
{kind=link}
Deliver this venture to life
The rise of text-to-image fashions marks a transformative shift within the discipline of synthetic intelligence, unlocking new prospects for artistic expression and communication. These fashions leverage superior deep studying strategies to generate sensible and contextually related pictures primarily based on textual enter. The combination of pure language processing and laptop imaginative and prescient has paved the best way for purposes that may interpret and translate textual descriptions into visually compelling representations. As these fashions proceed to evolve and enhance, they maintain the potential to revolutionize numerous industries, together with design, leisure, and training, by offering a seamless bridge between the world of language and imagery.
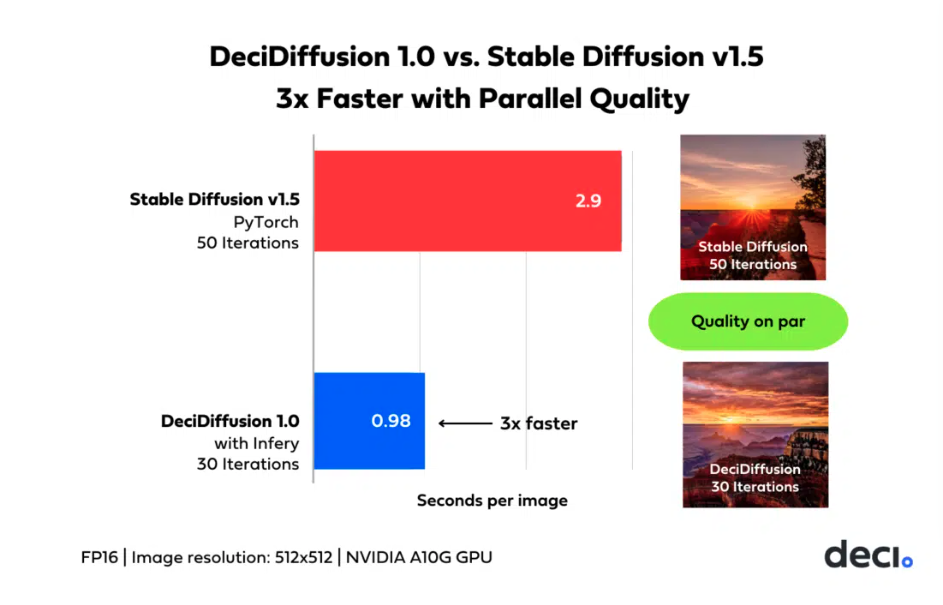
DeciDiffusion is an open supply leading edge text-to-image latent diffusion mannequin educated on a subset of the LAION dataset and fine-tuned on the LAION-ART dataset. This diffusion mannequin with 1.02 billion parameter, surpasses the 1.07 billion parameter Secure Diffusion v1.5 (SD), which is of the same measurement, whereas reaching equal high quality in picture technology with 40% fewer iterations. The mannequin has additionally confirmed to be 3X sooner than Secure Diffusion v1.5, when run on NVIDIA A10G GPUs. This efficiency is as a result of superior Neural Structure Search Know-how structure of the mannequin, which was developed for optimum effectivity.
DeciDiffusion’s enhanced capabilities are extra profound than these of SD. Allow us to talk about the implications of DeciDiffusion briefly.
The text-to-image technology mannequin holds immense potential within the discipline of design, artwork, promoting, content material creation and lots of extra. The rise of this expertise lies in its seamless potential to effortlessly convert textual content into vibrant pictures, representing a major development in AI capabilities. Whereas SD being open supply has spurred quite a few improvements, it takes a backseat on the subject of the sensible challenges in deployment because of its demanding computational necessities, although the rise of Turbo fashions and distillation could show that assumption fallacious.
These challenges end in noticeable latency and value points throughout coaching and deployment. In distinction, DeciDiffusion stands out for its superior computational effectivity, making certain a smoother consumer expertise and a formidable discount of almost 66% in manufacturing prices. The result is a extra accessible and possible panorama for text-to-image generative purposes working with the mannequin versus different Latent Diffusion fashions.
On this article, we are going to take a look at what makes DeciDiffusion so highly effective and versatile, after which present it with a sensible demonstration in a Paperspace Pocket book.
Mannequin Structure
DeciDiffusion 1.0, a text-to-image technology mannequin, builds upon Secure Diffusion’s core structure, incorporating developments just like the U-Internet-NAS design by Deci. This substitution optimizes the mannequin for higher computational effectivity by lowering parameter rely whereas retaining the Variational Autoencoder (VAE) and CLIP’s Textual content Encoder.
U-Internet-NAS
DeciDiffusion can be a latent diffusion mannequin, like Secure Diffusion, nevertheless the structure relies on U-Internet-NAS. Latent diffusion fashions are probabilistic frameworks able to producing high-quality pictures. They provoke the picture technology course of by remodeling random noise into sensible pictures by means of a gradual diffusion course of. The distinctive characteristic of those fashions lies in making use of the diffusion course of to an encoded latent illustration of the picture somewhat than the uncooked pixel values.
Listed here are the primary steps concerned:
- Variational Auto-Encoder (VAE): Variational Autoencoder (VAE) is an AutoEncoder structure that undergoes regularization of its encoding distribution throughout coaching. This regularization ensures favorable properties in its latent area, facilitating the technology of recent information. The time period “variational” is derived from the robust connection between this regularization and the variational inference methodology in statistics. In a nutshell, VAEs convert pictures into latent representations and vice versa. All through coaching, the encoder transforms a picture right into a latent model, and the decoder reverses this course of throughout each coaching and inference.
- U-Internet: Named after its architectural design, U-Internet contains a “U” formed mannequin consisting of convolutional layers and two networks—the encoder adopted by the decoder. This mannequin successfully addresses the segmentation questions of “what” and “the place.”
- Textual content Encoder: This encoder is accountable to rework textual prompts to latent textual content embeddings which is additional utilized by the U-Internet decoder.
U-Internet-NAS
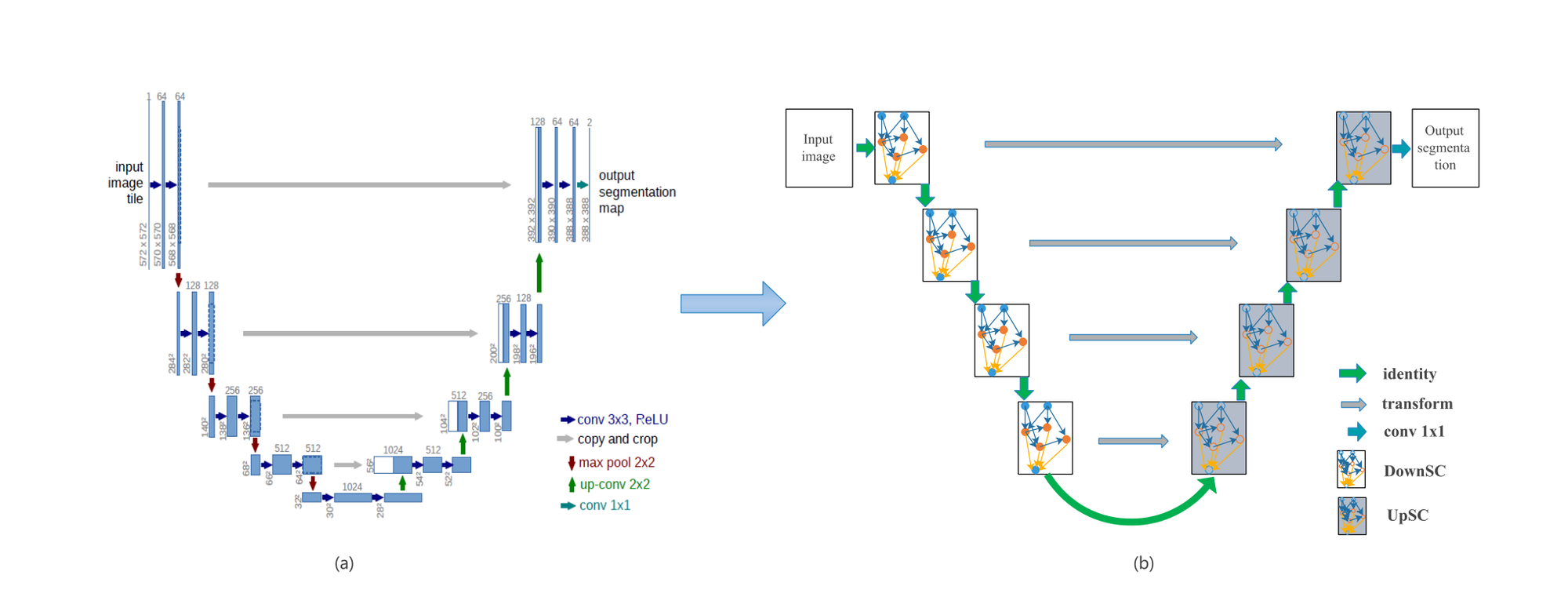
On this structure two kinds of cell architectures are outlined, referred to as DownSC and UpSC primarily based on U-like spine. DeciDiffusion stands out for its distinctive characteristic: the versatile composition of every block, optimizing the variety of ResNet and Consideration blocks for peak efficiency with minimal computations. By adopting the environment friendly U-Internet-NAS in DeciDiffusion, characterised by fewer parameters, the mannequin reduces computational calls for, making it a extra resource-efficient various to Secure Diffusion.
The mannequin has been educated on 4 levels:
- Part 1: Skilled for 1.28 million steps at a decision of 256×256 utilizing a subset of 320 million samples from LAION-v2, ranging from scratch.
- Part 2: Additional coaching concerned 870k steps at a 512×512 decision on the identical dataset to seize finer particulars.
- Part 3: Performed coaching for 65k steps utilizing Exponential Transferring Common (EMA), a further studying fee scheduler, and incorporating extra “qualitative” information.
- Part 4: Positive-tuning utilizing a 2M pattern subset of LAION-ART.
{Hardware} Necessities for Coaching
The {hardware} necessities for coaching DeciDiffusion have been fairly excessive. Recreating the method on Paperspace could be attainable utilizing the 8xH100 machines.
DeciDiffusion in motion
We extremely advocate our readers make the most of the Paperspace platform to deliver this mannequin to life. Be at liberty to click on on the hyperlink supplied on this article to discover the Paperspace platform and expertise the capabilities of this mannequin. Please notice this hyperlink will spin up a free GPU (M4000). Nonetheless, Progress and Professional plan customers could wish to think about switching to a extra highly effective machine kind. We are able to edit the machine alternative within the URL the place it says “Free-GPU” by changing that worth with one other GPU code from our machine choice. As soon as the online web page has loaded, click on “Begin Machine” to start launching the Pocket book.
Deliver this venture to life
Observe the steps to make use of this mannequin and produce some thoughts blowing pictures!
- Set up the mandatory packages
#set up the packages utilizing pip
!pip set up --quiet git+https://github.com/huggingface/diffusers.git@d420d71398d9c5a8d9a5f95ba2bdb6fe3d8ae31f
!pip set up --quiet ipython-autotime
!pip set up --quiet transformers==4.34.1 speed up==0.24.0 safetensors==0.4.0
!pip set up --quiet ipyplot
%load_ext autotime- Import the Libraries and essential packages
#import essential libraries
from diffusers import StableDiffusionPipeline, DiffusionPipeline
import torch
import ipyplot
import time- Hundreds the pre-trained checkpoint, “DeciDiffusion-v1-0” for a Secure Diffusion pipeline. Run the mannequin with two prompts. The ensuing pictures are saved within the ‘img’ and ‘img2’ variables.
#set the machine and cargo the pre-trained mannequin
machine="cuda" if torch.cuda.is_available() else 'cpu'
checkpoint = "Deci/DeciDiffusion-v1-0"
#biuld the decidiffusion pipeline
pipeline = StableDiffusionPipeline.from_pretrained(checkpoint, custom_pipeline=checkpoint, torch_dtype=torch.float16)
pipeline.unet = pipeline.unet.from_pretrained(checkpoint, subfolder="flexible_unet", torch_dtype=torch.float16)
pipeline = pipeline.to(machine)
#generate pictures by passing immediate
img = pipeline(immediate=['A photo of an astronaut riding a horse on Mars']).pictures[0]
img2 = pipeline(immediate=['A big owl with bright shinning eyes']).pictures[0]

Comparability of DeciDiffusion with Secure Diffusion v1.5
Time taken by SD mannequin to generate the pictures:

Time taken by DeciDiffusion mannequin to generate the pictures:

DeciDiffusion’s improved latency is a results of developments in its structure, environment friendly coaching strategies enhancing pattern effectivity, and the mixing of Infery, Deci’s simple to make use of SDK, can improve this even additional. This mixture leads to important value financial savings throughout inference operations. Firstly, it gives flexibility in {hardware} choice, enabling a transition from high-end A100/H100 GPUs to the extra budget-friendly A10G with out sacrificing efficiency (we nonetheless advocate utilizing an A100-80G or H100 on Paperspace although). Furthermore, compared on the identical {hardware}, DeciDiffusion proves extremely cost-effective, with a 66% discount in value in comparison with Secure Diffusion for each 10,000 generated pictures.
Concluding Ideas
DeciDiffusion, represents a vital development for generative AI purposes. This not solely optimizes real-time tasks in content material creation and promoting but in addition results in substantial reductions in operational prices. On this article we in contrast DeciDiffusion with SD and it may be concluded that the mannequin is quicker and extra environment friendly than SD to each prepare and use for inference. Nonetheless it’s price mentioning that the mannequin shouldn’t be meant to generate correct or truthful representations of individuals or occasions. Subsequently, using it for such functions goes past its designated capabilities. Additionally, the mannequin has its personal limitations. Listed here are few of them:
- The mannequin is unable to provide to utterly photorealistic pictures. Artifacting is widespread
- Advanced compositions are nonetheless a problem to the mannequin and the autoencoding facet of the mannequin remains to be a loss.
- Technology of excellent faces and human figures are in-fact problem for each diffusion mannequin.
- DeciDiffusion is primarily optimized for English captions and isn’t efficient with different languages.
Nonetheless, the mannequin has its personal perks particularly on the subject of its computation energy and value effectiveness. Together with this text we’ve supplied two notebooks primarily based on DeciDiffusion and Secure Diffusion. We encourage customers to make the most of these notebooks along with the article for an enriched expertise.
I belief you discovered this text helpful. Thanks sincerely to your readership!