
{kind=link}
Usually, the usage of giant language fashions (LLMs) within the enterprise falls into two broad classes. The primary one is the place the LLM automates a language-related process resembling writing a weblog submit, drafting an electronic mail, or bettering the grammar or tone of an electronic mail you’ve gotten already drafted. More often than not these kinds of duties don’t contain confidential firm data.
The second class includes processing inside firm data, resembling a group of paperwork (PDFs, spreadsheets, shows, and many others.) that should be analyzed, summarized, queried, or in any other case utilized in a language-driven process. Such duties embrace asking detailed questions concerning the implications of a clause in a contract, for instance, or making a visualization of gross sales projections for an upcoming challenge launch.
There are two explanation why utilizing a publicly out there LLM resembling ChatGPT won’t be acceptable for processing inside paperwork. Confidentiality is the primary and apparent one. However the second cause, additionally essential, is that the coaching information of a public LLM didn’t embrace your inside firm data. Therefore that LLM is unlikely to offer helpful solutions when requested about that data.
Enter retrieval-augmented era, or RAG. RAG is a method used to enhance an LLM with exterior information, resembling your organization paperwork, that present the mannequin with the information and context it wants to supply correct and helpful output to your particular use case. RAG is a practical and efficient method to utilizing LLMs within the enterprise.
On this article, I’ll briefly clarify how RAG works, checklist some examples of how RAG is getting used, and supply a code instance for organising a easy RAG framework.
How retrieval-augmented era works
Because the identify suggests, RAG consists of two components—one retrieval, the opposite era. However that doesn’t make clear a lot. It’s extra helpful to think about RAG as a four-step course of. Step one is finished as soon as, and the opposite three steps are executed as many instances as wanted.
The 4 steps of retrieval-augmented era:
- Ingestion of the interior paperwork right into a vector database. This step might require lots of information cleansing, formatting, and chunking, however it is a one-time, up-front value. (For a fast primer on vector databases see this text.)
- A question in pure language, i.e., the query a human desires to ask the LLM.
- Augmentation of the question with information retrieved utilizing similarity search of the vector database. This step is the place context from the doc retailer is added to the question earlier than the question is submitted to the LLM. The immediate instructs the LLM to reply within the context of the extra content material. The RAG framework does this work behind the scenes by way of a part referred to as a retriever, which executes the search and appends the related context.
- Technology of the response to the augmented question by the LLM.
By focusing the LLM on the doc corpus, RAG helps to make sure that the mannequin produces related and correct solutions. On the similar time, RAG helps to forestall arbitrary or nonsensical solutions, that are generally referred to within the literature as “hallucinations.”
From the person perspective, retrieval-augmented era will appear no totally different than asking a query to any LLM with a chat interface—besides that the system will know way more concerning the content material in query and can give higher solutions.
The RAG course of from the perspective of the person:
- A human asks a query of the LLM.
- The RAG system seems up the doc retailer (vector database) and extracts content material which may be related.
- The RAG system passes the person’s query, plus the extra content material retrieved from the doc retailer, to the LLM.
- Now the LLM “is aware of” to supply a solution that is smart within the context of the content material retrieved from the doc retailer (vector database).
- The RAG system returns the response from the LLM. The RAG system can even present hyperlinks to the paperwork used to reply the question.
Use circumstances for retrieval-augmented era
The use circumstances for RAG are various and rising quickly. These are just some examples of how and the place RAG is getting used.
Serps
Serps have applied RAG to supply extra correct and up-to-date featured snippets of their search outcomes. Any utility of LLMs that should sustain with continually up to date data is an efficient candidate for RAG.
Query-answering techniques
RAG has been used to enhance the standard of responses in question-answering techniques. The retrieval-based mannequin finds related passages or paperwork containing the reply (utilizing similarity search), then generates a concise and related response primarily based on that data.
E-commerce
RAG can be utilized to boost the person expertise in e-commerce by offering extra related and personalised product suggestions. By retrieving and incorporating details about person preferences and product particulars, RAG can generate extra correct and useful suggestions for purchasers.
Healthcare
RAG has nice potential within the healthcare trade, the place entry to correct and well timed data is essential. By retrieving and incorporating related medical information from exterior sources, RAG can help in offering extra correct and context-aware responses in healthcare purposes. Such purposes increase the data accessible by a human clinician, who finally makes the decision and never the mannequin.
Authorized
RAG will be utilized powerfully in authorized situations, resembling M&A, the place complicated authorized paperwork present context for queries, permitting speedy navigation by means of a maze of regulatory points.
Introducing tokens and embeddings
Earlier than we dive into our code instance, we have to take a more in-depth take a look at the doc ingestion course of. To have the ability to ingest docs right into a vector database to be used in RAG, we have to pre-process them as follows:
- Extract the textual content.
- Tokenize the textual content.
- Create vectors from the tokens.
- Save the vectors in a database.
What does this imply?
A doc could also be PDF or HTML or another format, and we don’t care concerning the markup or the format. All we wish is the content material—the uncooked textual content.
After extracting the textual content, we have to divide it into chunks, referred to as tokens, then map these tokens to high-dimensional vectors of floating level numbers, sometimes 768 or 1024 in measurement and even bigger. These vectors are referred to as embeddings, ostensibly as a result of we’re embedding a numerical illustration of a bit of textual content right into a vector house.
There are numerous methods to transform textual content into vector embeddings. Often that is executed utilizing a instrument referred to as an embedding mannequin, which will be an LLM or a standalone encoder mannequin. In our RAG instance beneath, we’ll use OpenAI’s embedding mannequin.
A word about LangChain
LangChain is a framework for Python and TypeScript/JavaScript that makes it simpler to construct purposes which are powered by language fashions. Primarily, LangChain permits you to chain collectively brokers or duties to work together with fashions, join with information sources (together with vector information shops), and work along with your information and mannequin responses.
LangChain may be very helpful for leaping into LLM exploration, however it’s altering quickly. Because of this, it takes some effort to maintain all of the libraries in sync, particularly in case your utility has lots of shifting components with totally different Python libraries in several phases of evolution. A more moderen framework, LlamaIndex, additionally has emerged. LlamaIndex was designed particularly for LLM information purposes, so has extra of an enterprise bent.
Each LangChain and LlamaIndex have in depth libraries for ingesting, parsing, and extracting information from an enormous array of information sources, from textual content, PDFs, and electronic mail to messaging techniques and databases. Utilizing these libraries takes the ache out of parsing every totally different information sort and extracting the content material from the formatting. That itself is well worth the value of entry.
A easy RAG instance
We’ll construct a easy “Howdy World” RAG utility utilizing Python, LangChain, and an OpenAI chat mannequin. Combining the linguistic energy of an LLM with the area information of a single doc, our little app will enable us to ask the mannequin questions in English, and it’ll reply our questions by referring to content material in our doc.
For our doc, we’ll use the textual content of President Biden’s February 7, 2023, State of the Union Handle. If you wish to do this at house, you’ll be able to obtain a textual content doc of the speech on the hyperlink beneath.
A production-grade model of this app would enable non-public collections of paperwork (Phrase docs, PDFs, and many others.) to be queried with English questions. Right here we’re constructing a easy system that doesn’t have privateness, because it sends the doc to a public mannequin. Please don’t run this app utilizing non-public paperwork.
We’ll use the hosted embedding and language fashions from OpenAI, and the open-source FAISS (Fb AI Similarity Search) library as our vector retailer, to show a RAG utility finish to finish with the least attainable effort. In a subsequent article we are going to construct a second easy instance utilizing a completely native LLM with no information despatched exterior the app. Utilizing an area mannequin includes extra work and extra shifting components, so it isn’t the perfect first instance.
To construct our easy RAG system we’d like the next parts:
- A doc corpus. Right here we are going to use only one doc.
- A loader for the doc. This code extracts textual content from the doc and pre-processes (tokenizes) it for producing an embedding.
- An embedding mannequin. This mannequin takes the pre-processed doc and creates embeddings that symbolize the doc chunks.
- A vector information retailer with an index for similarity looking.
- An LLM optimized for query answering and instruction.
- A chat template for interacting with the LLM.
The preparatory steps:
pip set up -U langchain pip set up -U langchain_community pip set up -U langchain_openai
The supply code for our RAG system:
# We begin by fetching a doc that hundreds the textual content of President Biden’s 2023 State of the Union Handle
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./stateOfTheUnion2023.txt')
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] =<you will want to get an API ket from OpenAI>
# We load the doc utilizing LangChain’s helpful extractors, formatters, loaders, embeddings, and LLMs
paperwork = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(paperwork)
# We use an OpenAI default embedding mannequin
# Observe the code on this instance doesn't protect privateness
embeddings = OpenAIEmbeddings()
# LangChain supplies API features to work together with FAISS
db = FAISS.from_documents(texts, embeddings)
# We create a 'retriever' that is aware of the way to work together with our vector database utilizing an augmented context
# We may assemble the retriever ourselves from first rules nevertheless it's tedious
# As an alternative we'll use LangChain to create a retriever for our vector database
retriever = db.as_retriever()
from langchain.brokers.agent_toolkits import create_retriever_tool
instrument = create_retriever_tool(
retriever,
"search_state_of_union",
"Searches and returns paperwork concerning the state-of-the-union."
)
instruments = [tool]
# We wrap an LLM (right here OpenAI) with a conversational interface that may course of augmented requests
from langchain.brokers.agent_toolkits import create_conversational_retrieval_agent
# LangChain supplies an API to work together with chat fashions
from langchain_openai.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature = 0)
agent_executor = create_conversational_retrieval_agent(llm, instruments, verbose=True)
enter = "what's NATO?"
outcome = agent_executor.invoke({“enter": enter})
# Response from the mannequin
enter = "When was it created?"
outcome = agent_executor.invoke({“enter": enter})
# Response from the mannequin
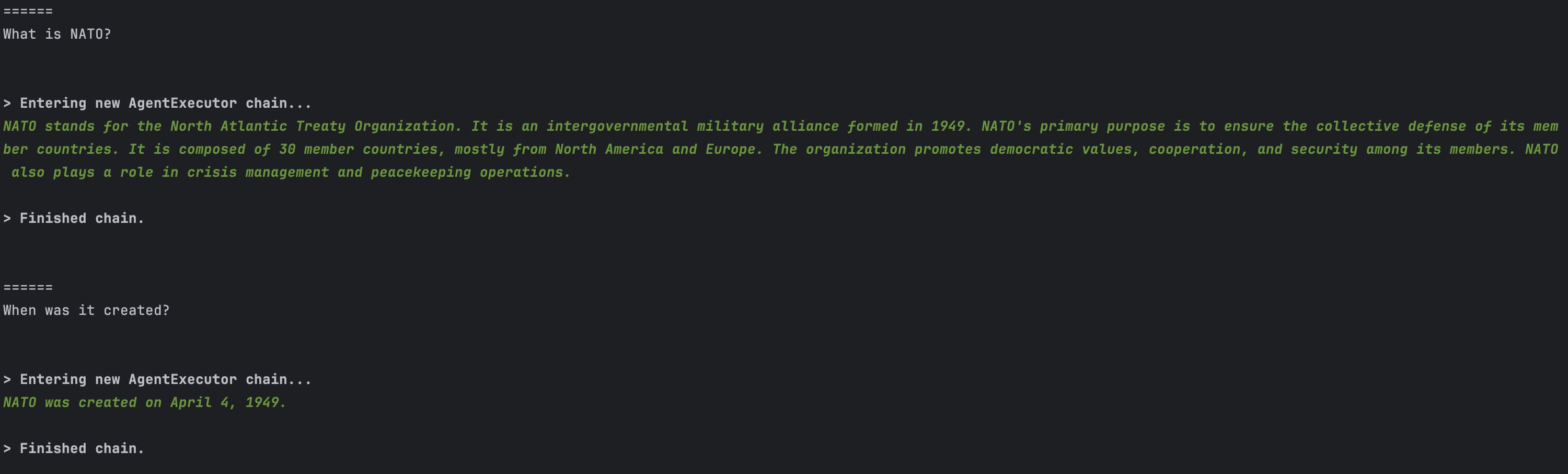 IDG
IDGAs proven within the screenshot above, the mannequin’s response to our first query is sort of correct:
NATO stands for the North Atlantic Treaty Group. It’s an intergovernmental navy alliance shaped in 1949. NATO’s major goal is to make sure the collective protection of its member nations. It’s composed of 30 member nations, largely from North America and Europe. The group promotes democratic values, cooperation, and safety amongst its members. NATO additionally performs an important function in disaster administration and peacekeeping operations world wide.
Completed chain.
And the mannequin’s response to the second query is strictly proper:
NATO was created on April 4, 1949.
Completed chain.
As we’ve seen, the usage of a framework like LangChain significantly simplifies our first steps into LLM purposes. LangChain is strongly advisable if you happen to’re simply beginning out and also you need to strive some toy examples. It should enable you get proper to the meat of retrieval-augmented era, that means the doc ingestion and the interactions between the vector database and the LLM, relatively than getting caught within the plumbing.
For scaling to a bigger corpus and deploying a manufacturing utility, a deeper dive into native LLMs, vector databases, and embeddings will likely be wanted. Naturally, manufacturing deployments will contain way more nuance and customization, however the identical rules apply. We’ll discover native LLMs, vector databases, and embeddings in additional element in future articles right here.
Copyright © 2024 IDG Communications, Inc.