
{kind=link}
Massive language fashions like ChatGPT and Bard have raised machine studying to the standing of a phenomenon. Their use for coding help has rapidly earned these instruments a spot within the developer’s toolkit. Different use instances are being explored, starting from picture era to illness detection.
Tech corporations are investing closely in machine studying, so understanding the right way to practice and work with fashions is changing into important for builders.
This text will get you began with machine studying in Java. You’ll get a primary take a look at how machine studying works, adopted by a brief information to implementing and coaching a machine studying algorithm. We’ll deal with supervised machine studying, which is the commonest strategy to growing clever functions.
Machine studying and AI
Machine studying has developed from the sphere of synthetic intelligence (AI), which seeks to provide machines able to mimicking human intelligence. Though machine studying is a scorching pattern in pc science, AI shouldn’t be a brand new subject in science. The Turing take a look at, developed by Alan Turing within the early Nineteen Fifties, was one of many first assessments created to find out whether or not a pc may have actual intelligence. In accordance with the Turing take a look at, a pc may show human intelligence by tricking a human into believing it was additionally human.
Many state-of-the-art machine studying approaches are primarily based on decades-old ideas. What has modified over the previous decade is that computer systems (and distributed computing platforms) now have the processing energy required for machine studying algorithms. Most machine studying algorithms demand an enormous variety of matrix multiplications and different mathematical operations to course of. The computational expertise to handle these calculations did not exist even twenty years in the past, nevertheless it does in the present day. Parallel processing and devoted chips, in addition to huge knowledge, have radically elevated the capability of machine studying platforms.
Machine studying allows applications to execute high quality enchancment processes and lengthen their capabilities with out human involvement. Some applications constructed with machine studying are even able to updating or extending their very own code.
How machines be taught
Supervised studying and unsupervised studying are the most well-liked approaches to machine studying. Each require feeding the machine an enormous variety of knowledge information to correlate and be taught from. Such collected knowledge information are generally often known as a characteristic vectors. Within the case of a person home, a characteristic vector may encompass options resembling total home measurement, variety of rooms, and the age of the home.
Supervised studying
In supervised studying, a machine studying algorithm is skilled to accurately reply to questions associated to characteristic vectors. To coach an algorithm, the machine is fed a set of characteristic vectors and an related label. Labels are usually offered by a human annotator and signify the suitable reply to a given query. The educational algorithm analyzes characteristic vectors and their right labels to seek out inside buildings and relationships between them. Thus, the machine learns to accurately reply to queries.
For example, an clever actual property software could be skilled with characteristic vectors together with the respective measurement, variety of rooms, and age of a variety of homes. A human labeller would label every home with the proper home value primarily based on these components. By analyzing the information, the actual property software can be skilled to reply the query, “How a lot cash may I get for this home?”
After the coaching course of is over, new enter knowledge shouldn’t be labeled. The machine is ready to accurately reply to new queries, even for unseen, unlabeled characteristic vectors.
Unsupervised studying
In unsupervised studying, the algorithm is programmed to foretell solutions with out human labeling, and even questions. Reasonably than predetermine labels or what the outcomes must be, unsupervised studying harnesses large knowledge units and processing energy to find beforehand unknown correlations. In shopper product advertising, for example, unsupervised studying might be used to establish hidden relationships or shopper grouping, ultimately resulting in new or improved advertising methods.
This text focuses on supervised machine studying, which is at the moment the commonest strategy to machine studying.
A supervised machine studying undertaking
Now let’s take a look at an instance: a supervised studying undertaking for an actual property software.
All machine studying is predicated on knowledge. Primarily, you enter many cases of knowledge and the real-world outcomes of that knowledge, and the algorithm varieties a mathematical mannequin primarily based on these inputs. The machine ultimately learns to make use of new knowledge to foretell unknown outcomes.
For a supervised machine studying undertaking, you have to to label the information in a significant manner for the end result you might be looking for. In Desk 1, notice that every row of the home file features a label for “home value.” By correlating row knowledge to the home value label, the algorithm will ultimately be capable to predict market value for a home not in its knowledge set (notice that home measurement is predicated on sq. meters, and home value is predicated on euros).
Desk 1. Home information
| FEATURE | FEATURE | FEATURE | LABEL |
| Dimension of Home | Variety of Rooms | Age of Home | Estimated Value |
|
90 m2 / 295 ft |
2 | 23 years |
249,000 € |
|
101 m2 / 331 ft |
3 | N/A |
338,000 € |
|
1330 m2 / 4363 ft |
11 | 12 years |
6,500,000 € |
Within the early phases, you’ll probably label the information information by hand, however you might ultimately practice your program to automate this course of. You’ve got most likely seen this with electronic mail functions, the place shifting electronic mail into your spam folder leads to the question “Is that this spam?” If you reply, you might be coaching this system to acknowledge mail that you do not wish to see. The appliance’s spam filter learns to label and eliminate future mail from the identical supply or containing comparable content material.
Labeled knowledge units are solely required for coaching and testing functions. After this section is over, the machine studying mannequin works on unlabeled knowledge cases. For example, you might feed the prediction algorithm a brand new, unlabeled home file and it could robotically predict the anticipated home value primarily based on coaching knowledge.
Coaching a machine studying mannequin
The problem of supervised machine studying is to seek out the correct prediction operate for a particular query. Mathematically, the problem is to seek out the enter/output operate that takes the enter variable x and returns the prediction worth y. This speculation operate (hθ) is the output of the coaching course of. Typically, the speculation operate can be known as goal or prediction operate.
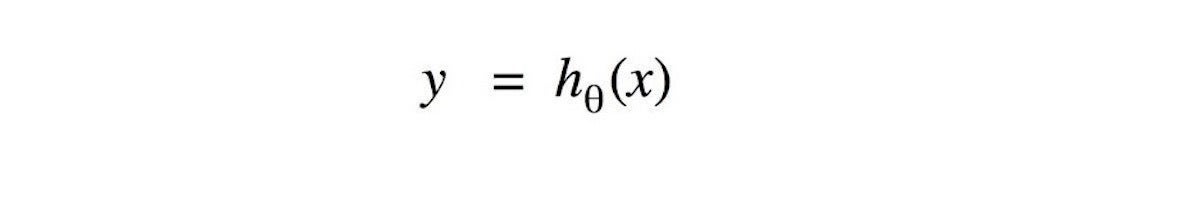 Gregor Roth
Gregor RothDetermine 1. Instance of a goal operate
Normally, x represents a multiple-data level. In our instance, this might be a two-dimensional knowledge level of a person home outlined by the house-size worth and the number-of-rooms worth. The array of those values is known as the characteristic vector. Given a concrete goal operate, the operate can be utilized to make a prediction for every characteristic vector, x. To foretell the value of a person home, you might name the goal operate by utilizing the characteristic vector { 101.0, 3.0 }, which comprises the home measurement and the variety of rooms:
Itemizing 1. Calling the goal operate with a characteristic vector
// goal operate h (which is the output of the be taught course of)
Perform<Double[], Double> h = ...;
// set the characteristic vector with home measurement=101 and number-of-rooms=3
Double[] x = new Double[] { 101.0, 3.0 };
// and predicted the home value (label)
double y = h.apply(x);
In Itemizing 1, the array variable x worth represents the characteristic vector of the home. The y worth returned by the goal operate is the expected home value.
The problem of machine studying is to outline a goal operate that can work as precisely as doable for unknown, unseen knowledge cases. In machine studying, the goal operate (hθ) is usually known as a mannequin. This mannequin is the results of the training course of, additionally known as mannequin coaching.
 Gregor Roth
Gregor RothDetermine 2. A machine studying mannequin
Based mostly on labeled coaching examples, the training algorithm appears to be like for buildings or patterns within the coaching knowledge. It does this with a course of often known as again propagation, the place values are steadily modified to scale back loss. From these, it produces a mannequin that is ready to generalize from that knowledge.
Usually, the training course of is explorative. Normally, the method will probably be executed a number of occasions utilizing totally different variations of studying algorithms and configurations. When a mannequin is settled upon, the information is run by way of it many occasions as effectively. These iterations are often known as epochs.
Ultimately, all of the fashions will probably be evaluated primarily based on efficiency metrics. The most effective one will probably be chosen and used to compute predictions for future unlabeled knowledge cases.
Linear regression
To coach a machine to suppose, step one is to decide on the training algorithm you will use. Linear regression is among the easiest and hottest supervised studying algorithms. This algorithm assumes that the connection between enter options and the output label is linear. The generic linear regression operate in Determine 3 returns the expected worth by summarizing every ingredient of the characteristic vector multiplied by a theta parameter (θ). The theta parameters are used inside the coaching course of to adapt or “tune” the regression operate primarily based on the coaching knowledge.
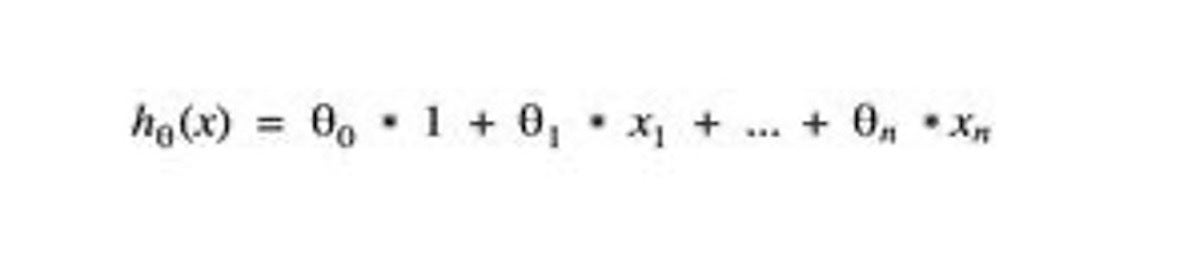 Gregor Roth
Gregor RothDetermine 3. A generic linear regression operate
Linear regression is a straightforward type of studying operate, nevertheless it gives foundation for the extra superior varieties like gradient descent, which is utilized in feed ahead neural networks. Within the linear regression operate, theta parameters and have parameters are enumerated by a subscription quantity. The subscription quantity signifies the place of theta parameters (θ) and have parameters (x) inside the vector. Word that characteristic x0 is a continuing offset time period set with the worth 1 for computational functions. In consequence, the index of a domain-specific characteristic resembling house-size will begin with x1. So, if x1 is about for the primary worth of the Home characteristic vector, house-size, then x2 will probably be set for the subsequent worth, number-of-rooms, and so forth.
Itemizing 2 exhibits a Java implementation of this linear regression operate, proven mathematically as hθ(x). For simplicity, the calculation is completed utilizing the information kind double. Inside the apply() methodology, it’s anticipated that the primary ingredient of the array has been set with a worth of 1.0 outdoors of this operate.
Itemizing 2. Linear regression in Java
public class LinearRegressionFunction implements Perform<Double[], Double> {
personal ultimate double[] thetaVector;
LinearRegressionFunction(double[] thetaVector) {
this.thetaVector = Arrays.copyOf(thetaVector, thetaVector.size);
}
public Double apply(Double[] featureVector) {
// for computational causes the primary ingredient needs to be 1.0
assert featureVector[0] == 1.0;
// easy, sequential implementation
double prediction = 0;
for (int j = 0; j < thetaVector.size; j++) {
prediction += thetaVector[j] * featureVector[j];
}
return prediction;
}
public double[] getThetas() {
return Arrays.copyOf(thetaVector, thetaVector.size);
}
}
To be able to create a brand new occasion of the LinearRegressionFunction, you will need to set the theta parameter. The theta parameter, or vector, is used to adapt the generic regression operate to the underlying coaching knowledge. This system’s theta parameters will probably be tuned through the studying course of, primarily based on coaching examples. The standard of the skilled goal operate can solely be pretty much as good as the standard of the given coaching knowledge.
Within the subsequent instance, the LinearRegressionFunction will probably be instantiated to foretell the home value primarily based on home measurement. Contemplating that x0 needs to be a continuing worth of 1.0, the goal operate is instantiated utilizing two theta parameters. The theta parameters are the output of a studying course of. After creating the brand new occasion, the value of a home with measurement of 1330 sq. meters will probably be predicted as follows:
// the theta vector used right here was output of a practice course of
double[] thetaVector = new double[] { 1.004579, 5.286822 };
LinearRegressionFunction targetFunction = new LinearRegressionFunction(thetaVector);
// create the characteristic vector operate with x0=1 (for computational causes) and x1=house-size
Double[] featureVector = new Double[] { 1.0, 1330.0 };
// make the prediction
double predictedPrice = targetFunction.apply(featureVector);
The goal operate’s prediction line is proven as a blue line in Determine 4. The road has been computed by executing the goal operate for all of the house-size values. The chart additionally consists of the price-size pairs used for coaching.
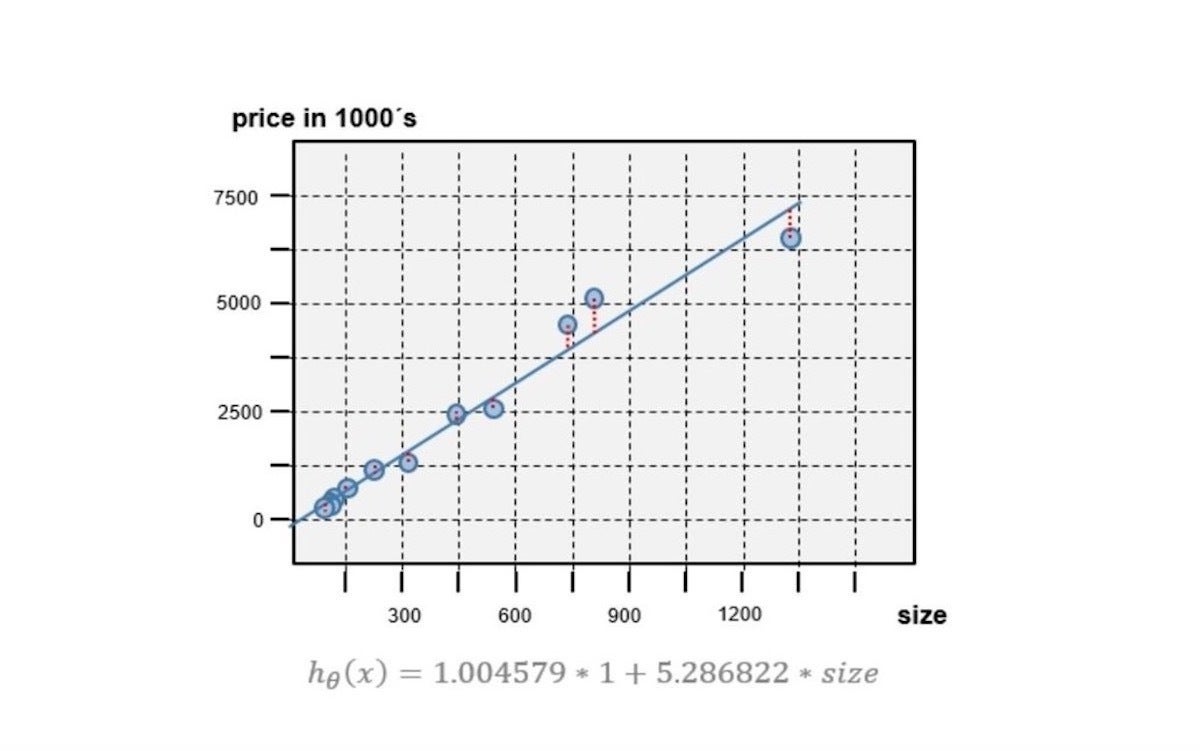 Gregor Roth
Gregor RothDetermine 4. The goal operate’s prediction line