
{kind=link}
Re-envisioning microservices as Flink streaming functions
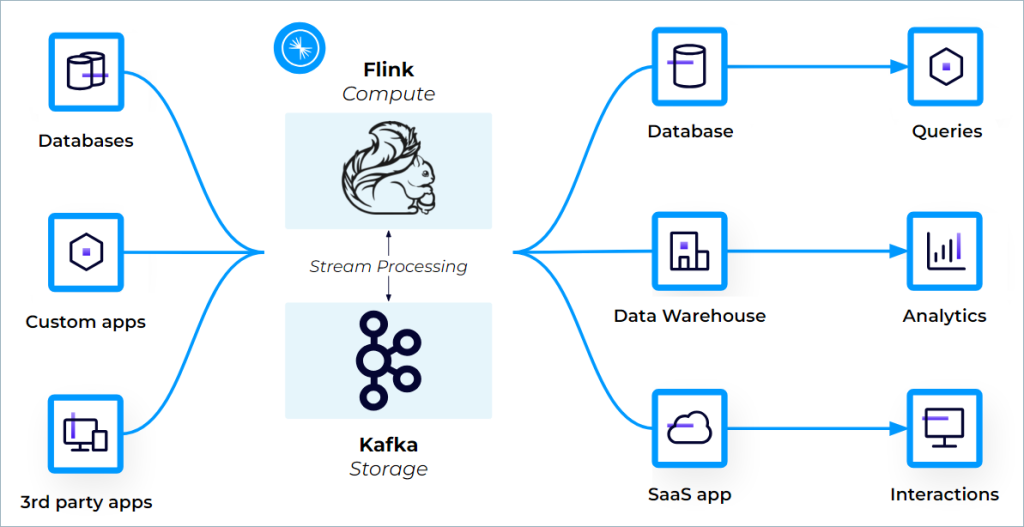
A typical option to course of information is to tug it out of Kafka utilizing a microservice, course of it utilizing the identical or probably a unique microservice, after which dump it again into Kafka or one other queue. Nevertheless, you should utilize Flink paired with Kafka to do all the above, yielding a extra dependable answer with decrease latency, built-in fault tolerance, and occasion ensures.
Confluent
Flink will be set to hear for information coming in, utilizing a steady push course of slightly than a discrete pull. As well as, utilizing Flink as a substitute of a microservice helps you to leverage all of Flink’s built-in accuracies, resembling exactly-once semantics. Flink has a two-phase commit protocol that permits builders to have exactly-once occasion processing ensures end-to-end, which implies that occasions entered into Kafka, for instance, shall be processed precisely as soon as with Kafka and Flink. Observe that the kind of microservice that Flink greatest replaces is one associated to information processing, updating the state of operational analytics.
Use Flink to rapidly apply AI fashions to your information with SQL
Utilizing Kafka and Flink collectively lets you transfer and course of information in actual time and create high-quality, reusable information streams. These capabilities are important for real-time, compound AI functions, which want dependable and available information for real-time decision-making. Suppose retrieval augmented era (RAG) sample, supplementing no matter mannequin we use with right-in-time, high-quality context to enhance the responses and mitigate hallucinations.