
{kind=link}
The article, Machine studying for Java builders: Algorithms for machine studying, launched organising a machine studying algorithm and growing a prediction perform in Java. Readers realized the inside workings of a machine studying algorithm and walked by the method of growing and coaching a mannequin. This text picks up the place that one left off. You will get a fast introduction to Weka, a machine studying framework for Java. Then, you may see tips on how to arrange a machine studying information pipeline, with a step-by-step course of for taking your machine studying mannequin from improvement into manufacturing. We’ll additionally briefly focus on tips on how to use Docker containers and REST to deploy a educated ML mannequin in a Java-based manufacturing atmosphere.
What to anticipate from this text
Deploying a machine studying mannequin isn’t the identical as growing one. These are totally different components of the software program improvement lifecycle, and infrequently carried out by totally different groups. Growing a machine studying mannequin requires understanding the underlying information and having an excellent grasp of arithmetic and statistics. Deploying a machine studying mannequin in manufacturing is usually a job for somebody with each software program engineering and operations expertise.
This text is about tips on how to make a machine studying mannequin obtainable in a extremely scalable manufacturing atmosphere. It’s assumed that you’ve got some improvement expertise and a fundamental understanding of machine studying fashions and algorithms; in any other case, you might wish to begin by studying Machine studying for Java builders: Algorithms for machine studying.
Let’s begin with a fast refresher on supervised studying, together with the instance software we’ll use to coach, deploy, and course of a machine studying mannequin to be used in manufacturing.
Supervised machine studying: A refresher
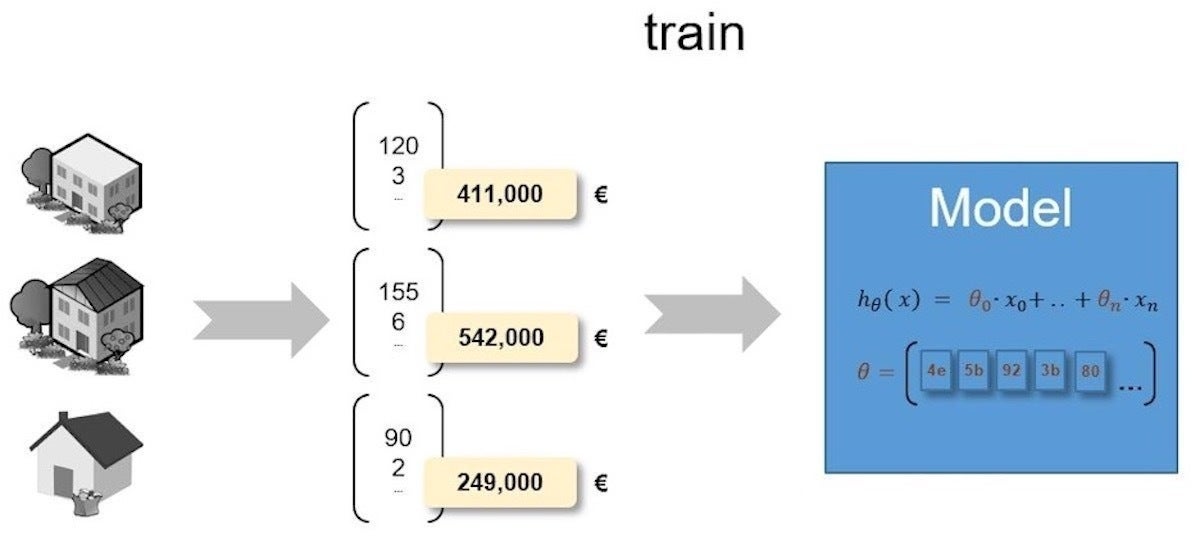
A easy, supervised machine studying mannequin will illustrate the ML deployment course of. The mannequin proven in Determine 1 can be utilized to foretell the anticipated sale value of a home.
 IDG
IDGDetermine 1. Skilled supervised machine studying mannequin on the market value prediction.
Recall {that a} machine studying mannequin is a perform with inside, learnable parameters that map inputs to outputs. Within the above diagram, a linear regression perform, hθ(x), is used to foretell the sale value for a home based mostly on a wide range of options. The x variables of the perform signify the enter information. The θ (theta) variables represents the interior, learnable mannequin parameters.
To foretell the sale value of a home, you have to first create an enter information array of x variables. This array incorporates options equivalent to the scale of the lot or the variety of rooms in a home. This array is named the function vector.
As a result of most machine studying features require a numerical illustration of options, you’ll probably must carry out some information transformations to be able to construct a function vector. As an illustration, a function specifying the placement of the storage might embody labels equivalent to “hooked up to residence” or “built-in,” which must be mapped to numerical values. Once you execute the house-price prediction, the machine studying perform will probably be utilized with this enter function vector in addition to the interior, educated mannequin parameters. The perform’s output is the estimated home value. This output is named a label.
Coaching the mannequin
Inside, learnable mannequin parameters (θ) are the a part of the mannequin that’s realized from coaching information. The learnable parameters will probably be set through the coaching course of. A supervised machine studying mannequin just like the one proven beneath must be educated to be able to make helpful predictions.
 IDG
IDGDetermine 2. An untrained supervised machine studying mannequin
Sometimes, the coaching course of begins with an untrained mannequin the place all of the learnable parameters are set with an preliminary worth equivalent to zero. The mannequin consumes information about numerous home options together with actual home costs. Step by step, it identifies correlations between home options and home costs, in addition to the burden of those relationships. The mannequin adjusts its inside, learnable mannequin parameters and makes use of them to make predictions.
 IDG
IDGDetermine 3. A educated supervised machine studying mannequin
After the coaching course of, the mannequin will be capable to estimate the sale value of a home by assessing its options.
Machine studying algorithms in Java code
The HousePriceModel gives two strategies. Considered one of them implements the training algorithm to coach (or match) the mannequin. The opposite technique is used for predictions.
 IDG
IDGDetermine 4. Two strategies in a machine studying mannequin
The match() technique
The match() technique is used to coach the mannequin. It consumes home options in addition to house-sale costs as enter parameters however returns nothing. This technique requires the right “reply” to have the ability to modify its inside mannequin parameters. Utilizing housing listings paired with sale costs, the training algorithm seems for patterns within the coaching information. From these, it produces mannequin parameters that generalize from these patterns. Because the enter information turns into extra correct, the mannequin’s inside parameters are adjusted.
Itemizing 1. The match() technique is used to coach a machine studying mannequin
// load coaching information
// ...
// e.g. [{MSSubClass=60.0, LotFrontage=65.0, ...}, {MSSubClass=20.0, ...}]
Listing<Map<String, Double>> homes = ...;
// e.g. [208500.0, 181500.0, 223500.0, 140000.0, 250000.0, ...]
Listing<Double> costs = ...;
// create and practice the mannequin
var mannequin = new HousePriceModel();
mannequin.match(homes, costs);
Word that the home options are double typed within the code. It is because the machine studying algorithm used to implement the match() technique requires numbers as enter. All home options have to be represented numerically in order that they can be utilized as x parameters within the linear regression formulation, as proven right here:
hθ(x) = θ0 * x0 + ... + θn * xn
The educated home value prediction mannequin might appear like what you see beneath:
value = -490130.8527 * 1 + -241.0244 * MSSubClass + -143.716 * LotFrontage + … * …
Right here, the enter home options equivalent to MSSubClass or LotFrontage are represented as x variables. The learnable mannequin parameters (θ) are set with values like -490130.8527 or -241.0244, which have been gained through the coaching course of.
This instance makes use of a easy machine studying algorithm, which requires only a few mannequin parameters. A extra complicated algorithm, equivalent to for a deep neural community, might require hundreds of thousands of mannequin parameters; that is without doubt one of the predominant the explanation why the method of coaching such algorithms requires excessive computation energy.
The predict() technique
After getting completed coaching the mannequin, you should utilize the predict() technique to find out the estimated sale value of a home. This technique consumes information about home options and produces an estimated sale value. In apply, an agent of an actual property firm might enter options equivalent to the scale of loads (lot-area), the variety of rooms, or the general home high quality to be able to obtain an estimated sale value for a given home.
Remodeling non-numeric values
You’ll typically be confronted with datasets that include non-numeric values. As an illustration, the Ames Housing dataset used for the Kaggle Home Costs competitors consists of each numeric and textual listings of home options:
 IDG
IDGDetermine 5. A pattern from the Kaggle Home Costs dataset
To make issues extra difficult, the Kaggle dataset additionally consists of empty values (marked NA), which can’t be processed by the linear regression algorithm proven in Itemizing 1.
Actual-world information information are sometimes incomplete, inconsistent, missing in desired behaviors or developments, and should include errors. This sometimes happens in instances the place the enter information has been joined utilizing totally different sources. Enter information have to be transformed right into a clear information set earlier than being fed right into a mannequin.
To enhance the info, you would wish to exchange the lacking (NA) numeric LotFrontage worth. You’ll additionally want to exchange textual values equivalent to MSZoning “RL” or “RM” with numeric values. These transformations are essential to convert the uncooked information right into a syntactically right format that may be processed by your mannequin.
As soon as you’ve got transformed your information to a usually readable format, you should still have to make extra modifications to enhance the standard of enter information. As an illustration, you would possibly take away values not following the final development of the info, or place sometimes occurring classes right into a single umbrella class.
Java-based machine studying with Weka
As you’ve got seen, growing and testing a goal perform requires well-tuned configuration parameters, equivalent to the right studying price or iteration rely. The instance code you’ve got seen up to now displays a really small set of the potential configuration parameters, and the examples had been simplified to maintain the code readable. In apply, you’ll probably depend on machine studying frameworks, libraries, and instruments.
Most frameworks or libraries implement an intensive assortment of machine studying algorithms. Moreover, they supply handy high-level APIs to coach, validate, and course of information fashions. Weka is without doubt one of the hottest frameworks for the JVM.
Weka gives a Java library for programmatic utilization, in addition to a graphical workbench to coach and validate information fashions. Within the code beneath, the Weka library is used to create a coaching information set, which incorporates options and a label. The setClassIndex() technique is used to mark the label column. In Weka, the label is outlined as a category:
// outline the function and label attributes
ArrayList<Attribute> attributes = new ArrayList<>();
Attribute sizeAttribute = new Attribute("sizeFeature");
attributes.add(sizeAttribute);
Attribute squaredSizeAttribute = new Attribute("squaredSizeFeature");
attributes.add(squaredSizeAttribute);
Attribute priceAttribute = new Attribute("priceLabel");
attributes.add(priceAttribute);
// create and fill the options listing with 5000 examples
Cases trainingDataset = new Cases("trainData", attributes, 5000);
trainingDataset.setClassIndex(trainingSet.numAttributes() - 1);
Occasion occasion = new DenseInstance(3);
occasion.setValue(sizeAttribute, 90.0);
occasion.setValue(squaredSizeAttribute, Math.pow(90.0, 2));
occasion.setValue(priceAttribute, 249.0);
trainingDataset.add(occasion);
Occasion occasion = new DenseInstance(3);
occasion.setValue(sizeAttribute, 101.0);
...
The info set or Occasion object may also be saved and loaded as a file. Weka makes use of an ARFF (Attribute Relation File Format), which is supported by the graphical Weka workbench. This information set is used to coach the goal perform, often known as a classifier in Weka.
Recall that to be able to practice a goal perform, you must first select the machine studying algorithm. The code beneath creates an occasion of the LinearRegression classifier. This classifier is educated by calling the buildClassifier() technique. The buildClassifier() technique tunes the theta parameters based mostly on the coaching information to seek out the best-fitting mannequin. Utilizing Weka, you would not have to fret about setting a studying price or iteration rely. Weka additionally does the function scaling internally:
Classifier targetFunction = new LinearRegression();
targetFunction.buildClassifier(trainingDataset);
As soon as it is established, the goal perform can be utilized to foretell the value of a home, as proven right here:
Cases unlabeledInstances = new Cases("predictionset", attributes, 1);
unlabeledInstances.setClassIndex(trainingSet.numAttributes() - 1);
Occasion unlabeled = new DenseInstance(3);
unlabeled.setValue(sizeAttribute, 1330.0);
unlabeled.setValue(squaredSizeAttribute, Math.pow(1330.0, 2));
unlabeledInstances.add(unlabeled);
double prediction = targetFunction.classifyInstance(unlabeledInstances.get(0));
Weka gives an Analysis class to validate the educated classifier or mannequin. Within the code beneath, a devoted validation information set is used to keep away from biased outcomes. Measures equivalent to the associated fee or error price will probably be printed to the console. Sometimes, analysis outcomes are used to match fashions which were educated utilizing totally different machine-learning algorithms, or a variant of those:
Analysis analysis = new Analysis(trainingDataset);
analysis.evaluateModel(targetFunction, validationDataset);
System.out.println(analysis.toSummaryString("Outcomes", false));
The examples above use linear regression, which predicts a numeric-valued output equivalent to a home value based mostly on enter values. Linear regression helps the prediction of steady, numeric values. To foretell binary sure/no values or classifiers, you might use a machine studying algorithm equivalent to resolution tree, neural community, or logistic regression:
// utilizing logistic regression
Classifier targetFunction = new Logistic();
targetFunction.buildClassifier(trainingSet);