{kind=link}
Think about making a pc to see and perceive the world, very similar to how we people acknowledge faces or spot objects. This duties appears to be simple for human mind however for a pc not a lot!
On this article we are going to break down the Convolutional Neural Networks in less complicated phrases.
Convolutional Neural Networks (CNNs) are just like the digital eyes and brains that permit machines to make sense of pictures. The way in which laptop seems at pictures is as a grid of numbers, these numbers are normally RGB numbers from 0 to 255.
On the planet of Convolutional Neural Networks, we’ll perceive how computer systems take a look at photos and work out what’s in them. From understanding the fundamentals of how they “see” to the cool issues they’ll do, prepare for a enjoyable trip into the center of this expertise that is altering the way in which computer systems perceive the visible wonders round us!
CNNs are primarily used to extract options from an enter picture by making use of sure filters.
Why CNNs?
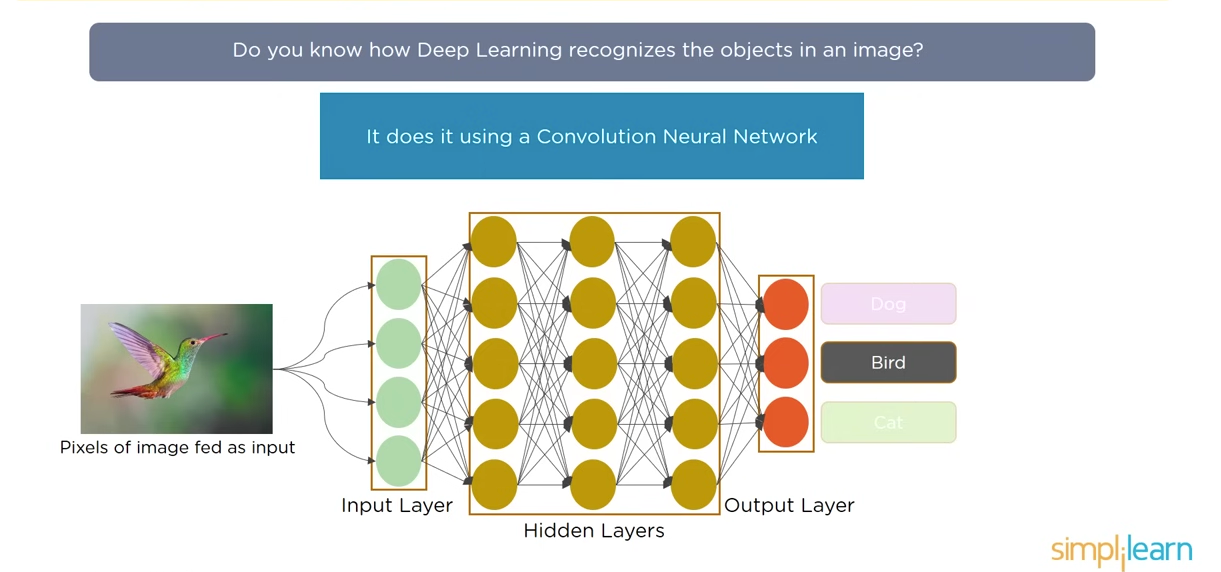
A CNN is a particular kind of ANN that gained its recognition for analyzing picture and different classification drawback as effectively. CNNs are nice to detect sample from a picture and therefore making it helpful for picture evaluation. A CNN consists of enter layer, hidden layer and the output layer. The hidden layer contains of convolutional layer, pooling layer, and totally linked dense layers.
Now, the query would possibly come up can we use ANN for picture recognition?
Allow us to perceive with an instance!

On this case suppose we now have a chook, the picture is a colored pic therefore may have three RGB channel.
- The picture dimension is 3082 × 2031, therefore the primary layer neurons will probably be 3082 x 2031 x 3 ~ 18 million
- Hidden layer neurons will virtually be equal to 10 million
- Weights between first layer and hidden layer will come upto 19 mil x 10 mil ~ 190 million
Utilizing a densely linked neural community for picture classification brings a few important computational burden, doubtlessly this quantity may attain upto billions. This quantity of computation will not be solely extreme but additionally pointless. Moreover, synthetic neural networks (ANNs) are likely to deal with all pixels uniformly, no matter their spatial proximity. Provided that picture recognition predominantly depends on native options, this method turns into a disadvantage. The problem lies within the community’s wrestle to detect objects in a picture when pixel preparations are modified, this can be a potential limitation encountered with ANN.
Convolution Operation and Stride Leap
Within the human mind, the method of picture recognition includes the examination of particular person options by particular units of neurons. These neurons are subsequently linked to a different set that identifies distinct options, and this set, in flip, connects to a different group chargeable for aggregating the outcomes to find out whether or not the picture depicts a cat, canine, or chook.
Much like this idea is utilized in CNN, the place options are detected utilizing filters or kernels. This filter is utilized to the enter information or picture by sliding it over the whole enter. At every cell component sensible multiplication is carried out, and outcomes are summed as much as produce a single worth for that particular cell. Moreover, the filter takes a stride bounce and the identical operation is repeated till the whole picture is captured. The output of this operation is called a characteristic map.
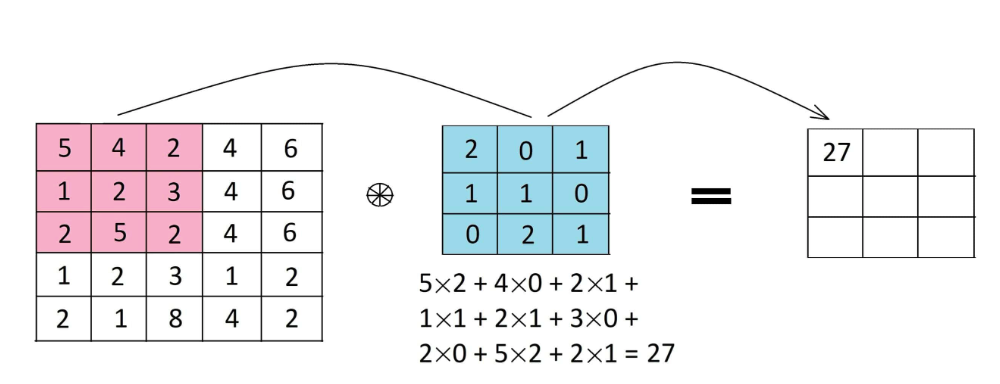
Characteristic maps are chargeable for capturing particular patterns relying on the filter used. Because the filter takes the stride bounce throughout the enter, it detects totally different native patterns, capturing spatial info.
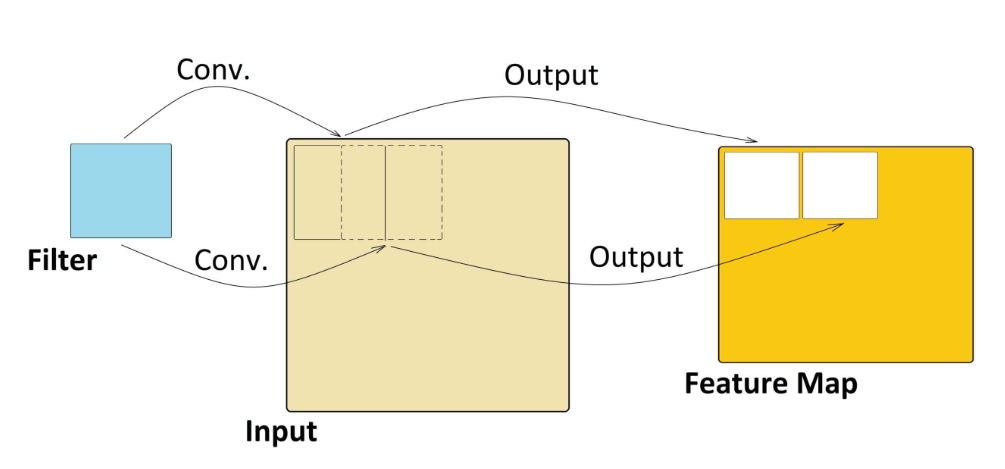
In easy phrases, once we use a filter or carry out a convolution operation, we’re making a characteristic map that highlights a particular attribute. Consider these filters as particular instruments that may detect specific options, like an “eye detector” for a chook. After we apply this detector to a picture, it scans by, and if it finds eyes, it marks their location on the characteristic map. Importantly, these filters do not care the place the eyes are within the picture; they will discover them whatever the location as a result of the filter slides throughout the whole picture. Every filter is sort of a specialised characteristic detective, serving to us establish totally different facets of the picture.

These filters might be 2D in addition to 3D filter. For instance a head filter will probably be a aggregated filter of eyes, tail, beak, and so forth., and this filter turns into a head detector. In an identical means there might be physique detector. A fancy characteristic would be capable of find a a lot intricate element in a picture. These options filters generates the characteristic maps.
Characteristic Maps
Characteristic map or activation map, are flattened array of numbers that seize particular patterns or options in a picture. In laptop imaginative and prescient, notably in Convolutional Neural Networks (CNNs), characteristic maps are created by making use of filters or kernels to enter pictures. Every quantity within the characteristic map represents the extent of activation of the corresponding characteristic within the enter information. These options map are flattened to get a 1d array and is additional linked to a dense totally linked neural community for classification process.
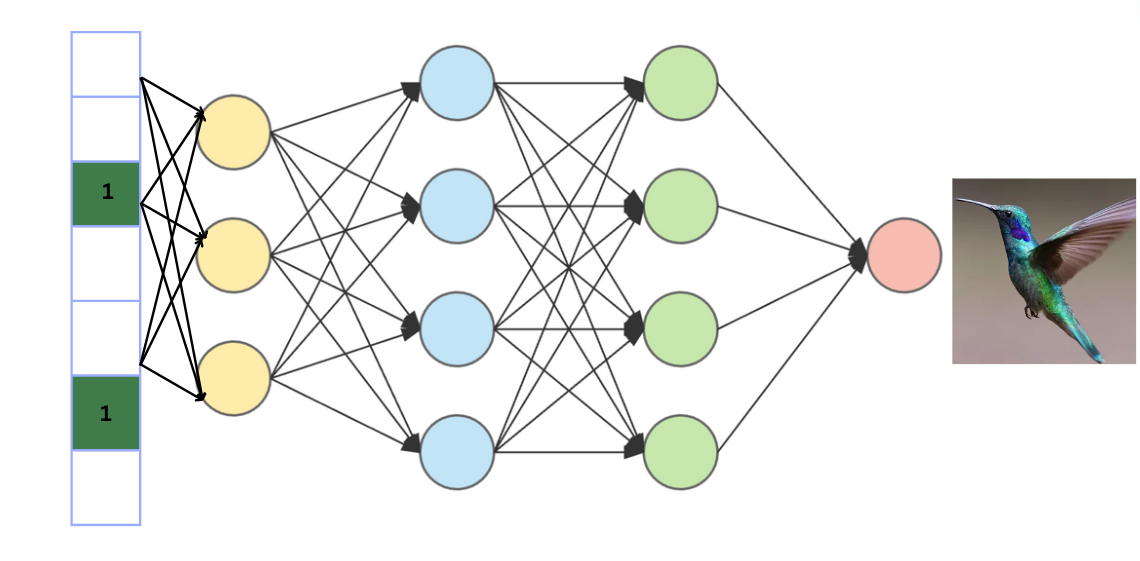
Why do we want a dense neural community?
The neural community offers with the truth that objects in photos might be in other places and there may be many objects in a single image. Therefore, first we use convolutional neural operation, that appears for various options within the picture. This helps it acknowledge varied patterns within the image. Then, a dense neural community is used to determine what’s within the image based mostly on these options. So, the primary half finds totally different particulars, and the second half decides what these particulars imply by way of classification.
This isn’t all we additionally add an activation perform usually after convolutional layer and totally linked deep neural layers. A quite common activation features is ReLu.
ReLu
ReLU activation is used to introduce non-linearity to our mannequin. Primarily, it takes the characteristic map and replaces any unfavourable values with zero, whereas leaving constructive values unchanged. This straightforward mechanism of setting unfavourable values to zero and retaining constructive ones aids in making the mannequin non-linear. This activation perform additionally aids in eliminating vanishing gradient drawback.
f(x) = max(0, x)
Coping with heavy computation
By all of those calculations we nonetheless haven’t talked in regards to the subject of heavy computation. To beat this subject we use Pooling.
Pooling in less complicated phrases might be understood as summarizing info. For instance to summarize a giant image, to grasp what’s in it however do not want each single element. Pooling helps by decreasing the scale of the image whereas preserving the necessary components. It does this by small chunks of the picture at a time and choosing a very powerful info from every chunk. For instance, if it is a bunch of 4 pixels, it would solely maintain the brightest one. This manner, it shrinks the picture whereas nonetheless capturing the primary options, making it simpler and sooner for the pc to work with.
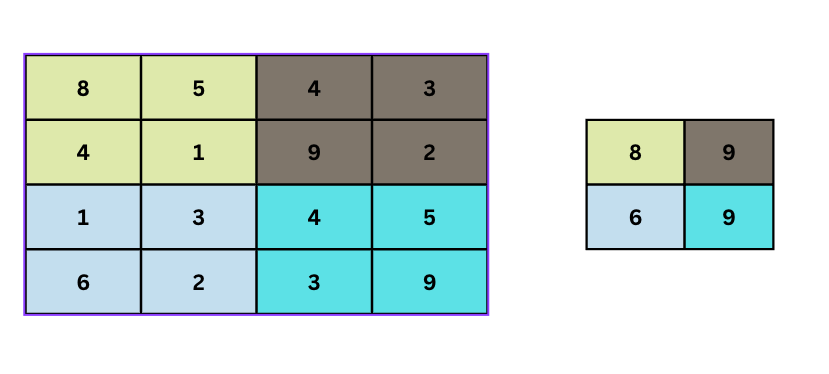
From the above illustration, an empty (2, 2) filter is slid over a (4, 4) picture with a stride of two. The utmost pixel worth is extracted every time to type a brand new picture. The ensuing picture is a resultant max pooled illustration of the unique picture The ensuing picture is half the scale of the unique picture. This helps is decreasing the dimension and likewise the computation energy. Pooling additionally reduces overfitting.
A typical CNN may have:-
- A convolution layer
- ReLu activation perform layer
- Pooling
- Lastly, on the finish a completely linked dense neural community
Conclusion
To summarize, the primary objective of a convolutional neural community is to extract options, and the subsequent half features are like a synthetic neural community. Convolution not solely detects options but additionally reduces dimensionality. The three predominant benefits to this operation are first connection sparsity decreasing overfitting, implying not each node is linked to each different node, as seen in dense networks. Second, convolution focuses on native areas of the picture at a time, avoiding impression on the whole picture. Third, combining convolution and pooling gives location-invariant characteristic detection. In less complicated phrases, convolutional neural networks excel at discovering options in pictures, serving to to stop overfitting, and making certain flexibility in recognizing options throughout totally different areas.
ReLu activtion introduces non-linearity and additional reduces overfitting. Additionally information augmentation is used to generate variation in samples.