
{kind=link}
- This text supplies a complete information on the important ideas, methodologies, and finest practices for implementing generative AI options in large-scale enterprise environments.
- It covers key elements of Gen AI structure, resembling vector databases, embeddings, and immediate engineering, providing sensible insights into their real-world purposes.
- The article explores immediate engineering strategies intimately, discussing optimize prompts for efficient generative AI options.
- It introduces Retrieval Augmented Technology (RAG), explaining decouple information ingestion from information retrieval to boost system efficiency.
- A sensible instance utilizing Python code is included, demonstrating implement RAG with LangChain, Chroma Database, and OpenAI API integration, offering hands-on steerage for builders.
Final yr, we noticed OpenAI revolutionize the know-how panorama by introducing ChatGPT to shoppers globally. This instrument shortly acquired a big consumer base inside a brief interval, surpassing even common social media platforms. Powered by Generative AI, a type of deep studying know-how, ChatGPT impacts shoppers and can be being adopted by many enterprises to focus on potential enterprise use circumstances that have been beforehand thought of not possible challenges.
Overview of Generative AI in Enterprise –
A current survey carried out by BCG with 1406 CXOs globally revealed that Generative AI is among the many prime three applied sciences (after Cybersecurity and Cloud Computing) that 89% of them are contemplating investing in for 2024. Enterprises of all sizes are both constructing their in-house Gen-AI merchandise or investing so as to add the Gen-AI line of product to their enterprise asset listing from exterior suppliers.
With the huge development of Gen-AI adoption in enterprise settings, it’s essential {that a} well-architected reference structure helps the engineering staff and the architects establish roadmaps and constructing blocks for constructing safe and compliant Gen-AI options. These options not solely drive innovation but in addition elevate stakeholder satisfaction.
Earlier than we deep dive, we have to perceive what’s Generative AI? To grasp Generative AI, we first want to know the panorama it operates in. The panorama begins with Synthetic Intelligence (AI) which refers back to the self-discipline of pc techniques that tries to emulate human conduct and carry out duties with out specific programming. Machine Studying (ML) is part of AI that operates on an enormous dataset of historic information and makes predictions primarily based on the patterns it has recognized on that information. For instance, ML can predict when folks favor staying within the resorts vs staying within the rental properties by way of AirBNB throughout particular seasons, primarily based on the previous information. Deep Studying is a sort of ML that contributes towards the cognitive capabilities of computer systems through the use of synthetic deep neural networks, much like the human mind. It includes layers of knowledge processing the place every layer refines the output from the earlier one, finally producing predictive content material. Generative AI is the subset of Deep Studying strategies that makes use of numerous machine studying algorithms and synthetic neural networks to generate new content material, resembling textual content, audio, video, or pictures, with out human intervention primarily based on the information it has acquired throughout coaching..
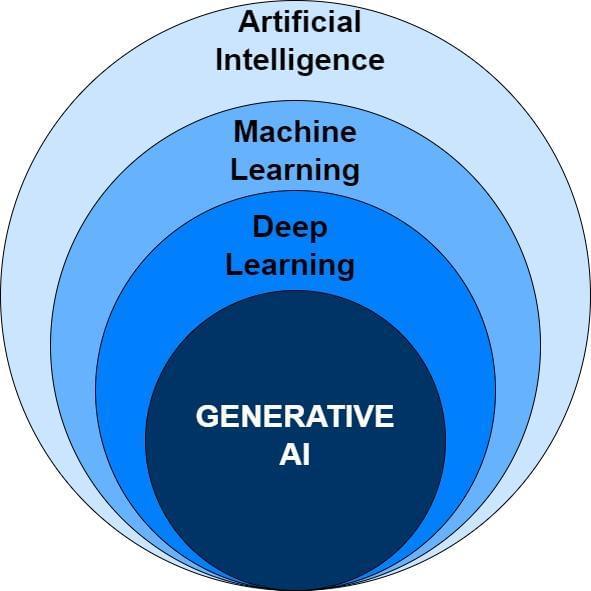
Significance of Safe and Compliant Gen-AI options –
As Gen-AI turns into the rising know-how, an increasing number of of the enterprises throughout all of the industries are dashing to undertake the know-how and never paying sufficient consideration to the need of practising to comply with Accountable AI, Explainable AI and the compliance and safety aspect of the options. Due to that we’re seeing buyer privateness points or biases within the generated content material. This fast improve of GEN-AI adoption requires a gradual & regular strategy as a result of with nice energy comes better duty. Earlier than we additional discover this space I would love share couple of examples to point out why
Organizations should architect the GEN-AI primarily based techniques responsibly with compliance in thoughts, or they’ll danger shedding public belief on their model worth. Organizations must comply with a considerate and complete strategy whereas developing, implementing, and recurrently enhancing the Gen-AI techniques in addition to governing their operation and the content material being produced.
Frequent Purposes and Advantages of Generative AI in Enterprise settings
Know-how centered organizations can make the most of the actual energy of Gen-AI in software program improvement by enhancing productiveness and code high quality. Gen-AI powered autocompletion and code suggestion options assist builders and engineers in writing code extra effectively, whereas code documentation and era from pure language feedback in any language can streamline the event course of. Tech leads can save important improvement effort by using Gen-AI to do repetitive guide peer overview, bug fixing and code high quality enchancment. This results in quicker improvement and launch cycles and higher-quality software program. Additionally, conversational AI for software program engineering helps allow pure language interactions,which improves the collaboration and communication amongst staff members. Product managers and house owners can use Generative AI to handle the product life cycles, ideation, product roadmap planning in addition to consumer story creation and writing top quality acceptance criterias.
Content material summarization is one other space the place Generative AI is the dominating AI know-how in use. It might probably robotically summarize significant product evaluations, articles, long-form stories, assembly transcripts, and emails, saving effort and time of the analysts. Generative AI additionally helps in making knowledgeable selections and figuring out developments by constructing a information graph primarily based on the extracted key insights from unstructured textual content and information.
In buyer help, Generative AI powers digital chatbots that present customized help to clients, which reinforces the general consumer expertise. For instance within the healthcare business for a affected person going through software the chatbots may be extra affected person oriented by offering empathetic solutions. This might assist the group to achieve extra buyer satisfaction. Enterprise clever serps leverage Generative AI to ship related data shortly and precisely. Advice techniques powered by Generative AI analyze the consumer behaviors to supply custom-made solutions that improves buyer engagement and satisfaction. Additionally, Generative AI allows end-to-end contact middle experiences, automating workflows and lowering operational prices. The dwell brokers can use the summarization functionality to know the method or procedures shortly and may information their clients shortly.
Generative AI has additionally made important developments in content material help. It might probably assist generate product descriptions, key phrases and metadata for e-commerce platforms, create participating advertising content material, and help with content material writing duties. It might probably additionally produce pictures for advertising and branding functions through the use of pure language processing (NLP) to know and interpret consumer necessities.
Within the space of information analysis and information mining, Generative AI is used for domain-specific analysis, buyer sentiment evaluation, development evaluation, and producing cross-functional insights. It additionally performs a vital function in fraud detection, leveraging its potential to research huge quantities of knowledge and detect patterns which point out fraudulent exercise.
So we will see that Generative AI is revolutionizing industries by enabling clever automation and enhancing decision-making processes. Its various purposes throughout software program improvement, summarization, conversational AI, content material help, and information analysis exhibits its true potential within the enterprise panorama. If a enterprise can undertake Generative AI shortly, they’re on the trail to achieve a aggressive edge and drive innovation of their respective industries.
As this may be seen that Generative AI has been bringing important enterprise worth to any group by uplifting the shopper experiences of the merchandise or bettering the productiveness of the workforce. Enterprises who’re within the path of adopting the Gen-AI options are discovering actual potential for creating new enterprise processes to drive improvements. The Co-Pilot function of Gen-AI merchandise or Brokers have the power to do a series of thought course of to make selections primarily based on the exterior information resembling outcomes from API or providers to finish choice making duties. There are quite a few purposes throughout industries.
The under diagram exhibits a few of the capabilities that may be doable utilizing Gen-AI at scale.
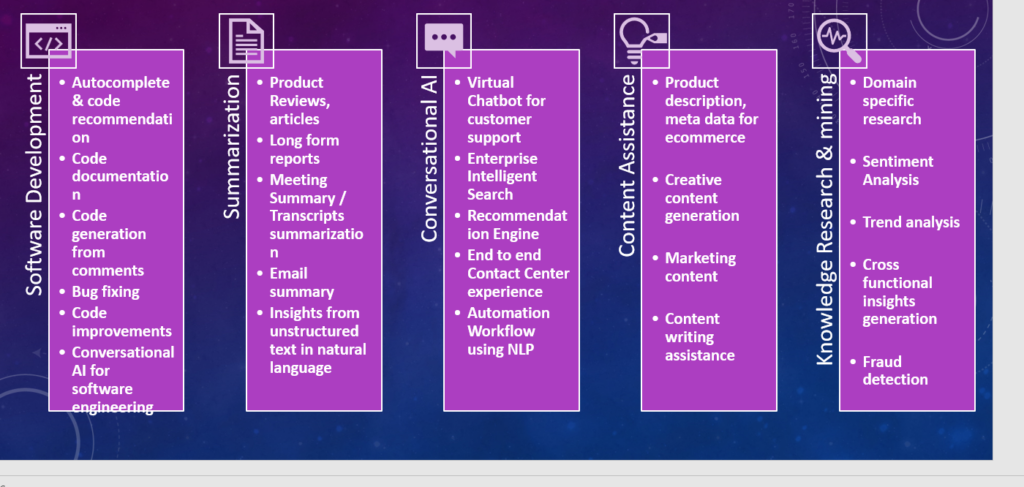
The core elements of enterprise structure for Generative AI have many alternative constructing blocks. On this part we’ll shortly contact a few of the elements resembling Vector Database, Immediate Engineering, and Massive Language Mannequin (LLM). Within the AI or Machine Studying world information is represented in a multidimensional numeric format which is named Embedding or Vector. The Vector Database is essential for storing and retrieving vectors representing numerous elements of knowledge, enabling environment friendly processing and evaluation. Immediate Engineering focuses on designing efficient prompts to information the AI mannequin’s output, making certain related and correct responses from the LLM. Massive Language Fashions function the spine of Generative AI that makes use of numerous algorithms (Transformer or GAN and many others) and pre-training huge datasets to generate advanced and coherent digital content material within the type of texts or audio or movies. These elements work collectively to scale the efficiency and performance of Generative AI options in enterprise settings. We’ll discover extra within the following sections.
Vector Database –
You probably have a Knowledge Science or Machine Studying background or beforehand labored with ML techniques, you probably find out about embeddings or vectors. In easy phrases, embeddings are used to find out the similarity or closeness between totally different entities or information, whether or not they’re texts, phrases, graphics, digital belongings, or any items of data. With the intention to make the machine perceive the assorted contents it’s transformed into the numerical format. This numerical illustration is calculated by one other deep studying mannequin which determines the size of that content material.
Following part exhibits typical embeddings generated by the “text-embedding-ada-002-v2” mannequin for the enter textual content “Solutioning with Generative AI ” which has the dimension of 1536.
| “object”: “listing”, “information”: [ { “object”: “embedding”, “index”: 0, “embedding”: [ -0.01426721, -0.01622797, -0.015700348, 0.015172725, -0.012727121, 0.01788214, -0.05147889, 0.022473885, 0.02689451, 0.016898194, 0.0067129326, 0.008470487, 0.0025008614, 0.025825003, . . <so many>… . 0.032398902, -0.01439555, -0.031229576, -0.018823305, 0.009953735, -0.017967701, -0.00446697, -0.020748416 ] } ], “mannequin”: “text-embedding-ada-002-v2”, “utilization”: { “prompt_tokens”: 6, “total_tokens”: 6 } }{ |
Conventional databases encounter challenges whereas storing vector information with excessive dimensions alongside different information varieties although there are some exceptions which we’ll talk about subsequent. These databases additionally wrestle with scalability points. Additionally, they solely return outcomes when the enter question precisely matches with the saved textual content within the index. To beat these challenges, a cutting-edge database idea has emerged which is able to effectively storing these excessive dimensional vector information. This progressive resolution makes use of algorithms resembling Ok-th Nearest Neighbor (Ok-NN) or Approximate Nearest Neighbor (A-NN) to index and retrieve associated information, optimizing for the shortest distances. These vanilla vector databases preserve indexes of the related and linked information whereas storing and thus successfully scale if the demand from the appliance will get greater.
The idea of vector databases and embeddings performs a vital function in designing and growing Enterprise Generative AI purposes. For instance in QnA use circumstances within the present non-public information or constructing chatbots Vector database supplies contextual reminiscence help to LLMs. For constructing Enterprise search or suggestion system vector databases are used because it comes with the highly effective semantic search capabilities.
There are two main varieties of vector database implementations out there for the engineering staff whereas constructing their subsequent AI purposes: pure vanilla vector databases and built-in vector databases inside a NoSQL or relational database.
Pure Vanilla Vector Database: A pure vector database is particularly designed to effectively retailer and handle vector embeddings, together with a small quantity of metadata. It operates independently from the information supply that generates the embeddings which implies you need to use any sort of deep studying fashions to generate Embedding with totally different dimensions however nonetheless can effectively retailer them within the database with none further modifications or tweaks to the vectors. Open supply merchandise resembling Weaviate, Milvus, Chroma database are pure vector databases. In style SAAS primarily based vector database Pinecone can be a preferred selection among the many developer group whereas constructing AI purposes like Enterprise search, suggestion system or fraud detection system.
Built-in Vector database: Alternatively, an built-in vector database inside a extremely performing NoSQL or relational database gives further functionalities. This built-in strategy permits for the storage, indexing, and querying of embeddings alongside the unique information. By integrating the vector database performance and semantic search functionality inside the present database infrastructure, there isn’t any must duplicate information in a separate pure vector database. This integration additionally facilitates multi-modal information operations and ensures better information consistency, scalability, and efficiency. Nonetheless, this sort of database can solely help comparable vector varieties, having the identical dimension measurement which has been generated by the identical sort of LLM. For instance pgVector extension converts the PostGres database right into a vector database however you may’t retailer vector information having various sizes resembling 512 or 1536 collectively. Redis Enterprise model comes with Vector search enabled which converts the Redis noSQL database right into a vector database succesful. Current model of MongoDB additionally helps vector search functionality.
Immediate Engineering –
Immediate Engineering is the artwork of crafting concise textual content or phrases following particular tips and ideas. These prompts function directions for Massive Language Fashions (LLMs) to information the LLM to generate correct and related output. The method is necessary as a result of poorly constructed prompts can result in LLMs producing hallucinated or irrelevant responses. Due to this fact, it’s important to rigorously design the prompts to information the mannequin successfully.
The aim of immediate engineering is to make sure that the enter given to the LLM is evident, related, and contextually acceptable. By following the ideas of immediate engineering, builders can maximize the LLM’s potential and enhance its efficiency. For instance, if the intention is to generate a abstract of an extended textual content, the immediate needs to be formulated to instruct the LLM to condense the data right into a concise and coherent abstract.
Additionally, immediate engineering helps to allow the LLM to reveal numerous capabilities primarily based on the enter phrases’ intent. These capabilities embody summarizing in depth texts, clarifying matters, reworking enter texts, or increasing on offered data. By offering well-structured prompts, builders can improve the LLM’s potential to know and reply to advanced queries and requests precisely.
A typical construction of any well-constructed immediate can have the next constructing blocks to make sure it supplies sufficient context, time to suppose for the mannequin to generate high quality output –
| Instruction & Duties | Context & Examples | Position (Elective) | Tone (Elective) | Boundaries (Elective) | Output Format (Elective) |
| Present clear instruction and specify the duties the LLM is meant to finish | Present the enter context and exterior data in order that the mannequin can carry out the duties. | If the LLM must comply with a particular function to finish a job, it must be talked about. | Point out the model of writing e.g. you may ask the LLM to generate the response in skilled english. | Remind the mannequin of the guardrails and the constraints to examine whereas producing the output. | If we would like the LLM to generate the output in a particular format. E.g. json or xml and many others. the immediate ought to have that talked about. |
In abstract, immediate engineering performs an important function to make sure that LLMs generate significant and contextually acceptable output for the duties it’s speculated to do. By following the ideas of immediate engineering, builders can enhance the effectiveness and effectivity of LLMs in a variety of purposes, from summarizing textual content to offering detailed explanations and insights.
There are numerous Immediate Engineering strategies or patterns out there which may be utilized whereas growing the Gen-AI resolution. These patterns or the superior strategies shorten the event effort by the engineering staff and streamline the reliability and efficiency –
- Zero-shot prompting – Zero-shot prompting refers to the kind of prompts which asks the mannequin to carry out some duties nevertheless it doesn’t present any examples. The mannequin will generate the content material primarily based on the earlier coaching. It’s utilized in simplex straight ahead NLP duties. E.g. sending automated electronic mail reply, easy textual content summarization.
- Few-Shot prompting – In just a few pictures immediate sample, a number of examples are offered within the enter context to the LLM and a transparent instruction in order that the mannequin can be taught from the examples and generate the kind of responses primarily based on the samples offered. This immediate sample is used when the duty is a fancy one and zero-shot immediate fails to supply the required outcomes.
- Chain-Of-Thought – Chain-of-thought (CoT) immediate sample is appropriate in use circumstances the place we want the LLM to reveal the advanced reasoning capabilities. On this strategy the mannequin exhibits its step-by-step thought course of earlier than offering the ultimate reply. This strategy may be mixed with few-shot prompting, the place just a few examples are offered to information the mannequin, with a purpose to obtain higher outcomes on difficult duties that require reasoning earlier than responding.
- ReAct – On this sample, LLMs are offered entry to the exterior instruments or system. LLMs entry these instruments to fetch the information it must carry out the duty it’s anticipated to do primarily based on the reasoning capabilities. ReAct is used within the use case the place we want the LLM to generate the sequential thought course of and primarily based on that course of retrieves the information it wants by accessing the exterior supply and generates the ultimate extra dependable and factual response. ReAct sample is utilized along with the Chain-Of-Thought immediate sample the place LLMs are wanted for extra choice making duties.
- Tree of ideas prompting – Within the tree of thought sample, LLM makes use of a humanlike strategy to resolve a fancy job utilizing reasoning. It evaluates totally different branches of thought-process after which compares the outcomes to choose the optimum resolution.
LLM Ops –
LLMOps because the identify mentioned refers back to the Operational platform the place the Massive Language Mannequin (one other time period could be Foundational Mannequin) is accessible and the inference is uncovered by way of API sample for the appliance to work together with the AI or the cognitive a part of your entire workflow. LLMOps is depicted as one other core constructing block for any Gen-AI software. That is the collaborative surroundings the place the information scientists, engineering staff and product staff collaboratively construct, practice, deploy machine studying fashions and preserve the information pipeline and the mannequin turns into out there to be built-in with different software layers.
There are three totally different approaches the LLMOps platform may be setup for any enterprise:
- Closed Mannequin gallery: Within the Closed fashions gallery the LLM choices are tightly ruled by large AI suppliers like Microsoft, Google, OpenAI, Anthropic or StableDiffusion and many others.. These tech giants are accountable for their very own mannequin coaching and upkeep. They handle the infrastructure in addition to structure of the fashions and likewise the scalability necessities of operating your entire LLMOps techniques. The fashions can be found by way of API patterns the place the appliance staff creates the API keys and integrates the fashions for inference into the purposes. The advantages of this type of GenAI Ops is that the enterprises want to not fear about sustaining any type of infrastructure, scaling the platform when demand will increase, upgrading the fashions or evaluating the mannequin’s conduct. Nonetheless, within the closed mannequin approaches the enterprises are utterly depending on these tech giants and don’t have any controls on the sort and high quality of knowledge that are getting used to coach or improve the coaching of the LLMs, typically the fashions may expertise price limiting components when the infrastructure sees large surge in demand.
- Open Supply Fashions Gallery: On this strategy you construct your individual mannequin gallery by using the Massive Language fashions managed by the Open Supply group by way of HugginFace or kaggle. On this strategy enterprises are accountable to handle your entire AI infrastructure both on premise or on cloud. They should provision the open supply fashions and as soon as deployed efficiently the mannequin’s inferences are uncovered by way of API for different Enterprise elements to combine into their very own purposes. The mannequin’s inner structure, parameter sizes, deployment methodologies and the pre-training information set are made publicly out there for personalisation by the Open supply group and thus enterprises have full management over the entry, imposing moderation layer and management the authorization, however on the similar time the entire price of possession additionally will increase.
- Hybrid strategy: These days Hybrid strategy is sort of common and main cloud
corporations like AWS or Azure and GCP are dominating this house by offering serverless galleries the place any group can both deploy Open Supply fashions from the out there repository or use the shut fashions of those corporations. Amazon Bedrock and Google Vertex are common hybrid Gen-AI platforms the place both you are able to do BYOM (Carry Your Personal Mannequin) or use the closed mannequin resembling Amazon Titan by way of bedrock console or Google Gemini by way of Vertex. Hybrid strategy supplies flexibility for the enterprises to have controls on the entry and on the similar time it will possibly make the most of top quality open supply mannequin entry in the fee efficient manner by operating the into the shared infrastructure.
RAG is a well-liked framework for constructing Generative AI purposes within the Enterprise world. In many of the use circumstances we explored above has one factor in widespread. Generally the big language mannequin wants entry to exterior information resembling group’s non-public enterprise information or articles on enterprise processes and procedures or for software program improvement entry to the supply code. As you realize, the Massive Language Fashions are skilled with publicly out there scrapped information from the web. So if any query is requested about any group’s non-public information it received’t have the ability to reply and can exhibit hallucination. Hallucination occurs with a Massive Language Mannequin when it doesn’t know the reply of any question or the enter context and the instruction is just not clear. In that situation it tends to generate invalid and irrelevant responses.
RAG because the identify suggests tries to resolve this concern by serving to the LLM entry the exterior information and information. The varied elements powering the RAG framework are –
Retrieval – The principle goal on this exercise is to fetch probably the most related and comparable content material or chunk from the vector database primarily based on the enter question.
Augmented – On this exercise a nicely constructed immediate is created in order that when the decision is made to the LLM, it is aware of precisely what output it must generate, and what’s the enter context.
Generation – That is the world when LLM comes into play. When the mannequin is supplied with good and sufficient context (offered by “retrieval”) and has clear steps outlined (offered by the “Augmented” step) , it should generate a excessive worth response for the consumer.
We’ve got decoupled the information ingestion part with the retrieval half with a purpose to make the structure extra scalable, nevertheless one can mix each the information ingestion and the retrieval collectively to be used circumstances having low quantity of knowledge.
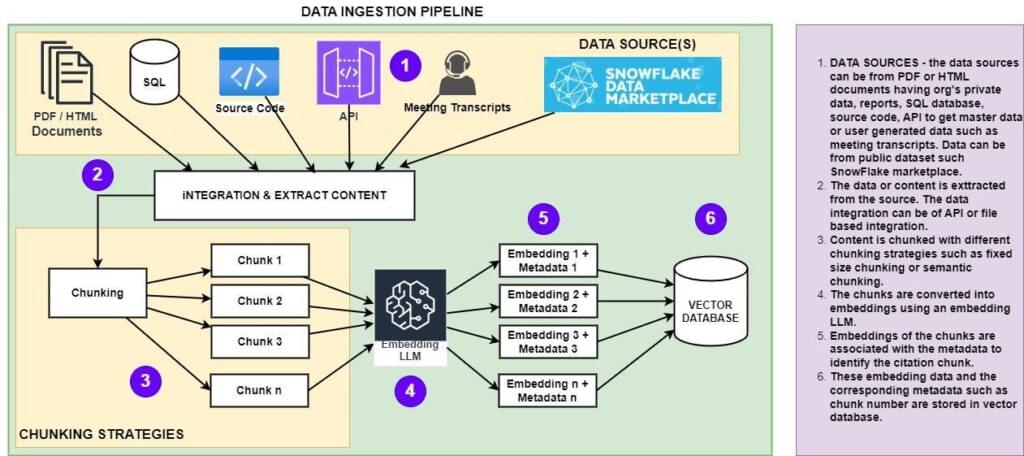
Knowledge Ingestion workflow-
On this workflow, the contents from the assorted information sources resembling PDF stories, HTML articles or any transcripts information from dialog are chunked utilizing acceptable chunking methods e.g. mounted measurement chunking or context conscious chunking. As soon as chunked the cut up contents are used to generate embeddings by invoking the suitable LLMOps your Enterprise has arrange – it may be a closed mannequin offering entry by way of API or open supply mannequin operating in your individual infrastructure. As soon as the embedding is generated it will get saved in a vector database for being consumed by the appliance operating within the retrieval part.
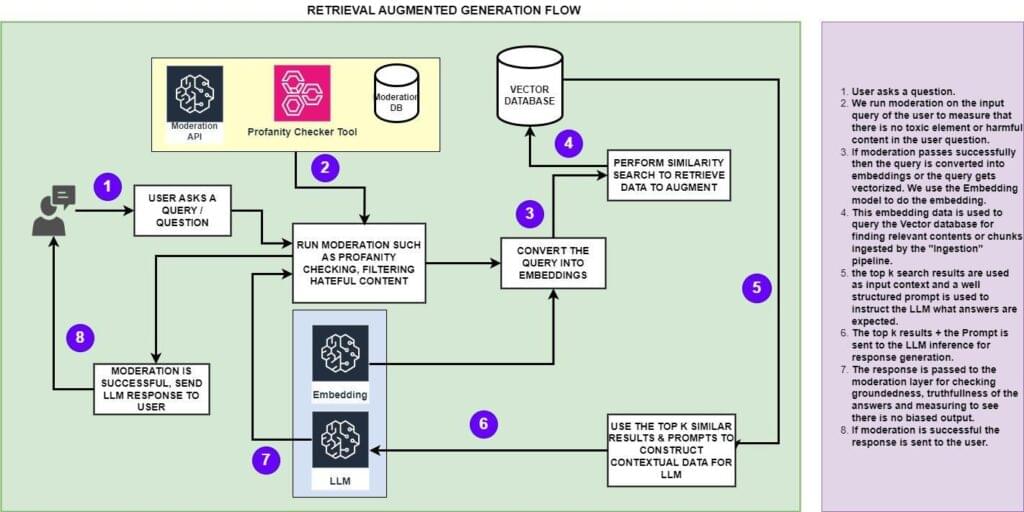
Knowledge Retrieval workflow-
Within the information retrieval workflow, the consumer question is checked for profanity and different moderation to make sure it is freed from any poisonous information or unbiased content material. The moderation layer additionally checks to make sure the question doesn’t have any delicate or non-public information as nicely. As soon as it passes the moderation layer, it’s transformed into embedding by invoking the embedding LLM. As soon as a query is transformed into embedding, that is used to do similarity search within the vector database to establish comparable contents. The unique texts in addition to the transformed embedding are used for locating the same paperwork from the vector database.
The highest-k outcomes are used to assemble a well-defined immediate utilizing the immediate engineering and that is fed to the totally different LLM mannequin (typically the instruct mannequin) to generate significant responses for the consumer. The generated response is once more handed by way of the moderation layer to make sure it doesn’t comprise any hallucinated content material or biased reply and likewise free from any hateful information or any non-public information. As soon as the moderation is glad, the response is shared with the consumer.
RAG Challenges and Options –
RAG framework stands out as probably the most price efficient solution to shortly construct and combine any Gen-AI capabilities to the enterprise structure. It’s built-in with an information pipeline so there isn’t any want to coach the fashions with exterior content material that modifications often. To be used circumstances the place the exterior information or content material is dynamic, RAG is extraordinarily efficient for ingesting and augmenting the information to the mannequin. Coaching a mannequin with often altering information is extraordinarily costly and needs to be prevented. These are the highest explanation why RAG has develop into so common among the many improvement group. The 2 common gen-ai python frameworks LLamaIndex and LangChain present out-of-the-box options for Gen-AI improvement utilizing RAG approaches.
Nonetheless, the RAG framework comes with its personal set of challenges and points that needs to be addressed early within the improvement part in order that the responses we get will likely be of top of the range.
- Chunking Difficulty: Chunking performs a greatest function for the RAG system to generate efficient responses. When giant paperwork are chunked , typically mounted measurement chunking patterns are used the place paperwork are splitted or chunked with a hard and fast phrase measurement or character measurement restrict. This creates points when a significant sentence is chunked within the flawed manner and we find yourself having two chunks containing two totally different sentences of two totally different meanings. When these sorts of chunks are transformed into embeddings and fed to the vector database, it loses the semantic that means and thus through the retrieval course of it fails to generate efficient responses. To beat this a correct chunking technique must be used. In some eventualities, as a substitute of utilizing Fastened measurement chunking it’s higher to make use of context conscious chunking or semantic chunking in order that the internal that means of a big corpus of paperwork is preserved.
- Retrieval Difficulty: The efficiency of RAG fashions depends closely on the standard of the retrieved contextual paperwork from the vector database. When the retriever fails to find related, appropriate passages, it considerably limits the mannequin’s potential to generate exact, detailed responses. In some conditions the retrievers fetch blended content material having related paperwork together with the irrelevant paperwork and this blended outcomes trigger difficulties for the LLM to generate correct content material because it fails to establish the irrelevant information when it will get blended with the related content material. To beat this concern, we typically make use of custom-made options resembling updating the metadata with a summarized model of the chunk that will get saved together with the embedding content material. One other common strategy is to make use of the RA-FT (Retrieval Augmented with Effective Tune) methodology the place the mannequin is okay tuned in such a manner that is ready to establish the irrelevant content material when it will get blended with the related content material.
- Misplaced within the center drawback: This concern occurs when LLMs are introduced with an excessive amount of data because the enter context and never all are related data. Even premium LLMs resembling “Claude 3” or “GPT 4” which have large context home windows, wrestle when it will get overwhelmed with an excessive amount of data and many of the information is just not related to the instruction offered by the immediate engineering. Due to overwhelming giant enter information the LLM couldn’t generate correct responses. The efficiency and high quality of the output degrades if the related data is just not at first of the enter context. This basic and examined drawback is taken into account one of many ache factors of RAG and it requires the engineering staff to rigorously assemble each the immediate engineering in addition to re-ranking the retrieved contents in order that the related contents at all times keep at first for the LLM to supply top quality content material.
As you may see, although RAG is probably the most price efficient and fast to construct framework for designing and constructing Gen-AI purposes, it additionally suffers quite a lot of points whereas producing top quality responses or finest outcomes. The standard of the LLM response may be enormously improved by re-ranking the retrieved outcomes from vector databases, attaching summarized contents or metadata to paperwork for producing higher semantic search, and experimenting with totally different embedding fashions having totally different dimensions. Along with these superior strategies and integrating some hybrid approaches like RA-FT the efficiency of RAG could be enhanced.
A pattern RAG Implementation utilizing Langchain
On this part we’ll deep dive in constructing a small RAG primarily based software utilizing Langchain, Chrima database and Open AI’s API. We will likely be utilizing the Chroma Database as our in-memory Vector database which is a light-weight database for constructing MVP (Minimal Viable Product) or POC (Proof Of Idea) to expertise the idea. ChromaDB continues to be not really helpful for constructing manufacturing grade apps.
I typically use the Google Collab for operating any python code shortly. Be at liberty to make use of the identical or strive the next code in your favourite python IDE..
Step 1: Set up the python libraries / modules
| !pip set up langchain !pip set up langchain-community langchain-core !pip set up -U langchain-openai !pip set up langchain-chroma |
- The OpenAI API is a service that enables builders to entry and use OpenAI’s giant language fashions (LLMs) in their very own purposes.
- LangChain is an open-source framework that makes it simpler for builders to construct LLM purposes.
- ChromaDB is an open-source vector database particularly designed to retailer and handle vector representations of textual content information.
- Take away the “!” from pip statements if you’re straight operating the code out of your command immediate.
Step 2: Import the required objects
| # Import needed modules for textual content processing, mannequin interplay, and database administration from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.chains import RetrievalQA from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_chroma import Chroma import chromadb import pprint # Description of module utilization: |
Step 3: Knowledge Ingestion
| input_texts = [ “Artificial Intelligence (AI) is transforming industries around the world.”, “AI enables machines to learn from experience and perform human-like tasks.”, “In healthcare, AI algorithms can help diagnose diseases with high accuracy.”, “Self-driving cars use AI to navigate streets and avoid obstacles.”, “AI-powered chatbots provide customer support and enhance user experience.”, “Predictive analytics driven by AI helps businesses forecast trends and make data-driven decisions.”, “AI is also revolutionizing the field of finance through automated trading and fraud detection.”, “Natural language processing (NLP) allows AI to understand and respond to human language.”, “In manufacturing, AI systems improve efficiency and quality control.”, “AI is used in agriculture to optimize crop yields and monitor soil health.”, “Education is being enhanced by AI through personalized learning and intelligent tutoring systems.”, “AI-driven robotics perform tasks that are dangerous or monotonous for humans.”, “AI assists in climate modeling and environmental monitoring to combat climate change.”, “Entertainment industries use AI for content creation and recommendation systems.”, “AI technologies are fundamental to the development of smart cities.”, “The integration of AI in supply chain management enhances logistics and inventory control.”, “AI research continues to push boundaries in machine learning and deep learning.”, “Ethical considerations are crucial in AI development to ensure fairness and transparency.”, “AI in cybersecurity helps detect and respond to threats in real-time.”, “The future of AI holds potential for even greater advancements and applications across various fields.” ] # Mix all components within the listing right into a single string with newline because the separator # Carry out “RecursiveCharacterTextSplitter” in order that the information can have an object “page_content” chunk_texts = text_splitter.create_documents([combined_text]) |
Step 4: Generate Embedding and retailer within the Chroma Database
| # Initialize the embeddings API with the OpenAI API keyopenai_api_key = “sk-proj-REKM9ueLh5ozQF533c2sT3BlbkFJJTUfxT2nm113b28LztjD” embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key) # Listing to persist the Chroma database # Save the paperwork and embeddings to the native Chroma database # Load the Chroma database from the native listing # Testing the setup with a pattern question # Print the retrieved paperwork |
Step 5: Now we’ll do the immediate engineering to instruct the LLM what to generate primarily based on the context we provide.
| # Outline the template for the immediate template = “”” Position: You’re a Scientist. Enter: Use the next context to reply the query. Context: {context} Query: {query} Steps: Reply politely and say, “I hope you’re nicely,” then concentrate on answering the query. Expectation: Present correct and related solutions primarily based on the context offered. Narrowing: 1. Restrict your responses to the context given. Focus solely on questions on AI. 2. Should you don’t know the reply, simply say, “I’m sorry…I don’t know.” 3. If there are phrases or questions outdoors the context of AI, simply say, “Let’s discuss AI.” Reply: “”” # {context} is information derived from the database vectors which have similarities with the query # Create the immediate template |
Step 6: Configure the LLM inference and do the retrieval
| # Outline the parameter values temperature = 0.2 param = { “top_p”: 0.4, “frequency_penalty”: 0.1, “presence_penalty”: 0.7 } # Create an LLM object with the required parameters # Create a RetrievalQA object with the required parameters and immediate template # Take a look at the setup with a pattern questionquestion = “How does AI remodel the business?” # Print the retrieved paperwork and the response |
Remaining Output –
| [Document(page_content=’Artificial Intelligence (AI) is transforming industries around the world.’), Document(page_content=’nThe future of AI holds potential for even greater advancements and applications across various fields.’), Document(page_content=’nIn manufacturing, AI systems improve efficiency and quality control.’), Document(page_content=’nAI is also revolutionizing the field of finance through automated trading and fraud detection.’)] |
RetrievalQA is a technique for query answering duties that makes use of an index to retrieve related paperwork or textual content snippets, appropriate for easy question-answering purposes. RetrievalQAChain combines Retriever and a QA chain. It’s used to fetch paperwork from the Retriever after which make the most of the QA chain to reply questions primarily based on the retrieved paperwork.
In conclusion, a sturdy reference structure is an important requirement for organizations who’re both within the means of constructing the Gen-AI options or are pondering of constructing step one. This helps to construct the safe and compliant Generative AI options. A well-architected reference structure can assist the engineering groups in navigating the complexities of Generative AI improvement by following the standardized phrases, finest practices, and IT architectural approaches. It hurries up the know-how deployments, improves interoperability, and supplies a strong basis for imposing governance and decision-making processes. Because the demand for Generative AI continues to extend, Enterprises who put money into the event and cling to a complete reference structure will likely be in a greater place to fulfill regulatory necessities, elevate the shopper belief, mitigate dangers, and drive innovation on the forefront of their respective industries.