{kind=link}
Introduction
Whereas working with Pandas in Python, you might usually discover that your code is gradual, it makes use of an excessive amount of reminiscence, or it will get troublesome to deal with as your information grows bigger. Any of those points can result in errors, lengthy wait instances for evaluation, and limitations in processing larger datasets. On this article, we are going to discover alternative ways to make computation occur sooner for the code you’ve gotten written in Pandas.
The methods talked about on this information will mature your mission code and prevent loads of time. The computational time you save will replicate or translate into value financial savings, higher consumer expertise, and higher operational expertise. That is useful when deploying your ML or Python code right into a cloud atmosphere akin to Amazon net companies (AWS), Google Cloud Platform (GCP), or Microsoft Azure.

Making Pandas Quicker Utilizing Numba
This primary methodology is Numba which accelerates your code that makes use of Numpy beneath. It’s an open-source JIT(Simply in Time) compiler. You need to use Numba for mathematical operations, NumPy codes, and a number of loops. We’re specifying Numpy codes as a result of Pandas are constructed on prime of NumPy. Let’s see methods to use Numba:
1. Set up Numba
!pip set up numba ==0.53.12. Import Libraries
import numba
from numba import jit
print(numba.model)3. Outline Process
Get the checklist of prime numbers from 0 to 100
Let’s code with out utilizing Numba
# Outline operate to extract prime numbers from a given checklist utilizing easy Python
def check_prime(y):
prime_numbers = []
for num in y:
flag = False
if num > 1:
# verify for components
for i in vary(2, num):
if (num % i) == 0:
# if issue is discovered, set flag to True
flag = True
# get away of loop
break
if flag == False:
prime_numbers.append(num)
return prime_numbers4. Calculate Time
Let’s calculate the time taken to carry out the duty
# Checklist of 0 to 100
x = np.arange(100)
x
# DO NOT REPORT THIS... COMPILATION TIME IS INCLUDED IN THE EXECUTION TIME!
begin = time.time()
check_prime(x)
finish = time.time()
print("Elapsed (with compilation) = %s" % (finish - begin))
# NOW THE FUNCTION IS COMPILED, RE-TIME IT EXECUTING FROM CACHE
begin = time.time()
check_prime(x)
finish = time.time()
print("Elapsed (after compilation) = %s" % (finish - begin))Output

In a pocket book, the %timeit magic operate is one of the best to make use of as a result of it runs the operate many instances in a loop to get a extra correct estimate of the execution time of brief features.
%timeit check_prime(x)Now, let’s code utilizing Numba’s JIT decorator
# Outline operate to extract prime numbers from a given checklist utilizing jit decorator and nopython = True mode
@jit(nopython=True)
def check_prime(y):
prime_numbers = []
for num in y:
flag = False
if num > 1:
# verify for components
for i in vary(2, num):
if (num % i) == 0:
# if issue is discovered, set flag to True
flag = True
# get away of loop
break
if flag == False:
prime_numbers.append(num)
return np.array(prime_numbers)Let’s calculate the time taken to carry out the duty
# DO NOT REPORT THIS... COMPILATION TIME IS INCLUDED IN THE EXECUTION TIME!
begin = time.time()
check_prime(x)
finish = time.time()
print("Elapsed (with compilation) = %s" % (finish - begin))
# NOW THE FUNCTION IS COMPILED, RE-TIME IT EXECUTING FROM CACHE
begin = time.time()
check_prime(x)
finish = time.time()
print("Elapsed (after compilation) = %s" % (finish - begin))
In a pocket book, the %timeit magic operate is one of the best to make use of as a result of it runs the operate many instances in a loop to get a extra correct estimate of the execution time of brief features.
%timeit check_prime(x)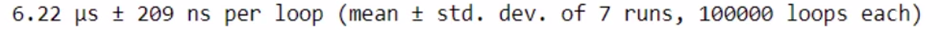
You possibly can see that computation could be very excessive utilizing Numba.
Utilizing Dask for Making Pandas Computation Quicker
Dask supplies environment friendly parallelization for information analytics in Python. Dask Dataframes permits you to work with massive datasets for each information manipulation and constructing ML fashions with solely minimal code modifications. It’s open supply and works nicely with Python libraries like NumPy, sci-kit-learn, and many others.
Why Dask?
Pandas isn’t enough when the info will get larger, larger than what you may match within the RAM. You could use Spark or Hadoop to resolve this. However, these should not Python environments. This stops you from utilizing NumPy, sklearn, Pandas, TensorFlow, and all of the generally used Python libraries for ML. It scales as much as clusters. That is the place Dask involves the rescue.
!pip set up dask==2021.05.0
!pip set up graphviz==0.16
!pip set up python-graphviz
# Import dask
import dask
print(dask.__version__)Parallel Processing with Dask
Process
– Apply a reduction of 20% to 2 merchandise value 100 and 200 respectively and generate a complete invoice
Operate with out Dask
Let’s outline the features. Because the job could be very small, I’m including up sleep time of 1 second in each operate.
from time import sleep
# Outline features to use low cost, get the overall of two merchandise, get the ultimate value of two merchandise
def apply_discount(x):
sleep(1)
x = x - 0.2 * x
return x
def get_total_price(a, b):
sleep(1)
return a + bLet’s calculate the overall invoice and be aware down the time taken for the duty. I’m utilizing %%time operate to notice the time
%%time
product1 = apply_discount(100)
product2 = apply_discount(200)
total_bill = get_total_price(product1, product2)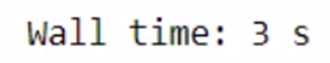
The overall time taken for the above job is 4.01s. Let’s use Dask and verify the time taken
Operate with Dask
Use the delayed operate from Dask to scale back the time
# Import dask.delayed
from dask import delayed
%%time
# Wrapping the operate calls utilizing dask.delayed
product1 = delayed(apply_discount)(100) # no work has occurred but
product2 = delayed(apply_discount)(200) # no work has occurred but
total_bill = delayed(get_total_price)(product1, product2) # no work has occurred but
total_bill
Delayed('get_total_price-d7ade4e9-d9ba-4a9f-886a-ec66b20c6d66')As you may see the overall time taken with a delayed wrapper is just 374 µs. However the work hasn’t occurred but. A delayed wrapper creates a delayed object, that retains monitor of all of the features to name and the arguments to cross to it. Mainly, it has constructed a job graph that explains the whole computation. You don’t have the output but.
Most Dask workloads are lazy, that’s, they don’t begin any work till you explicitly set off them with a name to compute().
So let’s use compute() to get the output
total_bill.compute()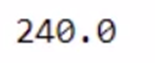
Now you’ve gotten the output. This operation additionally took a while. Let’s compute the overall time taken.
%%time
# Wrapping the operate calls utilizing dask.delayed
product1 = delayed(apply_discount)(100)
product2 = delayed(apply_discount)(200)
total_bill = delayed(get_total_price)(product1, product2)
total_bill.compute()
The overall time taken is 2.01 seconds. It’s 1 second lower than the unique features. Any concept how dask.delayed did this?
You possibly can see the optimum job graph created by Dask by calling the visualize() operate. Let’s see.
# Visualize the total_bill object
total_bill.visualize()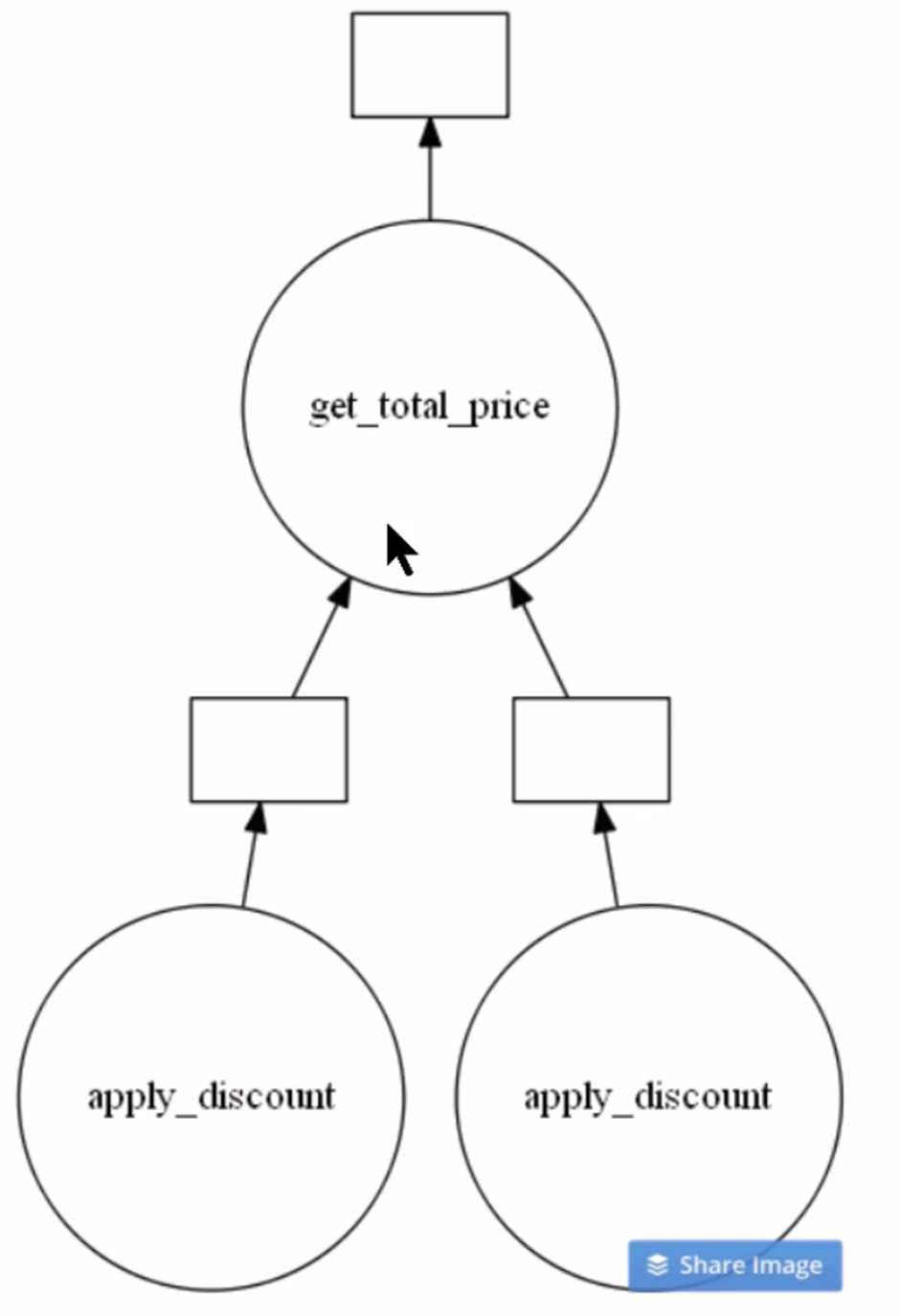
Clearly from the above picture, you may see there are two cases of apply_discount() operate known as in parallel. This is a chance to save lots of time and processing energy by executing them concurrently.
This was probably the most primary use circumstances of Dask.
Making Pandas Quicker Utilizing Modin
Modin is a Python library that can be utilized to deal with massive datasets utilizing parallelization. It makes use of Ray or Dask to offer a simple strategy to velocity up operations.
The syntax is just like Pandas and its astounding efficiency has made it a promising answer. All it’s important to do is change only one line of code.
# Set up Modin dependencies and Dask to run on Dask
!pip set up -U pandas
!pip set up modin[dask]
!pip set up "dask[distributed]"Modin additionally permits you to select which engine you want to use for computation. The atmosphere variable MODIN_ENGINE is used for this. The under code reveals methods to specify the computation engine:
import os
os.environ["MODIN_ENGINE"] = "ray" # Modin will use Ray
os.environ["MODIN_ENGINE"] = "dask" # Modin will use DaskBy default, Modin will use the entire cores obtainable in your system.
However if you happen to want to restrict the cores as you want to do another job, you may restrict the variety of CPUs Modin makes use of with the under command:
import os
os.environ["MODIN_CPUS"] = "4"
import modin.pandas as pdProcess
- Load the dataset utilizing Pandas and Modin and evaluate the overall time taken.
I’m going to make use of pandas_pd for pandas and modin_pd for modin. First, let’s load the info utilizing Pandas.
# Load Pandas and time
import pandas as pandas_pd
import time
# Load csv file utilizing pandas
%time pandas_df = pandas_pd.read_csv("your_dataset.csv")
Initialize Dask consumer
# For Dask backend
from dask.distributed import Consumer
consumer = Consumer()
# Load csv file utilizing modin pd
%time modin_df = pd.read_csv("Datasets/large_dataset.csv")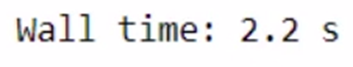
The overall time taken is 1 min 10 seconds. The time taken would possibly fluctuate as per the specification of your system. We have been capable of save a couple of seconds just for such a small job. Think about how a lot time we will save whereas engaged on a much bigger dataset and loads of computations!
Let’s carry out a couple of duties utilizing Modin.
Process
- Print the pinnacle of each dataframes and evaluate the time
# pandas df fillna
%time pandas_df.fillna(0)
# modin df fillna
%time modin_df.fillna(0)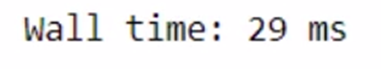
Modin is taking lesser time.
Conclusion
On this article, we have now seen how totally different Python features are used to hurry up the computation velocity of Pandas code. We realized how Numba is used for optimized numerical computations, whereas Dask is utilized in parallel processing on large datasets. We additionally noticed how Modin’s acquainted Pandas-like interface accelerates by Ray or Dask. Selecting one of the best strategy amongst these is dependent upon your information measurement, computation sort, and desired stage of ease-use.
Keep tuned for an additional article the place we share extra suggestions and methods to make your Python Pandas code sooner and extra environment friendly!