
{kind=link}
Deliver this undertaking to life

Introduction
The Section Something activity includes picture segmentation by producing a segmentation masks successfully primarily based on numerous prompts. These prompts can take varied types, together with foreground/background level units, approximate bins or masks, free-form textual content, or any info indicating the content material to be segmented inside a picture. Picture segmentation stands as an important activity in laptop imaginative and prescient, enjoying a pivotal position in extracting precious info from photos. One of many key advantages of picture segmentation is extracting essential info from a picture which consists of a number of objects. Dividing a picture into a number of segments makes it simpler to research every phase individually. This helps laptop imaginative and prescient algorithms analyze particular person segments of a picture, permitting the identification and monitoring of particular objects in picture or video streams. Picture segmentation finds its purposes in numerous fields, resembling medical imaging, autonomous autos, robotics, agriculture, and gaming.
The Section Something Mannequin (SAM) has had a notable affect on varied laptop imaginative and prescient duties, serving as a brand new, foundational mannequin for duties resembling picture segmentation, captioning, and enhancing. Regardless of its significance, the mannequin requires substantial computation prices, significantly due to the Imaginative and prescient Transformer structure (ViT) at excessive resolutions. The current paper Quick Section Something by Xu Zhao et al., 2023 introduces another technique aimed toward attaining this important activity whereas sustaining low computation value.
On this weblog submit we are going to focus on this revolutionary technique: FastSAM, a real-time CNN-based resolution for the Section Something activity. The principle goal of this technique is to phase any object inside a picture utilizing varied potential prompts initiated by person interplay.
Quick Section Something Mannequin (FastSAM)
In distinction to convolutional counterparts, Imaginative and prescient Transformers (ViTs) are notable for his or her excessive calls for on computational assets. This poses a problem to their sensible deployment, significantly in real-time purposes, limiting their potential affect on advancing the phase something activity. SAM has been considered the milestone imaginative and prescient basis mannequin. The mannequin has been skilled on the SA-1B dataset, which supplies the power to deal with a variety of scenes and objects. Nevertheless, because of the transformer structure causes a limitation to its utilization.
FastSAM makes use of the computational effectivity of Convolutional Neural Networks (CNNs), for example that it’s potential to attain a real-time mannequin for segmenting something with out considerably compromising efficiency high quality.
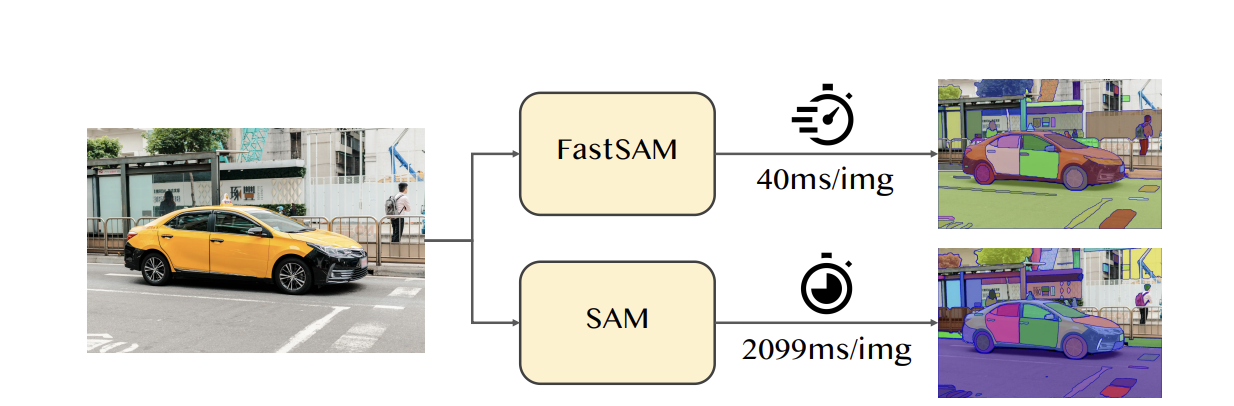
FastSAM is constructed upon YOLOv8-seg, from longtime Paperspace good friend Ultralytics, an object detector with an occasion segmentation department primarily based on the YOLACT technique. By using solely 2% of the SA-1B dataset, FastSAM has achieved a comparable efficiency to SAM at considerably decrease computational calls for, permitting for purposes to run in real-time. The mannequin is utilized to varied segmentation duties, demonstrating its generalization.
FastSAM goals to beat the constraints of the SAM, identified for its demanding computational assets on account of its in depth Transformer structure. FastSAM takes a special strategy by breaking down the phase something activity into two consecutive phases: the primary stage employs YOLOv8-seg to generate segmentation masks for all situations within the picture, and the second stage outputs the region-of-interest akin to the given immediate via prompt-guided choice.
Overview
The strategy contains of two phases: the All-instance Segmentation serves as the inspiration, whereas the Immediate-guided Choice is basically task-oriented post-processing.
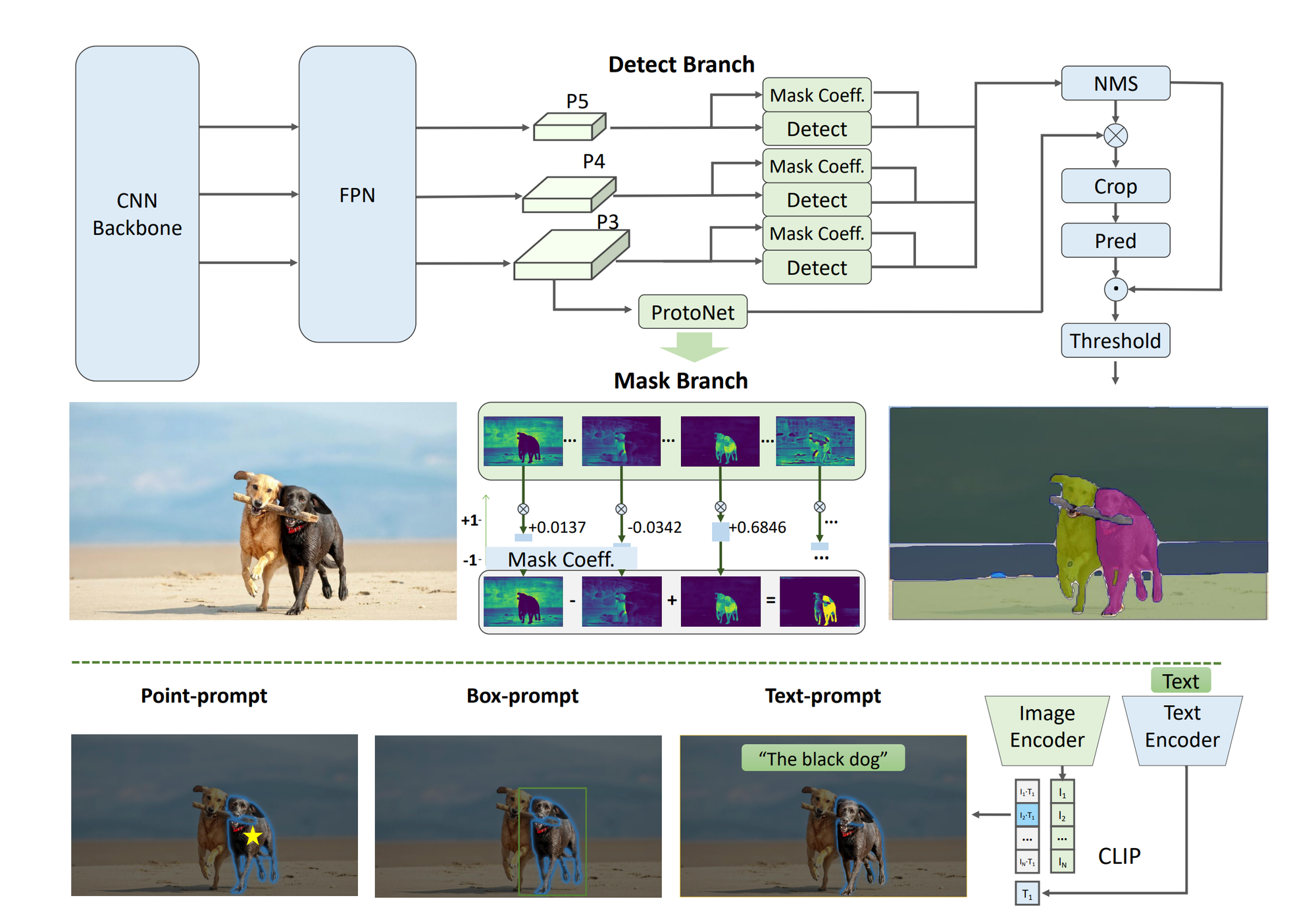
All-instance Segmentation
The output contains of the detection and segmentation branches. The detection department of the mannequin produces class labels and bounding bins, whereas the segmentation department generates ok prototypes (defaulted to 32 in FastSAM) together with corresponding masks coefficients. Each segmentation and detection duties are executed concurrently. The segmentation department takes a high-resolution function map, sustaining spatial particulars and semantic info. After processing via convolution layers, upscaling, and extra convolution layers, it outputs the masks. Masks coefficients, just like the detection department’s classification department, vary from -1 to 1. The ultimate occasion segmentation result’s obtained by multiplying the masks coefficients with the prototypes and summing them up. In FastSAM, YOLOv8-seg technique is used for the all-instance segmentation.

Immediate-guided Choice
With the profitable segmentation of all objects or areas in a picture with YOLOv8, the second stage of the phase something activity includes using totally different prompts to pinpoint the particular object(s) of curiosity.

The purpose immediate technique includes matching chosen factors to masks obtained within the preliminary part, aiming to establish the masks containing the given level.
Within the field immediate technique, Intersection over Union (IoU) matching is carried out between the chosen field and bounding bins related to masks from the preliminary part. The target is to establish the masks with the very best IoU rating relative to the chosen field, successfully selecting the item of curiosity.
Within the case of textual content immediate, the textual content embeddings of the textual content are extracted utilizing the CLIP mannequin. The picture embeddings are individually decided and in comparison with the intrinsic options of every masks utilizing a similarity metric. The masks exhibiting the very best similarity rating to the picture embeddings of the textual content immediate is subsequently chosen.
By fastidiously implementing these strategies, the FastSAM can effectively choose particular objects or areas of curiosity from a segmented picture.
Paperspace Demo
Deliver this undertaking to life
To run this demo on Paperspace we are going to first begin, Paperspace Pocket book with a GPU of your selection. We will use the hyperlink above or on the prime of this text to rapidly open the undertaking up on Paperspace. Please word this hyperlink will spin up a free GPU (M4000). Nevertheless, the Development and Professional plan customers might wish to take into account switching to a extra highly effective machine kind. We will edit the machine selection within the URL the place it says “Free-GPU” by changing that worth with one other GPU code from our machine choice. As soon as the online web page has loaded, click on “Begin Machine” to start launching the Pocket book.
- Clone the repo utilizing the under code:
!git clone https://github.com/CASIA-IVA-Lab/FastSAM.git- As soon as the repo is efficiently cloned use pip to put in the mandatory libraries and set up CLIP:
!pip set up -r FastSAM/necessities.txt
!pip set up git+https://github.com/openai/CLIP.git- Obtain the picture from internet to make use of it for picture segmentation. Please be happy to make use of any picture url.
!wget -P photos https://mediaproxy.salon.com/width/1200/https://media.salon.com/2021/01/cat-and-person-0111211.jpg- Subsequent, traces of code will assist show the picture within the pocket book:
import matplotlib.pyplot as plt
import cv2
picture = cv2.imread('photos/cat-and-person-0111211.jpg')
picture = cv2.cvtColor(picture, cv2.COLOR_BGR2RGB)
original_h = picture.form[0]
original_w = picture.form[1]
print(original_w, original_h)
plt.determine(figsize=(10, 10))
plt.imshow(picture)- Subsequent, run the scripts to attempt the every little thing mode and three immediate modes.
# Every part mode
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./photos/canine.jpg
# Textual content immediate
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./photos/cat-and-person-0111211.jpg --text_prompt "the cat"!# Field immediate(xywh)
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./photos/cat-and-person-0111211.jpg --box_prompt "[[570,200,230,400]]"
# factors immediate
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./photos/cat-and-person-0111211.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
A person interface utilizing Gradio for testing the tactic can be supplied. Customers can add their very own photos, select the mode, regulate parameters, click on the phase button, and obtain a passable segmentation end result.
# gradio demo
!python app_gradio.pyKey Factors
- FastSAM achieves 63.7 at AR1000, that’s 1.2 factors larger than SAM with 32× 32 point-prompt inputs. Can run on shopper graphics playing cards.
- The mannequin has confirmed to be precious for a lot of industrial purposes. This strategy is flexible and relevant throughout quite a few situations. It not solely presents a novel and efficient resolution for varied imaginative and prescient duties however does so at an distinctive velocity, surpassing present strategies by tens or a whole bunch of occasions.
- The mannequin additionally presents a brand new view for the big mannequin structure for the final imaginative and prescient duties.
- FastSAM considerably scale back the computational energy required for SAM whereas sustaining aggressive efficiency. A comparative evaluation throughout varied benchmarks between the FastSAM and SAM presents precious insights into the strengths and weaknesses of every strategy throughout the phase something area.
- This analysis marks the novel exploration of using a CNN detector for the phase something activity, offering precious insights into the capabilities of light-weight CNN fashions in dealing with intricate imaginative and prescient duties.
- FastSAM outperforms SAM throughout all immediate numbers, and notably, the operating velocity of FastSAM stays constant whatever the variety of prompts. This attribute makes it a preferable selection, particularly for the Every part mode.
Concluding Ideas
This text assesses FastSAM’s efficiency in object segmentation, presenting visualizations of its segmentation utilizing point-prompt, box-prompt, and every little thing modes. We strongly encourage our readers to seek advice from the analysis paper for an in depth examination of the comparability between FastSAM and SAM.
FastSAM successfully segments objects utilizing textual content prompts, however the text-to-mask segmentation velocity is unsatisfactory because of the must enter every masks area into the CLIP function extractor, as talked about within the analysis paper. Integrating the CLIP embedding extractor into FastSAM’s spine community continues to be a difficult activity associated to mannequin compression. There are nonetheless some drawbacks with FastSAM which will be improved additional.
However, FastSAM has confirmed to attain comparable efficiency with SAM, making it a tremendous selection for real-world purposes. We suggest our readers to do that mannequin on Paperspace platform and discover extra.
Thanks for studying, we hope you benefit from the mannequin with Paperspace!