimensions to match the textual content token embeddings.
- Combining Picture and Textual content Embeddings:
- The ultimate picture embeddings are merged with the
<picture>textual content embeddings. - This mixed enter is used for autoregressive textual content technology.
- The ultimate picture embeddings are merged with the
- Autoregressive Textual content Technology:
- Makes use of full block consideration for the whole enter (picture +
<bos>+ immediate +n). - Employs a causal consideration masks for the generated textual content.
- Makes use of full block consideration for the whole enter (picture +
- Simplified Inference:
- The processor and mannequin lessons deal with all these particulars mechanically.
- Inference may be carried out utilizing the high-level transformers API, as demonstrated in earlier examples.
Purposes
Imaginative and prescient-language fashions like PaliGemma have a variety of functions throughout varied industries. Few examples are listed under:
- Picture Captioning: Routinely producing descriptive captions for photographs, which may improve accessibility for visually impaired people and enhance the person expertise.
- Visible Query Answering (VQA): Answering questions on photographs, which may enable extra interactive serps, digital assistants, and academic instruments.
- Picture-Textual content Retrieval: Retrieving related photographs based mostly on textual queries and vice versa, facilitating content material discovery and search in multimedia databases.
- Interactive Chatbots: Participating in conversations with customers by understanding each textual inputs and visible context, resulting in extra customized and contextually related responses.
- Content material Creation: Routinely producing textual descriptions, summaries, or tales based mostly on visible inputs, aiding in automated content material creation for advertising and marketing, storytelling, and inventive industries.
- Synthetic Brokers: Using these expertise to energy robots or digital brokers with the flexibility to understand and perceive the encompassing setting, enabling functions in robotics, autonomous automobiles, and sensible residence programs.
- Medical Imaging: Analyzing medical photographs (e.g., X-rays, MRIs) together with scientific notes or studies, helping radiologists in prognosis and remedy planning.
- Style and Retail: Offering customized product suggestions based mostly on visible preferences and textual descriptions, enhancing the purchasing expertise and rising gross sales conversion charges.
- Optical character recognition: Optical character recognition (OCR) includes extracting seen textual content from a picture and changing it into machine-readable textual content format. Though it sounds easy, implementing OCR in manufacturing functions can pose vital challenges.
- Academic Instruments: Creating interactive studying supplies that mix visible content material with textual explanations, quizzes, and workout routines to reinforce comprehension and retention.
These are just some examples, and the potential functions of vision-language fashions proceed to broaden as researchers and builders discover new use instances and combine these applied sciences into varied domains.
Conclusion
In conclusion, we will say that PaliGemma represents a major development within the discipline of vision-language fashions, providing a strong device for understanding and producing content material based mostly on photographs. With its potential to seamlessly combine visible and textual data, PaliGemma opens up new path for analysis and software throughout a variety of industries. From picture captioning to optical character recognition and past, PaliGemma’s capabilities maintain promise for driving innovation and addressing complicated issues within the digital age.
We hope you loved studying the article!